Detailed program
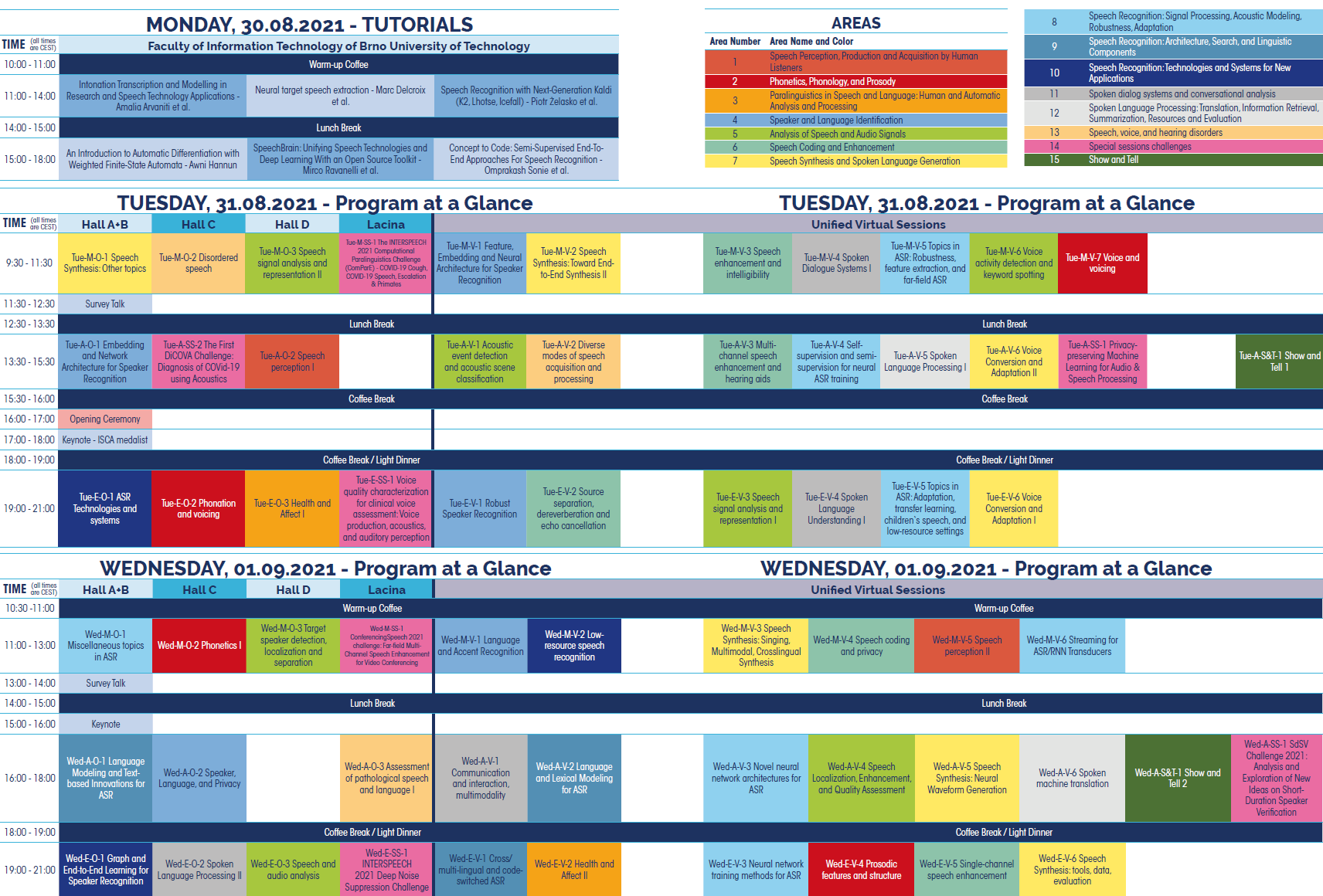
Tuesday, August 31, 09:30-11:30
Tuesday, August 31, 13:30-15:30
Tuesday, August 31, 19:00-21:00
Wednesday, September 1, 11:00-13:00
Wednesday, September 1, 16:00-18:00
Wednesday, September 1, 19:00-21:00
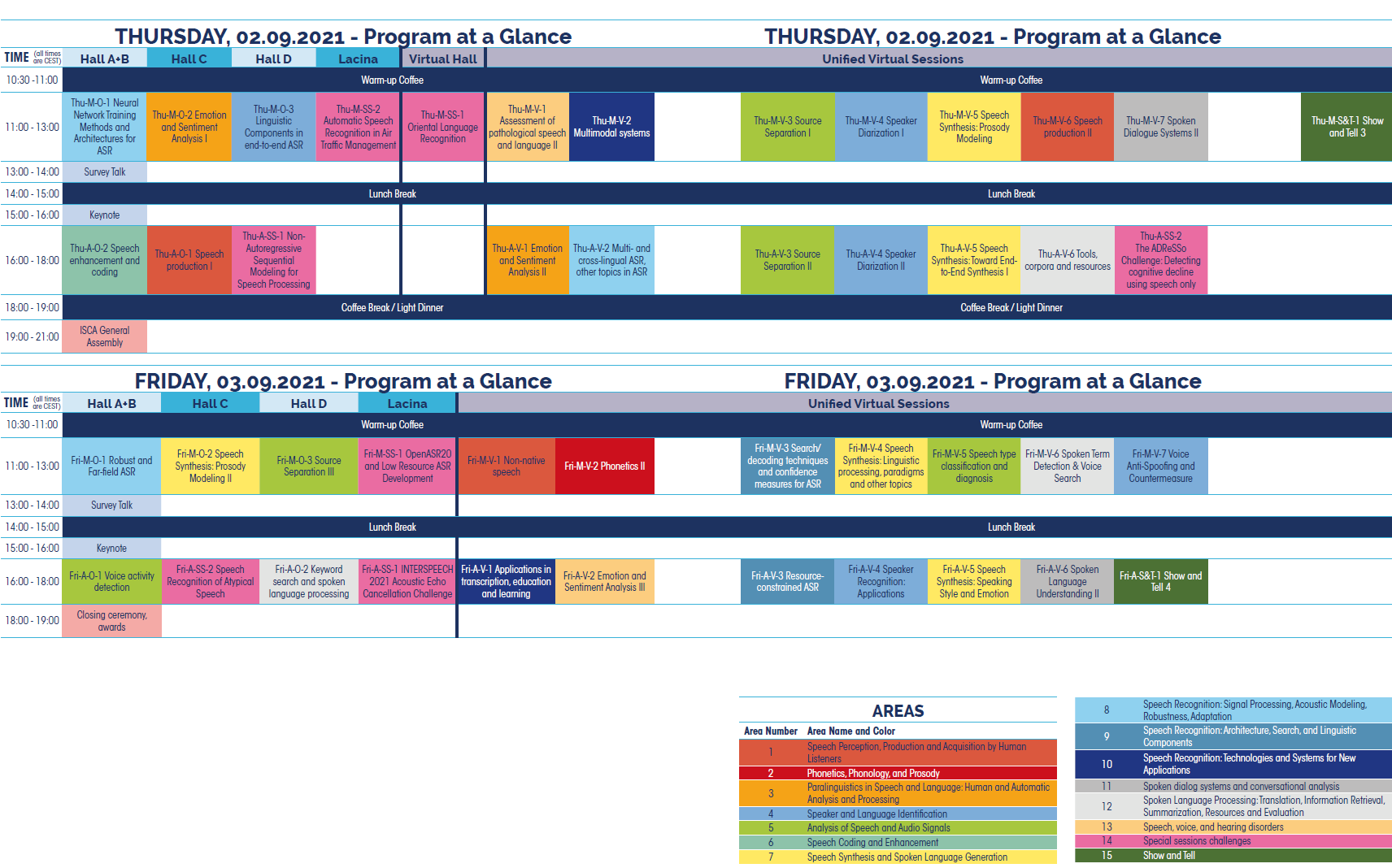
Thursday, September 2, 11:00-13:00
Thursday, September 2, 16:00-18:00
Friday, September 3, 11:00-13:00
Friday, September 3, 16:00-18:00
Tue-M-O-1 Tuesday, August 31, 09:30-11:30 In-person Oral: Speech Synthesis: Other topics
- 09:30 Tue-M-O-1-1 473 Conversion of Airborne to Bone-Conducted Speech with Deep Neural Networks, Michael Pucher (Austrian Academy of Sciences, Austria) and Thomas Woltron (FH Wiener Neustadt, Austria)
- 09:50 Tue-M-O-1-2 546 T5G2P: Using Text-to-Text Transfer Transformer for Grapheme-to-Phoneme Conversion, Markéta Řezáčková (University of West Bohemia, Czech Republic), Jan Švec (University of West Bohemia, Czech Republic) and Daniel Tihelka (University of West Bohemia, Czech Republic)
- 10:10 Tue-M-O-1-3 1547 Evaluating the Extrapolation Capabilities of Neural Vocoders to Extreme Pitch Values, Olivier Perrotin (GIPSA-lab (UMR 5216), France), Hussein El Amouri (GIPSA-lab (UMR 5216), France), Gérard Bailly (GIPSA-lab (UMR 5216), France) and Thomas Hueber (GIPSA-lab (UMR 5216), France)
- 10:30 Tue-M-O-1-4 1565 A Systematic Review and Analysis of Multilingual Data Strategies in Text-to-Speech for Low-Resource Languages, Phat Do (Rijksuniversiteit Groningen, The Netherlands), Matt Coler (Rijksuniversiteit Groningen, The Netherlands), Jelske Dijkstra (Rijksuniversiteit Groningen, The Netherlands) and Esther Klabbers (ReadSpeaker, The Netherlands)
Tue-M-O-2 Tuesday, August 31, 09:30-11:30 In-person Oral: Disordered speech
- 09:30 Tue-M-O-2-1 1581 Acoustic Indicators of Speech Motor Coordination in Adults With and Without Traumatic Brain Injury, Tanya Talkar (Harvard University, USA), Nancy Pearl Solomon (Walter Reed National Military Medical Center, USA), Douglas S. Brungart (Walter Reed National Military Medical Center, USA), Stefanie E. Kuchinsky (Walter Reed National Military Medical Center, USA), Megan M. Eitel (Walter Reed National Military Medical Center, USA), Sara M. Lippa (Walter Reed National Military Medical Center, USA), Tracey A. Brickell (Walter Reed National Military Medical Center, USA), Louis M. French (Walter Reed National Military Medical Center, USA), Rael T. Lange (Walter Reed National Military Medical Center, USA) and Thomas F. Quatieri (Harvard University, USA)
- 09:50 Tue-M-O-2-2 1084 On Modeling Glottal Source Information for Phonation Assessment in Parkinson’s Disease, J.C. Vásquez-Correa (FAU Erlangen-Nürnberg, Germany), Julian Fritsch (Idiap Research Institute, Switzerland), J.R. Orozco-Arroyave (FAU Erlangen-Nürnberg, Germany), Elmar Nöth (FAU Erlangen-Nürnberg, Germany) and Mathew Magimai-Doss (Idiap Research Institute, Switzerland)
- 10:10 Tue-M-O-2-3 223 Distortion of Voiced Obstruents for Differential Diagnosis Between Parkinson’s Disease and Multiple System Atrophy, Khalid Daoudi (Inria, France), Biswajit Das (Inria, France), Solange Milhé de Saint Victor (CHU de Bordeaux, France), Alexandra Foubert-Samier (CHU de Bordeaux, France), Anne Pavy-Le Traon (CHU de Toulouse, France), Olivier Rascol (CHU de Toulouse, France), Wassilios G. Meissner (CHU de Bordeaux, France) and Virginie Woisard (CHU de Toulouse, France)
- 10:30 Tue-M-O-2-4 1720 A Study into Pre-Training Strategies for Spoken Language Understanding on Dysarthric Speech, Pu Wang (KU Leuven, Belgium), Bagher BabaAli (University of Tehran, Iran) and Hugo Van hamme (KU Leuven, Belgium)
- 10:50 Tue-M-O-2-5 549 EasyCall Corpus: A Dysarthric Speech Dataset, Rosanna Turrisi (IIT, Italy), Arianna Braccia (Università di Ferrara, Italy), Marco Emanuele (IIT, Italy), Simone Giulietti (Università di Ferrara, Italy), Maura Pugliatti (Università di Ferrara, Italy), Mariachiara Sensi (Università di Ferrara, Italy), Luciano Fadiga (IIT, Italy) and Leonardo Badino (PerVoice, Italy)
Tue-M-O-3 Tuesday, August 31, 09:30-11:30 In-person Oral: Speech signal analysis and representation II
- 09:30 Tue-M-O-3-1 256 A Benchmark of Dynamical Variational Autoencoders Applied to Speech Spectrogram Modeling, Xiaoyu Bie (LJK (UMR 5224), France), Laurent Girin (GIPSA-lab (UMR 5216), France), Simon Leglaive (IETR (UMR 6164), France), Thomas Hueber (GIPSA-lab (UMR 5216), France) and Xavier Alameda-Pineda (LJK (UMR 5224), France)
- 09:50 Tue-M-O-3-2 645 Fricative Phoneme Detection Using Deep Neural Networks and its Comparison to Traditional Methods, Metehan Yurt (Fraunhofer IIS, Germany), Pavan Kantharaju (Fraunhofer IIS, Germany), Sascha Disch (Fraunhofer IIS, Germany), Andreas Niedermeier (Fraunhofer IIS, Germany), Alberto N. Escalante-B. (WS Audiology, Germany) and Veniamin I. Morgenshtern (FAU Erlangen-Nürnberg, Germany)
- 10:10 Tue-M-O-3-3 1598 Identification of F1 and F2 in Speech Using Modified Zero Frequency Filtering, RaviShankar Prasad (Idiap Research Institute, Switzerland) and Mathew Magimai-Doss (Idiap Research Institute, Switzerland)
- 10:30 Tue-M-O-3-4 1676 Phoneme-to-Audio Alignment with Recurrent Neural Networks for Speaking and Singing Voice, Yann Teytaut (STMS (UMR 9912), France) and Axel Roebel (STMS (UMR 9912), France)
Tue-M-V-1 Tuesday, August 31, 09:30-11:30 Virtual: Feature, Embedding and Neural Architecture for Speaker Recognition
- 09:30 Tue-M-V-1-1 65 Adaptive Convolutional Neural Network for Text-Independent Speaker Recognition, Seong-Hu Kim (KAIST, Korea) and Yong-Hwa Park (KAIST, Korea)
- 09:30 Tue-M-V-1-2 111 Bidirectional Multiscale Feature Aggregation for Speaker Verification, Jiajun Qi (USTC, China), Wu Guo (USTC, China) and Bin Gu (USTC, China)
- 09:30 Tue-M-V-1-3 356 Improving Time Delay Neural Network Based Speaker Recognition with Convolutional Block and Feature Aggregation Methods, Yu-Jia Zhang (National Sun Yat-sen University, Taiwan), Yih-Wen Wang (National Sun Yat-sen University, Taiwan), Chia-Ping Chen (National Sun Yat-sen University, Taiwan), Chung-Li Lu (Chunghwa Telecom Laboratories, Taiwan) and Bo-Cheng Chan (Chunghwa Telecom Laboratories, Taiwan)
- 09:30 Tue-M-V-1-4 559 Improving Deep CNN Architectures with Variable-Length Training Samples for Text-Independent Speaker Verification, Yanfeng Wu (Nankai University, China), Junan Zhao (Nankai University, China), Chenkai Guo (Nankai University, China) and Jing Xu (Nankai University, China)
- 09:30 Tue-M-V-1-5 600 Binary Neural Network for Speaker Verification, Tinglong Zhu (Duke Kunshan University, China), Xiaoyi Qin (Duke Kunshan University, China) and Ming Li (Duke Kunshan University, China)
- 09:30 Tue-M-V-1-6 1436 Mutual Information Enhanced Training for Speaker Embedding, Youzhi Tu (PolyU, China) and Man-Wai Mak (PolyU, China)
- 09:30 Tue-M-V-1-7 1707 Y-Vector: Multiscale Waveform Encoder for Speaker Embedding, Ge Zhu (University of Rochester, USA), Fei Jiang (University of Rochester, USA) and Zhiyao Duan (University of Rochester, USA)
- 09:30 Tue-M-V-1-8 2137 Phoneme-Aware and Channel-Wise Attentive Learning for Text Dependent Speaker Verification, Yan Liu (Xiamen University, China), Zheng Li (Xiamen University, China), Lin Li (Xiamen University, China) and Qingyang Hong (Xiamen University, China)
- 09:30 Tue-M-V-1-9 2210 Serialized Multi-Layer Multi-Head Attention for Neural Speaker Embedding, Hongning Zhu (NUS, Singapore), Kong Aik Lee (A*STAR, Singapore) and Haizhou Li (NUS, Singapore)
Tue-M-V-2 Tuesday, August 31, 09:30-11:30 Virtual: Speech Synthesis: Toward End-to-End Synthesis II
- 09:30 Tue-M-V-2-1 852 TacoLPCNet: Fast and Stable TTS by Conditioning LPCNet on Mel Spectrogram Predictions, Cheng Gong (Tianjin University, China), Longbiao Wang (Tianjin University, China), Ju Zhang (Huiyan Technology, China), Shaotong Guo (Tianjin University, China), Yuguang Wang (Huiyan Technology, China) and Jianwu Dang (Tianjin University, China)
- 09:30 Tue-M-V-2-2 866 FastPitchFormant: Source-Filter Based Decomposed Modeling for Speech Synthesis, Taejun Bak (NCSOFT, Korea), Jae-Sung Bae (NCSOFT, Korea), Hanbin Bae (NCSOFT, Korea), Young-Ik Kim (NCSOFT, Korea) and Hoon-Young Cho (NCSOFT, Korea)
- 09:30 Tue-M-V-2-3 896 Sequence-to-Sequence Learning for Deep Gaussian Process Based Speech Synthesis Using Self-Attention GP Layer, Taiki Nakamura (University of Tokyo, Japan), Tomoki Koriyama (University of Tokyo, Japan) and Hiroshi Saruwatari (University of Tokyo, Japan)
- 09:30 Tue-M-V-2-4 914 Phonetic and Prosodic Information Estimation from Texts for Genuine Japanese End-to-End Text-to-Speech, Naoto Kakegawa (Okayama University, Japan), Sunao Hara (Okayama University, Japan), Masanobu Abe (Okayama University, Japan) and Yusuke Ijima (NTT, Japan)
- 09:30 Tue-M-V-2-5 1011 Information Sieve: Content Leakage Reduction in End-to-End Prosody Transfer for Expressive Speech Synthesis, Xudong Dai (Tianjin University, China), Cheng Gong (Tianjin University, China), Longbiao Wang (Tianjin University, China) and Kaili Zhang (Tianjin University, China)
- 09:30 Tue-M-V-2-6 1405 Deliberation-Based Multi-Pass Speech Synthesis, Qingyun Dou (University of Cambridge, UK), Xixin Wu (University of Cambridge, UK), Moquan Wan (University of Cambridge, UK), Yiting Lu (University of Cambridge, UK) and Mark J.F. Gales (University of Cambridge, UK)
- 09:30 Tue-M-V-2-7 1461 Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling, Isaac Elias (Google, Israel), Heiga Zen (Google, Japan), Jonathan Shen (Google, USA), Yu Zhang (Google, USA), Ye Jia (Google, USA), R.J. Skerry-Ryan (Google, USA) and Yonghui Wu (Google, USA)
- 09:30 Tue-M-V-2-8 1655 Transformer-Based Acoustic Modeling for Streaming Speech Synthesis, Chunyang Wu (Facebook, USA), Zhiping Xiu (Facebook, USA), Yangyang Shi (Facebook, USA), Ozlem Kalinli (Facebook, USA), Christian Fuegen (Facebook, USA), Thilo Koehler (Facebook, USA) and Qing He (Facebook, USA)
- 09:30 Tue-M-V-2-9 1757 PnG BERT: Augmented BERT on Phonemes and Graphemes for Neural TTS, Ye Jia (Google, USA), Heiga Zen (Google, Japan), Jonathan Shen (Google, USA), Yu Zhang (Google, USA) and Yonghui Wu (Google, USA)
- 09:30 Tue-M-V-2-10 2100 Speed up Training with Variable Length Inputs by Efficient Batching Strategies, Zhenhao Ge (Sony, USA), Lakshmish Kaushik (Sony, USA), Masanori Omote (Sony, USA) and Saket Kumar (Sony, USA)
Tue-M-V-3 Tuesday, August 31, 09:30-11:30 Virtual: Speech enhancement and intelligibility
- 09:30 Tue-M-V-3-1 10 Funnel Deep Complex U-Net for Phase-Aware Speech Enhancement, Yuhang Sun (OPPO, China), Linju Yang (OPPO, China), Huifeng Zhu (OPPO, China) and Jie Hao (OPPO, China)
- 09:30 Tue-M-V-3-2 46 Temporal Convolutional Network with Frequency Dimension Adaptive Attention for Speech Enhancement, Qiquan Zhang (NUS, Singapore), Qi Song (Alibaba, China), Aaron Nicolson (CSIRO, Australia), Tian Lan (Alibaba, China) and Haizhou Li (NUS, Singapore)
- 09:30 Tue-M-V-3-3 58 Perceptual Contributions of Vowels and Consonant-Vowel Transitions in Understanding Time-Compressed Mandarin Sentences, Changjie Pan (SUSTech, China), Feng Yang (Shenzhen Second People’s Hospital, China) and Fei Chen (SUSTech, China)
- 09:30 Tue-M-V-3-4 150 Transfer Learning for Speech Intelligibility Improvement in Noisy Environments, Ritujoy Biswas (IIT Jammu, India), Karan Nathwani (IIT Jammu, India) and Vinayak Abrol (IIIT Delhi, India)
- 09:30 Tue-M-V-3-5 174 Comparison of Remote Experiments Using Crowdsourcing and Laboratory Experiments on Speech Intelligibility, Ayako Yamamoto (Wakayama University, Japan), Toshio Irino (Wakayama University, Japan), Kenichi Arai (NTT, Japan), Shoko Araki (NTT, Japan), Atsunori Ogawa (NTT, Japan), Keisuke Kinoshita (NTT, Japan) and Tomohiro Nakatani (NTT, Japan)
- 09:30 Tue-M-V-3-6 238 Know Your Enemy, Know Yourself: A Unified Two-Stage Framework for Speech Enhancement, Wenzhe Liu (CAS, China), Andong Li (CAS, China), Yuxuan Ke (CAS, China), Chengshi Zheng (CAS, China) and Xiaodong Li (CAS, China)
- 09:30 Tue-M-V-3-7 259 Speech Enhancement with Weakly Labelled Data from AudioSet, Qiuqiang Kong (ByteDance, China), Haohe Liu (ByteDance, China), Xingjian Du (ByteDance, China), Li Chen (ByteDance, China), Rui Xia (ByteDance, China) and Yuxuan Wang (ByteDance, China)
- 09:30 Tue-M-V-3-8 582 Improving Perceptual Quality by Phone-Fortified Perceptual Loss Using Wasserstein Distance for Speech Enhancement, Tsun-An Hsieh (Academia Sinica, Taiwan), Cheng Yu (Academia Sinica, Taiwan), Szu-Wei Fu (Academia Sinica, Taiwan), Xugang Lu (NICT, Japan) and Yu Tsao (Academia Sinica, Taiwan)
- 09:30 Tue-M-V-3-9 599 MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement, Szu-Wei Fu (Academia Sinica, Taiwan), Cheng Yu (Academia Sinica, Taiwan), Tsun-An Hsieh (Academia Sinica, Taiwan), Peter Plantinga (Ohio State University, USA), Mirco Ravanelli (Mila, Canada), Xugang Lu (NICT, Japan) and Yu Tsao (Academia Sinica, Taiwan)
- 09:30 Tue-M-V-3-10 605 A Spectro-Temporal Glimpsing Index (STGI) for Speech Intelligibility Prediction, Amin Edraki (Queen’s University, Canada), Wai-Yip Chan (Queen’s University, Canada), Jesper Jensen (Aalborg University, Denmark) and Daniel Fogerty (University of Illinois at Urbana-Champaign, USA)
- 09:30 Tue-M-V-3-11 734 Self-Supervised Learning Based Phone-Fortified Speech Enhancement, Yuanhang Qiu (Massey University, New Zealand), Ruili Wang (Massey University, New Zealand), Satwinder Singh (Massey University, New Zealand), Zhizhong Ma (Massey University, New Zealand) and Feng Hou (Massey University, New Zealand)
- 09:30 Tue-M-V-3-12 1844 Incorporating Embedding Vectors from a Human Mean-Opinion Score Prediction Model for Monaural Speech Enhancement, Khandokar Md. Nayem (Indiana University, USA) and Donald S. Williamson (Indiana University, USA)
- 09:30 Tue-M-V-3-13 1889 Restoring Degraded Speech via a Modified Diffusion Model, Jianwei Zhang (Arizona State University, USA), Suren Jayasuriya (Arizona State University, USA) and Visar Berisha (Arizona State University, USA)
Tue-M-V-4 Tuesday, August 31, 09:30-11:30 Virtual: Spoken Dialogue Systems I
- 09:30 Tue-M-V-4-1 1536 User-Initiated Repetition-Based Recovery in Multi-Utterance Dialogue Systems, Hoang Long Nguyen (Apple, USA), Vincent Renkens (Apple, USA), Joris Pelemans (Apple, USA), Srividya Pranavi Potharaju (Apple, USA), Anil Kumar Nalamalapu (Apple, USA) and Murat Akbacak (Apple, USA)
- 09:30 Tue-M-V-4-2 120 Self-Supervised Dialogue Learning for Spoken Conversational Question Answering, Nuo Chen (Peking University, China), Chenyu You (Yale University, USA) and Yuexian Zou (Peking University, China)
- 09:30 Tue-M-V-4-3 138 Act-Aware Slot-Value Predicting in Multi-Domain Dialogue State Tracking, Ruolin Su (Georgia Tech, USA), Ting-Wei Wu (Georgia Tech, USA) and Biing-Hwang Juang (Georgia Tech, USA)
- 09:30 Tue-M-V-4-4 171 Dialogue Situation Recognition for Everyday Conversation Using Multimodal Information, Yuya Chiba (NTT, Japan) and Ryuichiro Higashinaka (Nagoya University, Japan)
- 09:30 Tue-M-V-4-5 381 Neural Spoken-Response Generation Using Prosodic and Linguistic Context for Conversational Systems, Yoshihiro Yamazaki (Tohoku University, Japan), Yuya Chiba (NTT, Japan), Takashi Nose (Tohoku University, Japan) and Akinori Ito (Tohoku University, Japan)
- 09:30 Tue-M-V-4-6 548 Semantic Transportation Prototypical Network for Few-Shot Intent Detection, Weiyuan Xu (Peking University, China), Peilin Zhou (Peking University, China), Chenyu You (Yale University, USA) and Yuexian Zou (Peking University, China)
- 09:30 Tue-M-V-4-7 887 Domain-Specific Multi-Agent Dialog Policy Learning in Multi-Domain Task-Oriented Scenarios, Li Tang (Tianjin University, China), Yuke Si (Tianjin University, China), Longbiao Wang (Tianjin University, China) and Jianwu Dang (Tianjin University, China)
- 09:30 Tue-M-V-4-8 1370 Leveraging ASR N-Best in Deep Entity Retrieval, Haoyu Wang (Amazon, USA), John Chen (University of Toronto, Canada), Majid Laali (Amazon, Canada), Kevin Durda (Amazon, Canada), Jeff King (Amazon, Canada), William Campbell (Amazon, USA) and Yang Liu (Amazon, USA)
Tue-M-V-5 Tuesday, August 31, 09:30-11:30 Virtual: Topics in ASR: Robustness, feature extraction, and far-field ASR
- 09:30 Tue-M-V-5-1 1242 End-to-End Spelling Correction Conditioned on Acoustic Feature for Code-Switching Speech Recognition, Shuai Zhang (UCAS, China), Jiangyan Yi (CAS, China), Zhengkun Tian (UCAS, China), Ye Bai (UCAS, China), Jianhua Tao (UCAS, China), Xuefei Liu (CAS, China) and Zhengqi Wen (CAS, China)
- 09:30 Tue-M-V-5-2 1434 Phoneme Recognition Through Fine Tuning of Phonetic Representations: A Case Study on Luhya Language Varieties, Kathleen Siminyu (Georgia Tech, USA), Xinjian Li (Carnegie Mellon University, USA), Antonios Anastasopoulos (George Mason University, USA), David R. Mortensen (Carnegie Mellon University, USA), Michael R. Marlo (Mizzou, USA) and Graham Neubig (Carnegie Mellon University, USA)
- 09:30 Tue-M-V-5-3 53 Speech Acoustic Modelling Using Raw Source and Filter Components, Erfan Loweimi (University of Edinburgh, UK), Zoran Cvetkovic (King’s College London, UK), Peter Bell (University of Edinburgh, UK) and Steve Renals (University of Edinburgh, UK)
- 09:30 Tue-M-V-5-4 225 Noise Robust Acoustic Modeling for Single-Channel Speech Recognition Based on a Stream-Wise Transformer Architecture, Masakiyo Fujimoto (NICT, Japan) and Hisashi Kawai (NICT, Japan)
- 09:30 Tue-M-V-5-5 230 IR-GAN: Room Impulse Response Generator for Far-Field Speech Recognition, Anton Ratnarajah (University of Maryland, USA), Zhenyu Tang (University of Maryland, USA) and Dinesh Manocha (University of Maryland, USA)
- 09:30 Tue-M-V-5-6 419 Scaling Sparsemax Based Channel Selection for Speech Recognition with ad-hoc Microphone Arrays, Junqi Chen (Northwestern Polytechnical University, China) and Xiao-Lei Zhang (Northwestern Polytechnical University, China)
- 09:30 Tue-M-V-5-7 655 Multi-Channel Transformer Transducer for Speech Recognition, Feng-Ju Chang (Amazon, USA), Martin Radfar (Amazon, USA), Athanasios Mouchtaris (Amazon, USA) and Maurizio Omologo (Amazon, USA)
- 09:30 Tue-M-V-5-8 958 Data Augmentation Methods for End-to-End Speech Recognition on Distant-Talk Scenarios, Emiru Tsunoo (Sony, Japan), Kentaro Shibata (Sony, Japan), Chaitanya Narisetty (Carnegie Mellon University, USA), Yosuke Kashiwagi (Sony, Japan) and Shinji Watanabe (Carnegie Mellon University, USA)
- 09:30 Tue-M-V-5-9 964 Leveraging Phone Mask Training for Phonetic-Reduction-Robust E2E Uyghur Speech Recognition, Guodong Ma (Xinjiang University, China), Pengfei Hu (Tencent, China), Jian Kang (Tencent, China), Shen Huang (Tencent, China) and Hao Huang (Xinjiang University, China)
- 09:30 Tue-M-V-5-10 1758 Rethinking Evaluation in ASR: Are Our Models Robust Enough?, Tatiana Likhomanenko (Facebook, USA), Qiantong Xu (Facebook, USA), Vineel Pratap (Facebook, USA), Paden Tomasello (Facebook, USA), Jacob Kahn (Facebook, USA), Gilad Avidov (Facebook, USA), Ronan Collobert (Facebook, USA) and Gabriel Synnaeve (Facebook, France)
- 09:30 Tue-M-V-5-11 2084 Raw Waveform Encoder with Multi-Scale Globally Attentive Locally Recurrent Networks for End-to-End Speech Recognition, Max W.Y. Lam (Tencent, China), Jun Wang (Tencent, China), Chao Weng (Tencent, China), Dan Su (Tencent, China) and Dong Yu (Tencent, USA)
Tue-M-V-6 Tuesday, August 31, 09:30-11:30 Virtual: Voice activity detection and keyword spotting
- 09:30 Tue-M-V-6-1 37 Attention-Based Cross-Modal Fusion for Audio-Visual Voice Activity Detection in Musical Video Streams, Yuanbo Hou (Ghent University, Belgium), Zhesong Yu (ByteDance, China), Xia Liang (ByteDance, China), Xingjian Du (ByteDance, China), Bilei Zhu (ByteDance, China), Zejun Ma (ByteDance, China) and Dick Botteldooren (Ghent University, Belgium)
- 09:30 Tue-M-V-6-2 43 Noise-Tolerant Self-Supervised Learning for Audio-Visual Voice Activity Detection, Ui-Hyun Kim (Toshiba, Japan)
- 09:30 Tue-M-V-6-3 72 Noisy Student-Teacher Training for Robust Keyword Spotting, Hyun-Jin Park (Google, USA), Pai Zhu (Google, USA), Ignacio Lopez Moreno (Google, USA) and Niranjan Subrahmanya (Google, USA)
- 09:30 Tue-M-V-6-4 200 Multi-Channel VAD for Transcription of Group Discussion, Osamu Ichikawa (Shiga University, Japan), Kaito Nakano (Shiga University, Japan), Takahiro Nakayama (University of Tokyo, Japan) and Hajime Shirouzu (NIER, Japan)
- 09:30 Tue-M-V-6-5 592 Audio-Visual Information Fusion Using Cross-Modal Teacher-Student Learning for Voice Activity Detection in Realistic Environments, Hengshun Zhou (USTC, China), Jun Du (USTC, China), Hang Chen (USTC, China), Zijun Jing (iFLYTEK, China), Shifu Xiong (iFLYTEK, China) and Chin-Hui Lee (Georgia Tech, USA)
- 09:30 Tue-M-V-6-6 731 Enrollment-Less Training for Personalized Voice Activity Detection, Naoki Makishima (NTT, Japan), Mana Ihori (NTT, Japan), Tomohiro Tanaka (NTT, Japan), Akihiko Takashima (NTT, Japan), Shota Orihashi (NTT, Japan) and Ryo Masumura (NTT, Japan)
- 09:30 Tue-M-V-6-7 792 Voice Activity Detection for Live Speech of Baseball Game Based on Tandem Connection with Speech/Noise Separation Model, Yuto Nonaka (University of Yamanashi, Japan), Chee Siang Leow (University of Yamanashi, Japan), Akio Kobayashi (NTUT, Japan), Takehito Utsuro (University of Tsukuba, Japan) and Hiromitsu Nishizaki (University of Yamanashi, Japan)
- 09:30 Tue-M-V-6-8 1091 FastICARL: Fast Incremental Classifier and Representation Learning with Efficient Budget Allocation in Audio Sensing Applications, Young D. Kwon (University of Cambridge, UK), Jagmohan Chauhan (University of Cambridge, UK) and Cecilia Mascolo (University of Cambridge, UK)
- 09:30 Tue-M-V-6-9 1335 End-to-End Transformer-Based Open-Vocabulary Keyword Spotting with Location-Guided Local Attention, Bo Wei (Samsung, China), Meirong Yang (Samsung, China), Tao Zhang (Samsung, China), Xiao Tang (Samsung, China), Xing Huang (Samsung, China), Kyuhong Kim (Samsung, Korea), Jaeyun Lee (Samsung, Korea), Kiho Cho (Samsung, Korea) and Sung-Un Park (Samsung, Korea)
- 09:30 Tue-M-V-6-10 1874 Segmental Contrastive Predictive Coding for Unsupervised Word Segmentation, Saurabhchand Bhati (Johns Hopkins University, USA), Jesús Villalba (Johns Hopkins University, USA), Piotr Żelasko (Johns Hopkins University, USA), Laureano Moro-Velázquez (Johns Hopkins University, USA) and Najim Dehak (Johns Hopkins University, USA)
- 09:30 Tue-M-V-6-11 1977 A Lightweight Framework for Online Voice Activity Detection in the Wild, Xuenan Xu (SJTU, China), Heinrich Dinkel (Xiaomi, China), Mengyue Wu (SJTU, China) and Kai Yu (SJTU, China)
Tue-M-V-7 Tuesday, August 31, 09:30-11:30 Virtual: Voice and voicing
- 09:30 Tue-M-V-7-1 129 “See what I mean, huh?” Evaluating Visual Inspection of F₀ Tracking in Nasal Grunts, Aurélie Chlébowski (CLILLAC-ARP (EA 3967), France) and Nicolas Ballier (CLILLAC-ARP (EA 3967), France)
- 09:30 Tue-M-V-7-2 267 System Performance as a Function of Calibration Methods, Sample Size and Sampling Variability in Likelihood Ratio-Based Forensic Voice Comparison, Bruce Xiao Wang (University of York, UK) and Vincent Hughes (University of York, UK)
- 09:30 Tue-M-V-7-3 601 Voicing Assimilations by French Speakers of German in Stop-Fricative Sequences, Anne Bonneau (Loria (UMR 7503), France)
- 09:30 Tue-M-V-7-4 635 The Four-Way Classification of Stops with Voicing and Aspiration for Non-Native Speech Evaluation, Titas Chakraborty (IIT Bombay, India), Vaishali Patil (IIIT Pune, India) and Preeti Rao (IIT Bombay, India)
- 09:30 Tue-M-V-7-5 910 Acoustic and Prosodic Correlates of Emotions in Urdu Speech, Saba Urooj (UET Lahore, Pakistan), Benazir Mumtaz (Universität Konstanz, Germany), Sarmad Hussain (UET Lahore, Pakistan) and Ehsan ul Haq (UET Lahore, Pakistan)
- 09:30 Tue-M-V-7-6 1079 Voicing Contrasts in the Singleton Stops of Palestinian Arabic: Production and Perception, Nour Tamim (University of Amsterdam, The Netherlands) and Silke Hamann (University of Amsterdam, The Netherlands)
- 09:30 Tue-M-V-7-7 1487 A Comparison of the Accuracy of Dissen and Keshet’s (2016) DeepFormants and Traditional LPC Methods for Semi-Automatic Speaker Recognition, Thomas Coy (University of York, UK), Vincent Hughes (University of York, UK), Philip Harrison (University of York, UK) and Amelia J. Gully (University of York, UK)
- 09:30 Tue-M-V-7-8 1697 MAP Adaptation Characteristics in Forensic Long-Term Formant Analysis, Michael Jessen (Bundeskriminalamt, Germany)
- 09:30 Tue-M-V-7-9 1699 Cross-Linguistic Speaker Individuality of Long-Term Formant Distributions: Phonetic and Forensic Perspectives, Justin J.H. Lo (University of York, UK)
- 09:30 Tue-M-V-7-10 1754 Sound Change in Spontaneous Bilingual Speech: A Corpus Study on the Cantonese n-l Merger in Cantonese-English Bilinguals, Rachel Soo (University of British Columbia, Canada), Khia A. Johnson (University of British Columbia, Canada) and Molly Babel (University of British Columbia, Canada)
- 09:30 Tue-M-V-7-11 2104 Characterizing Voiced and Voiceless Nasals in Mizo, Wendy Lalhminghlui (IIT Guwahati, India) and Priyankoo Sarmah (IIT Guwahati, India)
Tue-M-SS-1 Tuesday, August 31, 09:30-11:30 Special-Virtual: The INTERSPEECH 2021 Computational Paralinguistics Challenge (ComParE) - COVID-19 Cough, COVID-19 Speech, Escalation & Primates
- 09:30 Tue-M-SS-1-1 19 The INTERSPEECH 2021 Computational Paralinguistics Challenge: COVID-19 Cough, COVID-19 Speech, Escalation & Primates, Björn W. Schuller (Imperial College London, UK), Anton Batliner (Universität Augsburg, Germany), Christian Bergler (FAU Erlangen-Nürnberg, Germany), Cecilia Mascolo (University of Cambridge, UK), Jing Han (University of Cambridge, UK), Iulia Lefter (Technische Universiteit Delft, The Netherlands), Heysem Kaya (Universiteit Utrecht, The Netherlands), Shahin Amiriparian (Universität Augsburg, Germany), Alice Baird (Universität Augsburg, Germany), Lukas Stappen (Universität Augsburg, Germany), Sandra Ottl (Universität Augsburg, Germany), Maurice Gerczuk (Universität Augsburg, Germany), Panagiotis Tzirakis (Imperial College London, UK), Chloë Brown (University of Cambridge, UK), Jagmohan Chauhan (University of Cambridge, UK), Andreas Grammenos (University of Cambridge, UK), Apinan Hasthanasombat (University of Cambridge, UK), Dimitris Spathis (University of Cambridge, UK), Tong Xia (University of Cambridge, UK), Pietro Cicuta (University of Cambridge, UK), Leon J.M. Rothkrantz (Technische Universiteit Delft, The Netherlands), Joeri A. Zwerts (Universiteit Utrecht, The Netherlands), Jelle Treep (Universiteit Utrecht, The Netherlands) and Casper S. Kaandorp (Universiteit Utrecht, The Netherlands)
- 09:40 Tue-M-SS-1-2 1702 Transfer Learning-Based Cough Representations for Automatic Detection of COVID-19, Rubén Solera-Ureña (INESC-ID Lisboa, Portugal), Catarina Botelho (INESC-ID Lisboa, Portugal), Francisco Teixeira (INESC-ID Lisboa, Portugal), Thomas Rolland (INESC-ID Lisboa, Portugal), Alberto Abad (INESC-ID Lisboa, Portugal) and Isabel Trancoso (INESC-ID Lisboa, Portugal)
- 09:49 Tue-M-SS-1-3 1488 The Phonetic Footprint of Covid-19?, P. Klumpp (FAU Erlangen-Nürnberg, Germany), T. Bocklet (TH Nürnberg, Germany), T. Arias-Vergara (FAU Erlangen-Nürnberg, Germany), J.C. Vásquez-Correa (FAU Erlangen-Nürnberg, Germany), P.A. Pérez-Toro (FAU Erlangen-Nürnberg, Germany), S.P. Bayerl (TH Nürnberg, Germany), J.R. Orozco-Arroyave (FAU Erlangen-Nürnberg, Germany) and Elmar Nöth (FAU Erlangen-Nürnberg, Germany)
- 09:58 Tue-M-SS-1-4 1798 Transfer Learning and Data Augmentation Techniques to the COVID-19 Identification Tasks in ComParE 2021, Edresson Casanova (Universidade de São Paulo, Brazil), Arnaldo Candido Jr. (Universidade Tecnológica Federal do Paraná, Brazil), Ricardo Corso Fernandes Jr. (Universidade Tecnológica Federal do Paraná, Brazil), Marcelo Finger (Universidade de São Paulo, Brazil), Lucas Rafael Stefanel Gris (Universidade Tecnológica Federal do Paraná, Brazil), Moacir Antonelli Ponti (Universidade de São Paulo, Brazil) and Daniel Peixoto Pinto da Silva (Universidade Tecnológica Federal do Paraná, Brazil)
- 10:07 Tue-M-SS-1-5 273 Visual Transformers for Primates Classification and Covid Detection, Steffen Illium (LMU München, Germany), Robert Müller (LMU München, Germany), Andreas Sedlmeier (LMU München, Germany) and Claudia-Linnhoff Popien (LMU München, Germany)
- 10:16 Tue-M-SS-1-6 1911 Deep-Learning-Based Central African Primate Species Classification with MixUp and SpecAugment, Thomas Pellegrini (IRIT (UMR 5505), France)
- 10:25 Tue-M-SS-1-7 1274 A Deep and Recurrent Architecture for Primate Vocalization Classification, Robert Müller (LMU München, Germany), Steffen Illium (LMU München, Germany) and Claudia Linnhoff-Popien (LMU München, Germany)
- 10:34 Tue-M-SS-1-8 154 Introducing a Central African Primate Vocalisation Dataset for Automated Species Classification, Joeri A. Zwerts (Universiteit Utrecht, The Netherlands), Jelle Treep (Universiteit Utrecht, The Netherlands), Casper S. Kaandorp (Universiteit Utrecht, The Netherlands), Floor Meewis (Universiteit Utrecht, The Netherlands), Amparo C. Koot (Universiteit Utrecht, The Netherlands) and Heysem Kaya (Universiteit Utrecht, The Netherlands)
- 10:43 Tue-M-SS-1-9 1969 Multi-Attentive Detection of the Spider Monkey Whinny in the (Actual) Wild, Georgios Rizos (Imperial College London, UK), Jenna Lawson (Imperial College London, UK), Zhuoda Han (Imperial College London, UK), Duncan Butler (Imperial College London, UK), James Rosindell (Imperial College London, UK), Krystian Mikolajczyk (Imperial College London, UK), Cristina Banks-Leite (Imperial College London, UK) and Björn W. Schuller (Imperial College London, UK)
- 10:52 Tue-M-SS-1-10 1173 Identifying Conflict Escalation and Primates by Using Ensemble X-Vectors and Fisher Vector Features, José Vicente Egas-López (University of Szeged, Hungary), Mercedes Vetráb (University of Szeged, Hungary), László Tóth (University of Szeged, Hungary) and Gábor Gosztolya (University of Szeged, Hungary)
- 11:01 Tue-M-SS-1-11 1821 Ensemble-Within-Ensemble Classification for Escalation Prediction from Speech, Oxana Verkholyak (RAS, Russia), Denis Dresvyanskiy (Universität Ulm, Germany), Anastasia Dvoynikova (RAS, Russia), Denis Kotov (Universität Ulm, Germany), Elena Ryumina (RAS, Russia), Alena Velichko (RAS, Russia), Danila Mamontov (Universität Ulm, Germany), Wolfgang Minker (Universität Ulm, Germany) and Alexey Karpov (RAS, Russia)
- 11:10 Tue-M-SS-1-12 1587 Analysis by Synthesis: Using an Expressive TTS Model as Feature Extractor for Paralinguistic Speech Classification, Dominik Schiller (Universität Augsburg, Germany), Silvan Mertes (Universität Augsburg, Germany), Pol van Rijn (MPI for Empirical Aesthetics, Germany) and Elisabeth André (Universität Augsburg, Germany)
- 11:19 Discussion
Tue-A-O-1 Tuesday, August 31, 13:30-15:30 In-person Oral: Embedding and Network Architecture for Speaker Recognition
- 13:30 Tue-A-O-1-1 622 Leveraging Speaker Attribute Information Using Multi Task Learning for Speaker Verification and Diarization, Chau Luu (University of Edinburgh, UK), Peter Bell (University of Edinburgh, UK) and Steve Renals (University of Edinburgh, UK)
- 13:50 Tue-A-O-1-2 1163 Spine2Net: SpineNet with Res2Net and Time-Squeeze-and-Excitation Blocks for Speaker Recognition, Magdalena Rybicka (AGH UST, Poland), Jesús Villalba (Johns Hopkins University, USA), Piotr Żelasko (Johns Hopkins University, USA), Najim Dehak (Johns Hopkins University, USA) and Konrad Kowalczyk (AGH UST, Poland)
- 14:10 Tue-A-O-1-3 1442 Speaker Embeddings by Modeling Channel-Wise Correlations, Themos Stafylakis (Omilia, Greece), Johan Rohdin (Omilia, Greece) and Lukáš Burget (Brno University of Technology, Czech Republic)
- 14:30 Tue-A-O-1-4 1769 Multi-Task Neural Network for Robust Multiple Speaker Embedding Extraction, Weipeng He (Idiap Research Institute, Switzerland), Petr Motlicek (Idiap Research Institute, Switzerland) and Jean-Marc Odobez (Idiap Research Institute, Switzerland)
- 14:50 Tue-A-O-1-5 2016 ICSpk: Interpretable Complex Speaker Embedding Extractor from Raw Waveform, Junyi Peng (Ping An Technology, China), Xiaoyang Qu (Ping An Technology, China), Jianzong Wang (Ping An Technology, China), Rongzhi Gu (Peking University, China), Jing Xiao (Ping An Technology, China), Lukáš Burget (Brno University of Technology, Czech Republic) and Jan Černocký (Brno University of Technology, Czech Republic)
Tue-A-O-2 Tuesday, August 31, 13:30-15:30 In-person Oral: Speech perception I
- 13:30 Tue-A-O-2-1 182 Prosodic Disambiguation Using Chironomic Stylization of Intonation with Native and Non-Native Speakers, Xiao Xiao (LPP (UMR 7018), France), Nicolas Audibert (LPP (UMR 7018), France), Grégoire Locqueville (∂’Alembert (UMR 7190), France), Christophe d’Alessandro (∂’Alembert (UMR 7190), France), Barbara Kuhnert (LPP (UMR 7018), France) and Claire Pillot-Loiseau (LPP (UMR 7018), France)
- 13:50 Tue-A-O-2-2 228 Variation in Perceptual Sensitivity and Compensation for Coarticulation Across Adult and Child Naturally-Produced and TTS Voices, Aleese Block (University of California at Davis, USA), Michelle Cohn (University of California at Davis, USA) and Georgia Zellou (University of California at Davis, USA)
- 14:10 Tue-A-O-2-3 336 Extracting Different Levels of Speech Information from EEG Using an LSTM-Based Model, Mohammad Jalilpour Monesi (KU Leuven, Belgium), Bernd Accou (KU Leuven, Belgium), Tom Francart (KU Leuven, Belgium) and Hugo Van hamme (KU Leuven, Belgium)
- 14:30 Tue-A-O-2-4 1394 Word Competition: An Entropy-Based Approach in the DIANA Model of Human Word Comprehension, Louis ten Bosch (Radboud Universiteit, The Netherlands) and Lou Boves (Radboud Universiteit, The Netherlands)
- 14:50 Tue-A-O-2-5 1408 Time-to-Event Models for Analyzing Reaction Time Sequences, Louis ten Bosch (Radboud Universiteit, The Netherlands) and Lou Boves (Radboud Universiteit, The Netherlands)
- 15:10 Tue-A-O-2-6 1700 Models of Reaction Times in Auditory Lexical Decision: RTonset versus RToffset, Sophie Brand (Zuyd Hogeschool, The Netherlands), Kimberley Mulder (Universiteit Utrecht, The Netherlands), Louis ten Bosch (Radboud Universiteit, The Netherlands) and Lou Boves (Radboud Universiteit, The Netherlands)
Tue-A-V-1 Tuesday, August 31, 13:30-15:30 Virtual: Acoustic event detection and acoustic scene classification
- 13:30 Tue-A-V-1-1 103 SpecMix : A Mixed Sample Data Augmentation Method for Training with Time-Frequency Domain Features, Gwantae Kim (Korea University, Korea), David K. Han (Drexel University, USA) and Hanseok Ko (Korea University, Korea)
- 13:30 Tue-A-V-1-2 140 SpecAugment++: A Hidden Space Data Augmentation Method for Acoustic Scene Classification, Helin Wang (Peking University, China), Yuexian Zou (Peking University, China) and Wenwu Wang (University of Surrey, UK)
- 13:30 Tue-A-V-1-3 281 An Effective Mutual Mean Teaching Based Domain Adaptation Method for Sound Event Detection, Xu Zheng (USTC, China), Yan Song (USTC, China), Li-Rong Dai (USTC, China), Ian McLoughlin (USTC, China) and Lin Liu (iFLYTEK, China)
- 13:30 Tue-A-V-1-5 656 Acoustic Scene Classification Using Kervolution-Based SubSpectralNet, Ritika Nandi (MAHE, India), Shashank Shekhar (MAHE, India) and Manjunath Mulimani (MAHE, India)
- 13:30 Tue-A-V-1-6 684 Event Specific Attention for Polyphonic Sound Event Detection, Harshavardhan Sundar (Amazon, USA), Ming Sun (Amazon, USA) and Chao Wang (Amazon, USA)
- 13:30 Tue-A-V-1-7 698 AST: Audio Spectrogram Transformer, Yuan Gong (MIT, USA), Yu-An Chung (MIT, USA) and James Glass (MIT, USA)
- 13:30 Tue-A-V-1-8 1308 Shallow Convolution-Augmented Transformer with Differentiable Neural Computer for Low-Complexity Classification of Variable-Length Acoustic Scene, Soonshin Seo (Sogang University, Korea), Donghyun Lee (Sogang University, Korea) and Ji-Hwan Kim (Sogang University, Korea)
- 13:30 Tue-A-V-1-9 1837 An Evaluation of Data Augmentation Methods for Sound Scene Geotagging, Helen L. Bear (Queen Mary University of London, UK), Veronica Morfi (Queen Mary University of London, UK) and Emmanouil Benetos (Queen Mary University of London, UK)
- 13:30 Tue-A-V-1-10 1975 Optimizing Latency for Online Video Captioning Using Audio-Visual Transformers, Chiori Hori (MERL, USA), Takaaki Hori (MERL, USA) and Jonathan Le Roux (MERL, USA)
- 13:30 Tue-A-V-1-11 2028 Variational Information Bottleneck for Effective Low-Resource Audio Classification, Shijing Si (Ping An Technology, China), Jianzong Wang (Ping An Technology, China), Huiming Sun (Ping An Technology, China), Jianhan Wu (USTC, China), Chuanyao Zhang (USTC, China), Xiaoyang Qu (Ping An Technology, China), Ning Cheng (Ping An Technology, China), Lei Chen (HKUST, China) and Jing Xiao (Ping An Technology, China)
- 13:30 Tue-A-V-1-12 2079 Improving Weakly Supervised Sound Event Detection with Self-Supervised Auxiliary Tasks, Soham Deshmukh (Microsoft, USA), Bhiksha Raj (Carnegie Mellon University, USA) and Rita Singh (Carnegie Mellon University, USA)
- 13:30 Tue-A-V-1-13 2218 Acoustic Event Detection with Classifier Chains, Tatsuya Komatsu (LINE, Japan), Shinji Watanabe (Carnegie Mellon University, USA), Koichi Miyazaki (Nagoya University, Japan) and Tomoki Hayashi (Nagoya University, Japan)
Tue-A-V-2 Tuesday, August 31, 13:30-15:30 Virtual: Diverse modes of speech acquisition and processing
- 13:30 Tue-A-V-2-1 757 Segment and Tone Production in Continuous Speech of Hearing and Hearing-Impaired Children, Shu-Chuan Tseng (Academia Sinica, Taiwan) and Yi-Fen Liu (Feng Chia University, Taiwan)
- 13:30 Tue-A-V-2-2 24 Effect of Carrier Bandwidth on Understanding Mandarin Sentences in Simulated Electric-Acoustic Hearing, Feng Wang (SUSTech, China), Jing Chen (Peking University, China) and Fei Chen (SUSTech, China)
- 13:30 Tue-A-V-2-3 2240 A Comparative Study of Different EMG Features for Acoustics-to-EMG Mapping, Manthan Sharma (Indian Institute of Science, India), Navaneetha Gaddam (Indian Institute of Science, India), Tejas Umesh (Indian Institute of Science, India), Aditya Murthy (Indian Institute of Science, India) and Prasanta Kumar Ghosh (Indian Institute of Science, India)
- 13:30 Tue-A-V-2-4 1155 Image-Based Assessment of Jaw Parameters and Jaw Kinematics for Articulatory Simulation: Preliminary Results, Ajish K. Abraham (AIISH, India), V. Sivaramakrishnan (AIISH, India), N. Swapna (AIISH, India) and N. Manohar (AIISH, India)
- 13:30 Tue-A-V-2-5 440 An Attention Self-Supervised Contrastive Learning Based Three-Stage Model for Hand Shape Feature Representation in Cued Speech, Jianrong Wang (Tianjin University, China), Nan Gu (Tianjin University, China), Mei Yu (Tianjin University, China), Xuewei Li (Tianjin University, China), Qiang Fang (CASS, China) and Li Liu (CUHK, China)
- 13:30 Tue-A-V-2-6 1240 Remote Smartphone-Based Speech Collection: Acceptance and Barriers in Individuals with Major Depressive Disorder, Judith Dineley (Universität Augsburg, Germany), Grace Lavelle (King’s College London, UK), Daniel Leightley (King’s College London, UK), Faith Matcham (King’s College London, UK), Sara Siddi (CIBERSAM, Spain), Maria Teresa Peñarrubia-María (IDIAP Jordi Gol, Spain), Katie M. White (King’s College London, UK), Alina Ivan (King’s College London, UK), Carolin Oetzmann (King’s College London, UK), Sara Simblett (King’s College London, UK), Erin Dawe-Lane (King’s College London, UK), Stuart Bruce (King’s College London, UK), Daniel Stahl (King’s College London, UK), Yatharth Ranjan (King’s College London, UK), Zulqarnain Rashid (King’s College London, UK), Pauline Conde (King’s College London, UK), Amos A. Folarin (King’s College London, UK), Josep Maria Haro (CIBERSAM, Spain), Til Wykes (King’s College London, UK), Richard J.B. Dobson (King’s College London, UK), Vaibhav A. Narayan (Janssen, USA), Matthew Hotopf (King’s College London, UK), Björn W. Schuller (Universität Augsburg, Germany), Nicholas Cummins (Universität Augsburg, Germany) and The RADAR-CNS Consortium
- 13:30 Tue-A-V-2-7 1749 An Automatic, Simple Ultrasound Biofeedback Parameter for Distinguishing Accurate and Misarticulated Rhotic Syllables, Sarah R. Li (University of Cincinnati, USA), Colin T. Annand (University of Cincinnati, USA), Sarah Dugan (University of Cincinnati, USA), Sarah M. Schwab (University of Cincinnati, USA), Kathryn J. Eary (University of Cincinnati, USA), Michael Swearengen (University of Cincinnati, USA), Sarah Stack (University of Cincinnati, USA), Suzanne Boyce (University of Cincinnati, USA), Michael A. Riley (University of Cincinnati, USA) and T. Douglas Mast (University of Cincinnati, USA)
- 13:30 Tue-A-V-2-8 23 Silent versus Modal Multi-Speaker Speech Recognition from Ultrasound and Video, Manuel Sam Ribeiro (Amazon, Poland), Aciel Eshky (Rasa Technologies, UK), Korin Richmond (University of Edinburgh, UK) and Steve Renals (University of Edinburgh, UK)
- 13:30 Tue-A-V-2-9 1413 RaSSpeR: Radar-Based Silent Speech Recognition, David Ferreira (Universidade de Aveiro, Portugal), Samuel Silva (Universidade de Aveiro, Portugal), Francisco Curado (Universidade de Aveiro, Portugal) and António Teixeira (Universidade de Aveiro, Portugal)
- 13:30 Tue-A-V-2-10 1842 Investigating Speech Reconstruction for Laryngectomees for Silent Speech Interfaces, Beiming Cao (University of Texas at Austin, USA), Nordine Sebkhi (Georgia Tech, USA), Arpan Bhavsar (Georgia Tech, USA), Omer T. Inan (Georgia Tech, USA), Robin Samlan (University of Arizona, USA), Ted Mau (UT Southwestern Medical Center, USA) and Jun Wang (University of Texas at Austin, USA)
Tue-A-V-3 Tuesday, August 31, 13:30-15:30 Virtual: Multi-channel speech enhancement and hearing aids
- 13:30 Tue-A-V-3-1 633 LACOPE: Latency-Constrained Pitch Estimation for Speech Enhancement, Hendrik Schröter (FAU Erlangen-Nürnberg, Germany), Tobias Rosenkranz (Sivantos, Germany), Alberto N. Escalante-B. (Sivantos, Germany) and Andreas Maier (FAU Erlangen-Nürnberg, Germany)
- 13:30 Tue-A-V-3-2 742 Alpha-Stable Autoregressive Fast Multichannel Nonnegative Matrix Factorization for Joint Speech Enhancement and Dereverberation, Mathieu Fontaine (RIKEN, Japan), Kouhei Sekiguchi (RIKEN, Japan), Aditya Arie Nugraha (RIKEN, Japan), Yoshiaki Bando (AIST, Japan) and Kazuyoshi Yoshii (Kyoto University, Japan)
- 13:30 Tue-A-V-3-3 944 Microphone Array Generalization for Multichannel Narrowband Deep Speech Enhancement, Siyuan Zhang (Westlake University, China) and Xiaofei Li (Westlake University, China)
- 13:30 Tue-A-V-3-4 1178 Multiple Sound Source Localization Based on Interchannel Phase Differences in All Frequencies with Spectral Masks, Hyungchan Song (GIST, Korea) and Jong Won Shin (GIST, Korea)
- 13:30 Tue-A-V-3-5 1329 Cancellation of Local Competing Speaker with Near-Field Localization for Distributed ad-hoc Sensor Network, Pablo Pérez Zarazaga (Aalto University, Finland), Mariem Bouafif Mansali (Université de Tunis El Manar, Tunisia), Tom Bäckström (Aalto University, Finland) and Zied Lachiri (Université de Tunis El Manar, Tunisia)
- 13:30 Tue-A-V-3-6 1512 A Deep Learning Method to Multi-Channel Active Noise Control, Hao Zhang (Ohio State University, USA) and DeLiang Wang (Ohio State University, USA)
- 13:30 Tue-A-V-3-7 1574 Clarity-2021 Challenges: Machine Learning Challenges for Advancing Hearing Aid Processing, Simone Graetzer (University of Salford, UK), Jon Barker (University of Sheffield, UK), Trevor J. Cox (University of Salford, UK), Michael Akeroyd (University of Nottingham, UK), John F. Culling (Cardiff University, UK), Graham Naylor (University of Nottingham, UK), Eszter Porter (University of Nottingham, UK) and Rhoddy Viveros Muñoz (Cardiff University, UK)
- 13:30 Tue-A-V-3-8 1613 Optimising Hearing Aid Fittings for Speech in Noise with a Differentiable Hearing Loss Model, Zehai Tu (University of Sheffield, UK), Ning Ma (University of Sheffield, UK) and Jon Barker (University of Sheffield, UK)
- 13:30 Tue-A-V-3-9 1764 Explaining Deep Learning Models for Speech Enhancement, Sunit Sivasankaran (Microsoft, USA), Emmanuel Vincent (Loria (UMR 7503), France) and Dominique Fohr (Loria (UMR 7503), France)
- 13:30 Tue-A-V-3-10 1989 Minimum-Norm Differential Beamforming for Linear Array with Directional Microphones, Weilong Huang (Alibaba, China) and Jinwei Feng (Alibaba, USA)
Tue-A-V-4 Tuesday, August 31, 13:30-15:30 Virtual: Self-supervision and semi-supervision for neural ASR training
- 13:30 Tue-A-V-4-1 1454 Improving Streaming Transformer Based ASR Under a Framework of Self-Supervised Learning, Songjun Cao (Tencent, China), Yueteng Kang (Tencent, China), Yanzhe Fu (Tencent, China), Xiaoshuo Xu (Tencent, China), Sining Sun (Tencent, China), Yike Zhang (Tencent, China) and Long Ma (Tencent, China)
- 13:30 Tue-A-V-4-2 717 wav2vec-C: A Self-Supervised Model for Speech Representation Learning, Samik Sadhu (Johns Hopkins University, USA), Di He (Amazon, USA), Che-Wei Huang (Amazon, USA), Sri Harish Mallidi (Amazon, USA), Minhua Wu (Amazon, USA), Ariya Rastrow (Amazon, USA), Andreas Stolcke (Amazon, USA), Jasha Droppo (Amazon, USA) and Roland Maas (Amazon, USA)
- 13:30 Tue-A-V-4-3 1777 On the Learning Dynamics of Semi-Supervised Training for ASR, Electra Wallington (University of Edinburgh, UK), Benji Kershenbaum (University of Edinburgh, UK), Ondřej Klejch (University of Edinburgh, UK) and Peter Bell (University of Edinburgh, UK)
- 13:30 Tue-A-V-4-4 236 Robust wav2vec 2.0: Analyzing Domain Shift in Self-Supervised Pre-Training, Wei-Ning Hsu (Facebook, USA), Anuroop Sriram (Facebook, USA), Alexei Baevski (Facebook, USA), Tatiana Likhomanenko (Facebook, USA), Qiantong Xu (Facebook, USA), Vineel Pratap (Facebook, USA), Jacob Kahn (Facebook, USA), Ann Lee (Facebook, USA), Ronan Collobert (Facebook, USA), Gabriel Synnaeve (Facebook, France) and Michael Auli (Facebook, USA)
- 13:30 Tue-A-V-4-5 571 Momentum Pseudo-Labeling for Semi-Supervised Speech Recognition, Yosuke Higuchi (MERL, USA), Niko Moritz (MERL, USA), Jonathan Le Roux (MERL, USA) and Takaaki Hori (MERL, USA)
- 13:30 Tue-A-V-4-6 654 A Comparison of Supervised and Unsupervised Pre-Training of End-to-End Models, Ananya Misra (Google, USA), Dongseong Hwang (Google, USA), Zhouyuan Huo (Google, USA), Shefali Garg (Google, USA), Nikhil Siddhartha (Google, USA), Arun Narayanan (Google, USA) and Khe Chai Sim (Google, USA)
- 13:30 Tue-A-V-4-7 677 Semi-Supervision in ASR: Sequential MixMatch and Factorized TTS-Based Augmentation, Zhehuai Chen (Google, USA), Andrew Rosenberg (Google, USA), Yu Zhang (Google, USA), Heiga Zen (Google, Japan), Mohammadreza Ghodsi (Google, USA), Yinghui Huang (Google, USA), Jesse Emond (Google, USA), Gary Wang (Google, USA), Bhuvana Ramabhadran (Google, USA) and Pedro J. Moreno (Google, USA)
- 13:30 Tue-A-V-4-8 740 slimIPL: Language-Model-Free Iterative Pseudo-Labeling, Tatiana Likhomanenko (Facebook, USA), Qiantong Xu (Facebook, USA), Jacob Kahn (Facebook, USA), Gabriel Synnaeve (Facebook, France) and Ronan Collobert (Facebook, USA)
- 13:30 Tue-A-V-4-9 905 Phonetically Motivated Self-Supervised Speech Representation Learning, Xianghu Yue (NUS, Singapore) and Haizhou Li (NUS, Singapore)
- 13:30 Tue-A-V-4-10 1017 Improving RNN-T for Domain Scaling Using Semi-Supervised Training with Neural TTS, Yan Deng (Microsoft, China), Rui Zhao (Microsoft, USA), Zhong Meng (Microsoft, USA), Xie Chen (Microsoft, USA), Bing Liu (Microsoft, China), Jinyu Li (Microsoft, USA), Yifan Gong (Microsoft, USA) and Lei He (Microsoft, China)
Tue-A-V-5 Tuesday, August 31, 13:30-15:30 Virtual: Spoken Language Processing I
- 13:30 Tue-A-V-5-1 1864 Speaker-Conversation Factorial Designs for Diarization Error Analysis, Scott Seyfarth (Amazon, USA), Sundararajan Srinivasan (Amazon, USA) and Katrin Kirchhoff (Amazon, USA)
- 13:30 Tue-A-V-5-2 98 SmallER: Scaling Neural Entity Resolution for Edge Devices, Ross McGowan (Amazon, USA), Jinru Su (Amazon, USA), Vince DiCocco (Amazon, USA), Thejaswi Muniyappa (Amazon, USA) and Grant P. Strimel (Amazon, USA)
- 13:30 Tue-A-V-5-3 351 Disfluency Detection with Unlabeled Data and Small BERT Models, Johann C. Rocholl (Google, USA), Vicky Zayats (Google, USA), Daniel D. Walker (Google, USA), Noah B. Murad (Google, USA), Aaron Schneider (Google, USA) and Daniel J. Liebling (Google, USA)
- 13:30 Tue-A-V-5-4 246 Discriminative Self-Training for Punctuation Prediction, Qian Chen (Alibaba, China), Wen Wang (Alibaba, China), Mengzhe Chen (Alibaba, China) and Qinglin Zhang (Alibaba, China)
- 13:30 Tue-A-V-5-5 1607 Zero-Shot Joint Modeling of Multiple Spoken-Text-Style Conversion Tasks Using Switching Tokens, Mana Ihori (NTT, Japan), Naoki Makishima (NTT, Japan), Tomohiro Tanaka (NTT, Japan), Akihiko Takashima (NTT, Japan), Shota Orihashi (NTT, Japan) and Ryo Masumura (NTT, Japan)
- 13:30 Tue-A-V-5-6 1005 A Noise Robust Method for Word-Level Pronunciation Assessment, Binghuai Lin (Tencent, China) and Liyuan Wang (Tencent, China)
- 13:30 Tue-A-V-5-7 1670 Targeted Keyword Filtering for Accelerated Spoken Topic Identification, Jonathan Wintrode (Raytheon, USA)
- 13:30 Tue-A-V-5-8 1923 Multimodal Speech Summarization Through Semantic Concept Learning, Shruti Palaskar (Carnegie Mellon University, USA), Ruslan Salakhutdinov (Carnegie Mellon University, USA), Alan W. Black (Carnegie Mellon University, USA) and Florian Metze (Carnegie Mellon University, USA)
- 13:30 Tue-A-V-5-9 1270 Enhancing Semantic Understanding with Self-Supervised Methods for Abstractive Dialogue Summarization, Hyunjae Lee (Samsung, Korea), Jaewoong Yun (Samsung, Korea), Hyunjin Choi (Samsung, Korea), Seongho Joe (Samsung, Korea) and Youngjune L. Gwon (Samsung, Korea)
- 13:30 Tue-A-V-5-10 199 Speaker Transition Patterns in Three-Party Conversation: Evidence from English, Estonian and Swedish, Marcin Włodarczak (Stockholm University, Sweden) and Emer Gilmartin (Trinity College Dublin, Ireland)
Tue-A-V-6 Tuesday, August 31, 13:30-15:30 Virtual: Voice Conversion and Adaptation II
- 13:30 Tue-A-V-6-1 1730 Investigating Deep Neural Structures and their Interpretability in the Domain of Voice Conversion, Samuel J. Broughton (NUS, Singapore), Md. Asif Jalal (University of Sheffield, UK) and Roger K. Moore (University of Sheffield, UK)
- 13:30 Tue-A-V-6-2 781 Limited Data Emotional Voice Conversion Leveraging Text-to-Speech: Two-Stage Sequence-to-Sequence Training, Kun Zhou (NUS, Singapore), Berrak Sisman (SUTD, Singapore) and Haizhou Li (NUS, Singapore)
- 13:30 Tue-A-V-6-3 948 Adversarial Voice Conversion Against Neural Spoofing Detectors, Yi-Yang Ding (USTC, China), Li-Juan Liu (iFLYTEK, China), Yu Hu (USTC, China) and Zhen-Hua Ling (USTC, China)
- 13:30 Tue-A-V-6-4 1253 An Improved StarGAN for Emotional Voice Conversion: Enhancing Voice Quality and Data Augmentation, Xiangheng He (Imperial College London, UK), Junjie Chen (University of Tokyo, Japan), Georgios Rizos (Imperial College London, UK) and Björn W. Schuller (Imperial College London, UK)
- 13:30 Tue-A-V-6-5 1301 TVQVC: Transformer Based Vector Quantized Variational Autoencoder with CTC Loss for Voice Conversion, Ziyi Chen (CAS, China) and Pengyuan Zhang (CAS, China)
- 13:30 Tue-A-V-6-6 1351 Enriching Source Style Transfer in Recognition-Synthesis Based Non-Parallel Voice Conversion, Zhichao Wang (Northwestern Polytechnical University, China), Xinyong Zhou (Northwestern Polytechnical University, China), Fengyu Yang (Northwestern Polytechnical University, China), Tao Li (Northwestern Polytechnical University, China), Hongqiang Du (Northwestern Polytechnical University, China), Lei Xie (Northwestern Polytechnical University, China), Wendong Gan (iQIYI, China), Haitao Chen (iQIYI, China) and Hai Li (iQIYI, China)
- 13:30 Tue-A-V-6-7 1356 S2VC: A Framework for Any-to-Any Voice Conversion with Self-Supervised Pretrained Representations, Jheng-hao Lin (National Taiwan University, Taiwan), Yist Y. Lin (National Taiwan University, Taiwan), Chung-Ming Chien (National Taiwan University, Taiwan) and Hung-yi Lee (National Taiwan University, Taiwan)
- 13:30 Tue-A-V-6-8 1740 An Exemplar Selection Algorithm for Native-Nonnative Voice Conversion, Christopher Liberatore (Texas A&M University, USA) and Ricardo Gutierrez-Osuna (Texas A&M University, USA)
- 13:30 Tue-A-V-6-9 1990 Adversarially Learning Disentangled Speech Representations for Robust Multi-Factor Voice Conversion, Jie Wang (Tsinghua University, China), Jingbei Li (Tsinghua University, China), Xintao Zhao (Tsinghua University, China), Zhiyong Wu (Tsinghua University, China), Shiyin Kang (Huya, China) and Helen Meng (Tsinghua University, China)
- 13:30 Tue-A-V-6-10 2086 Many-to-Many Voice Conversion Based Feature Disentanglement Using Variational Autoencoder, Manh Luong (VinAI Research, Vietnam) and Viet Anh Tran (Deezer, France)
Tue-A-SS-1 Tuesday, August 31, 13:30-15:30 Special-Virtual: Privacy-preserving Machine Learning for Audio & Speech Processing
- 13:30 Tue-A-SS-1-1 983 Privacy-Preserving Voice Anti-Spoofing Using Secure Multi-Party Computation, Oubaïda Chouchane (EURECOM, France), Baptiste Brossier (EURECOM, France), Jorge Esteban Gamboa Gamboa (EURECOM, France), Thomas Lardy (EURECOM, France), Hemlata Tak (EURECOM, France), Orhan Ermis (EURECOM, France), Madhu R. Kamble (EURECOM, France), Jose Patino (EURECOM, France), Nicholas Evans (EURECOM, France), Melek Önen (EURECOM, France) and Massimiliano Todisco (EURECOM, France)
- 13:30 Tue-A-SS-1-2 1783 Configurable Privacy-Preserving Automatic Speech Recognition, Ranya Aloufi (Imperial College London, UK), Hamed Haddadi (Imperial College London, UK) and David Boyle (Imperial College London, UK)
- 13:30 Tue-A-SS-1-3 27 Adjunct-Emeritus Distillation for Semi-Supervised Language Model Adaptation, Scott Novotney (Amazon, USA), Yile Gu (Amazon, USA) and Ivan Bulyko (Amazon, USA)
- 13:30 Tue-A-SS-1-4 153 Communication-Efficient Agnostic Federated Averaging, Jae Ro (Google, USA), Mingqing Chen (Google, USA), Rajiv Mathews (Google, USA), Mehryar Mohri (Google, USA) and Ananda Theertha Suresh (Google, USA)
- 13:30 Tue-A-SS-1-5 262 Privacy-Preserving Feature Extraction for Cloud-Based Wake Word Verification, Timm Koppelmann (Ruhr-Universität Bochum, Germany), Alexandru Nelus (Ruhr-Universität Bochum, Germany), Lea Schönherr (Ruhr-Universität Bochum, Germany), Dorothea Kolossa (Ruhr-Universität Bochum, Germany) and Rainer Martin (Ruhr-Universität Bochum, Germany)
- 13:30 Tue-A-SS-1-6 640 PATE-AAE: Incorporating Adversarial Autoencoder into Private Aggregation of Teacher Ensembles for Spoken Command Classification, Chao-Han Huck Yang (Georgia Tech, USA), Sabato Marco Siniscalchi (Georgia Tech, USA) and Chin-Hui Lee (Georgia Tech, USA)
- 13:30 Tue-A-SS-1-7 794 Continual Learning for Fake Audio Detection, Haoxin Ma (CAS, China), Jiangyan Yi (CAS, China), Jianhua Tao (CAS, China), Ye Bai (CAS, China), Zhengkun Tian (CAS, China) and Chenglong Wang (CAS, China)
- 13:30 Tue-A-SS-1-8 1188 Evaluating the Vulnerability of End-to-End Automatic Speech Recognition Models to Membership Inference Attacks, Muhammad A. Shah (Amazon, USA), Joseph Szurley (Amazon, USA), Markus Mueller (Amazon, USA), Athanasios Mouchtaris (Amazon, USA) and Jasha Droppo (Amazon, USA)
- 13:30 Tue-A-SS-1-9 1882 SynthASR: Unlocking Synthetic Data for Speech Recognition, Amin Fazel (Amazon, USA), Wei Yang (Amazon, USA), Yulan Liu (Amazon, UK), Roberto Barra-Chicote (Amazon, UK), Yixiong Meng (Amazon, USA), Roland Maas (Amazon, USA) and Jasha Droppo (Amazon, USA)
Tue-A-SS-2 Tuesday, August 31, 13:30-15:30 Special-Virtual: The First DiCOVA Challenge: Diagnosis of COVid-19 using Acoustics
- 13:30 Introduction
- 13:35 Short presentations of papers
- 14:30 Tue-A-SS-2-1 74 DiCOVA Challenge: Dataset, Task, and Baseline System for COVID-19 Diagnosis Using Acoustics, Ananya Muguli (Indian Institute of Science, India), Lancelot Pinto (P.D. Hinduja Hospital, India), Nirmala R. (Indian Institute of Science, India), Neeraj Sharma (Indian Institute of Science, India), Prashant Krishnan (Indian Institute of Science, India), Prasanta Kumar Ghosh (Indian Institute of Science, India), Rohit Kumar (Indian Institute of Science, India), Shrirama Bhat (KMC Hospital, India), Srikanth Raj Chetupalli (Indian Institute of Science, India), Sriram Ganapathy (Indian Institute of Science, India), Shreyas Ramoji (Indian Institute of Science, India) and Viral Nanda (P.D. Hinduja Hospital, India)
- 14:30 Tue-A-SS-2-2 1062 PANACEA Cough Sound-Based Diagnosis of COVID-19 for the DiCOVA 2021 Challenge, Madhu R. Kamble (EURECOM, France), Jose A. Gonzalez-Lopez (Universidad de Granada, Spain), Teresa Grau (Biometric Vox, Spain), Juan M. Espin (Biometric Vox, Spain), Lorenzo Cascioli (EURECOM, France), Yiqing Huang (EURECOM, France), Alejandro Gomez-Alanis (Universidad de Granada, Spain), Jose Patino (EURECOM, France), Roberto Font (Biometric Vox, Spain), Antonio M. Peinado (Universidad de Granada, Spain), Angel M. Gomez (Universidad de Granada, Spain), Nicholas Evans (EURECOM, France), Maria A. Zuluaga (EURECOM, France) and Massimiliano Todisco (EURECOM, France)
- 14:30 Tue-A-SS-2-3 1267 Recognising Covid-19 from Coughing Using Ensembles of SVMs and LSTMs with Handcrafted and Deep Audio Features, Vincent Karas (Universität Augsburg, Germany) and Björn W. Schuller (Universität Augsburg, Germany)
- 14:30 Tue-A-SS-2-4 2191 Detecting COVID-19 from Audio Recording of Coughs Using Random Forests and Support Vector Machines, Isabella Södergren (Luleå University of Technology, Sweden), Maryam Pahlavan Nodeh (Luleå University of Technology, Sweden), Prakash Chandra Chhipa (Luleå University of Technology, Sweden), Konstantina Nikolaidou (Luleå University of Technology, Sweden) and György Kovács (Luleå University of Technology, Sweden)
- 14:30 Tue-A-SS-2-5 497 Diagnosis of COVID-19 Using Auditory Acoustic Cues, Rohan Kumar Das (NUS, Singapore), Maulik Madhavi (NUS, Singapore) and Haizhou Li (NUS, Singapore)
- 14:30 Tue-A-SS-2-6 799 Classification of COVID-19 from Cough Using Autoregressive Predictive Coding Pretraining and Spectral Data Augmentation, John Harvill (University of Illinois at Urbana-Champaign, USA), Yash R. Wani (University of Chicago, USA), Mark Hasegawa-Johnson (University of Illinois at Urbana-Champaign, USA), Narendra Ahuja (University of Illinois at Urbana-Champaign, USA), David Beiser (University of Chicago, USA) and David Chestek (University of Illinois at Chicago, USA)
- 14:30 Tue-A-SS-2-7 811 The DiCOVA 2021 Challenge — An Encoder-Decoder Approach for COVID-19 Recognition from Coughing Audio, Gauri Deshpande (TCS, India) and Björn W. Schuller (Universität Augsburg, Germany)
- 14:30 Tue-A-SS-2-8 1031 COVID-19 Detection from Spectral Features on the DiCOVA Dataset, Kotra Venkata Sai Ritwik (NITK Surathkal, India), Shareef Babu Kalluri (NITK Surathkal, India) and Deepu Vijayasenan (NITK Surathkal, India)
- 14:30 Tue-A-SS-2-9 1052 Cough-Based COVID-19 Detection with Contextual Attention Convolutional Neural Networks and Gender Information, Adria Mallol-Ragolta (Universität Augsburg, Germany), Helena Cuesta (Universitat Pompeu Fabra, Spain), Emilia Gómez (Universitat Pompeu Fabra, Spain) and Björn W. Schuller (Universität Augsburg, Germany)
- 14:30 Tue-A-SS-2-10 1249 Contrastive Learning of Cough Descriptors for Automatic COVID-19 Preliminary Diagnosis, Swapnil Bhosale (TCS, India), Upasana Tiwari (TCS, India), Rupayan Chakraborty (TCS, India) and Sunil Kumar Kopparapu (TCS, India)
- 14:30 Tue-A-SS-2-11 2197 Investigating Feature Selection and Explainability for COVID-19 Diagnostics from Cough Sounds, Flavio Avila (Verisk Analytics, USA), Amir H. Poorjam (Verisk Analytics, USA), Deepak Mittal (Verisk Analytics, USA), Charles Dognin (Verisk Analytics, USA), Ananya Muguli (Indian Institute of Science, India), Rohit Kumar (Indian Institute of Science, India), Srikanth Raj Chetupalli (Indian Institute of Science, India), Sriram Ganapathy (Indian Institute of Science, India) and Maneesh Singh (Verisk Analytics, USA)
Tue-A-S&T-1 Tuesday, August 31, 13:30-15:30 Show and Tell: Show and Tell 1
- 13:30 Tue-A-S&T-1-1 ST01 Application for Detecting Depression, Parkinson’s Disease and Dysphonic Speech, Gábor Kiss (BME, Hungary), Dávid Sztahó (BME, Hungary) and Miklós Gábriel Tulics (BME, Hungary)
- 13:30 Tue-A-S&T-1-2 ST02 Beey: More Than a Speech-to-Text Editor, Lenka Weingartová (NEWTON Technologies, Czech Republic), Veronika Volná (NEWTON Technologies, Czech Republic) and Ewa Balejová (NEWTON Technologies, Czech Republic)
- 13:30 Tue-A-S&T-1-3 ST03 Downsizing of Vocal-Tract Models to Line up Variations and Reduce Manufacturing Costs, Takayuki Arai (Sophia University, Japan)
- 13:30 Tue-A-S&T-1-4 ST04 ROXANNE Research Platform: Automate Criminal Investigations, Maël Fabien (Idiap Research Institute, Switzerland), Shantipriya Parida (Idiap Research Institute, Switzerland), Petr Motlicek (Idiap Research Institute, Switzerland), Dawei Zhu (Universität des Saarlandes, Germany), Aravind Krishnan (Universität des Saarlandes, Germany) and Hoang H. Nguyen (Leibniz Universität Hannover, Germany)
- 13:30 Tue-A-S&T-1-5 ST05 The LIUM Human Active Correction Platform for Speaker Diarization, Alexandre Flucha (LIUM (EA 4023), France), Anthony Larcher (LIUM (EA 4023), France), Ambuj Mehrish (LIUM (EA 4023), France), Sylvain Meignier (LIUM (EA 4023), France), Florian Plaut (LIUM (EA 4023), France), Nicolas Poupon (LIUM (EA 4023), France), Yevhenii Prokopalo (LIUM (EA 4023), France), Adrien Puertolas (LIUM (EA 4023), France), Meysam Shamsi (LIUM (EA 4023), France) and Marie Tahon (LIUM (EA 4023), France)
- 13:30 Tue-A-S&T-1-6 ST06 On-Device Streaming Transformer-Based End-to-End Speech Recognition, Yoo Rhee Oh (ETRI, Korea) and Kiyoung Park (ETRI, Korea)
- 13:30 Tue-A-S&T-1-7 ST07 Advanced Semi-Blind Speaker Extraction and Tracking Implemented in Experimental Device with Revolving Dense Microphone Array, J. Čmejla (Technical University of Liberec, Czech Republic), T. Kounovský (Technical University of Liberec, Czech Republic), J. Janský (Technical University of Liberec, Czech Republic), Jiri Malek (Technical University of Liberec, Czech Republic), M. Rozkovec (Technical University of Liberec, Czech Republic) and Z. Koldovský (Technical University of Liberec, Czech Republic)
Tue-E-O-1 Tuesday, August 31, 19:00-21:00 In-person Oral: ASR Technologies and systems
- 19:00 Tue-E-O-1-1 1465 Information Retrieval for ZeroSpeech 2021: The Submission by University of Wroclaw, Jan Chorowski (University of Wrocław, Poland), Grzegorz Ciesielski (University of Wrocław, Poland), Jarosław Dzikowski (University of Wrocław, Poland), Adrian Łańcucki (NVIDIA, Poland), Ricard Marxer (LIS (UMR 7020), France), Mateusz Opala (University of Wrocław, Poland), Piotr Pusz (University of Wrocław, Poland), Paweł Rychlikowski (University of Wrocław, Poland) and Michał Stypułkowski (University of Wrocław, Poland)
- 19:20 Tue-E-O-1-2 1544 Aligned Contrastive Predictive Coding, Jan Chorowski (University of Wrocław, Poland), Grzegorz Ciesielski (University of Wrocław, Poland), Jarosław Dzikowski (University of Wrocław, Poland), Adrian Łańcucki (NVIDIA, Poland), Ricard Marxer (LIS (UMR 7020), France), Mateusz Opala (University of Wrocław, Poland), Piotr Pusz (University of Wrocław, Poland), Paweł Rychlikowski (University of Wrocław, Poland) and Michał Stypułkowski (University of Wrocław, Poland)
- 19:40 Tue-E-O-1-3 1814 Neural Text Denormalization for Speech Transcripts, Benjamin Suter (Spitch, Switzerland) and Josef Novak (Spitch, Switzerland)
- 20:00 Tue-E-O-1-4 2011 Fearless Steps Challenge Phase-3 (FSC P3): Advancing SLT for Unseen Channel and Mission Data Across NASA Apollo Audio, Aditya Joglekar (University of Texas at Dallas, USA), Seyed Omid Sadjadi (NIST, USA), Meena Chandra-Shekar (University of Texas at Dallas, USA), Christopher Cieri (University of Pennsylvania, USA) and John H.L. Hansen (University of Texas at Dallas, USA)
Tue-E-O-2 Tuesday, August 31, 19:00-21:00 In-person Oral: Phonation and voicing
- 19:00 Tue-E-O-2-1 452 Voice Quality in Verbal Irony: Electroglottographic Analyses of Ironic Utterances in Standard Austrian German, Hannah Leykum (Austrian Academy of Sciences, Austria)
- 19:20 Tue-E-O-2-2 939 Synchronic Fortition in Five Romance Languages? A Large Corpus-Based Study of Word-Initial Devoicing, Mathilde Hutin (LISN (UMR 9015), France), Yaru Wu (LISN (UMR 9015), France), Adèle Jatteau (STL (UMR 8163), France), Ioana Vasilescu (LISN (UMR 9015), France), Lori Lamel (LISN (UMR 9015), France) and Martine Adda-Decker (LISN (UMR 9015), France)
- 19:40 Tue-E-O-2-3 1101 Glottal Stops in Upper Sorbian: A Data-Driven Approach, Ivan Kraljevski (Fraunhofer IKTS, Germany), Maria Paola Bissiri (Università dell’Insubria, Italy), Frank Duckhorn (Fraunhofer IKTS, Germany), Constanze Tschoepe (Fraunhofer IKTS, Germany) and Matthias Wolff (Brandenburgische Technische Universität, Germany)
- 20:00 Tue-E-O-2-4 1357 Cue Interaction in the Perception of Prosodic Prominence: The Role of Voice Quality, Bogdan Ludusan (Universität Bielefeld, Germany), Petra Wagner (Universität Bielefeld, Germany) and Marcin Włodarczak (Stockholm University, Sweden)
- 20:20 Tue-E-O-2-5 1417 Glottal Sounds in Korebaju, Jenifer Vega Rodriguez (GIPSA-lab (UMR 5216), France) and Nathalie Vallée (GIPSA-lab (UMR 5216), France)
- 20:40 Tue-E-O-2-6 1765 Automatic Classification of Phonation Types in Spontaneous Speech: Towards a New Workflow for the Characterization of Speakers’ Voice Quality, Anaïs Chanclu (LIA (EA 4128), France), Imen Ben Amor (LIA (EA 4128), France), Cédric Gendrot (LPP (UMR 7018), France), Emmanuel Ferragne (LPP (UMR 7018), France) and Jean-François Bonastre (LIA (EA 4128), France)
Tue-E-O-3 Tuesday, August 31, 19:00-21:00 In-person Oral: Health and Affect I
- 19:00 Tue-E-O-3-1 26 Measuring Voice Quality Parameters After Speaker Pseudonymization, Rob J.J.H. van Son (Netherlands Cancer Institute, The Netherlands)
- 19:20 Tue-E-O-3-2 567 Audio-Visual Recognition of Emotional Engagement of People with Dementia, Lars Steinert (Universität Bremen, Germany), Felix Putze (Universität Bremen, Germany), Dennis Küster (Universität Bremen, Germany) and Tanja Schultz (Universität Bremen, Germany)
- 19:40 Tue-E-O-3-3 1771 Speaking Corona? Human and Machine Recognition of COVID-19 from Voice, Pascal Hecker (audEERING, Germany), Florian B. Pokorny (Universität Augsburg, Germany), Katrin D. Bartl-Pokorny (Universität Augsburg, Germany), Uwe Reichel (audEERING, Germany), Zhao Ren (Universität Augsburg, Germany), Simone Hantke (audEERING, Germany), Florian Eyben (audEERING, Germany), Dagmar M. Schuller (audEERING, Germany), Bert Arnrich (Universität Potsdam, Germany) and Björn W. Schuller (audEERING, Germany)
- 20:00 Tue-E-O-3-4 1891 Acoustic-Prosodic, Lexical and Demographic Cues to Persuasiveness in Competitive Debate Speeches, Huyen Nguyen (Universität Hamburg, Germany), Ralph Vente (CUNY Hunter College, USA), David Lupea (NYU, USA), Sarah Ita Levitan (CUNY Hunter College, USA) and Julia Hirschberg (Columbia University, USA)
Tue-E-V-1 Tuesday, August 31, 19:00-21:00 Virtual: Robust Speaker Recognition
- 19:00 Tue-E-V-1-1 33 Unsupervised Bayesian Adaptation of PLDA for Speaker Verification, Bengt J. Borgström (MIT Lincoln Laboratory, USA)
- 19:00 Tue-E-V-1-2 235 The DKU-Duke-Lenovo System Description for the Fearless Steps Challenge Phase III, Weiqing Wang (Duke Kunshan University, China), Danwei Cai (Duke Kunshan University, China), Jin Wang (Lenovo, China), Qingjian Lin (Lenovo, China), Xuyang Wang (Lenovo, China), Mi Hong (Lenovo, China) and Ming Li (Duke Kunshan University, China)
- 19:00 Tue-E-V-1-3 405 Improved Meta-Learning Training for Speaker Verification, Yafeng Chen (USTC, China), Wu Guo (USTC, China) and Bin Gu (USTC, China)
- 19:00 Tue-E-V-1-4 482 Variational Information Bottleneck Based Regularization for Speaker Recognition, Dan Wang (WHUT, China), Yuanjie Dong (WHUT, China), Yaxing Li (WHUT, China), Yunfei Zi (WHUT, China), Zhihui Zhang (WHUT, China), Xiaoqi Li (WHUT, China) and Shengwu Xiong (WHUT, China)
- 19:00 Tue-E-V-1-5 541 Out of a Hundred Trials, How Many Errors Does Your Speaker Verifier Make?, Niko Brümmer (Phonexia, South Africa), Luciana Ferrer (UBA-CONICET ICC, Argentina) and Albert Swart (Phonexia, South Africa)
- 19:00 Tue-E-V-1-6 646 SpeakerStew: Scaling to Many Languages with a Triaged Multilingual Text-Dependent and Text-Independent Speaker Verification System, Roza Chojnacka (Google, USA), Jason Pelecanos (Google, USA), Quan Wang (Google, USA) and Ignacio Lopez Moreno (Google, USA)
- 19:00 Tue-E-V-1-7 966 AntVoice Neural Speaker Embedding System for FFSVC 2020, Zhiming Wang (Ant, China), Furong Xu (Ant, China), Kaisheng Yao (Ant, China), Yuan Cheng (Ant, China), Tao Xiong (Ant, China) and Huijia Zhu (Ant, China)
- 19:00 Tue-E-V-1-8 1216 Gradient Regularization for Noise-Robust Speaker Verification, Jianchen Li (Harbin Institute of Technology, China), Jiqing Han (Harbin Institute of Technology, China) and Hongwei Song (Harbin Institute of Technology, China)
- 19:00 Tue-E-V-1-9 1502 Deep Feature CycleGANs: Speaker Identity Preserving Non-Parallel Microphone-Telephone Domain Adaptation for Speaker Verification, Saurabh Kataria (Johns Hopkins University, USA), Jesús Villalba (Johns Hopkins University, USA), Piotr Żelasko (Johns Hopkins University, USA), Laureano Moro-Velázquez (Johns Hopkins University, USA) and Najim Dehak (Johns Hopkins University, USA)
- 19:00 Tue-E-V-1-10 1935 Scaling Effect of Self-Supervised Speech Models, Jie Pu (University of Cambridge, UK), Yuguang Yang (Amazon, USA), Ruirui Li (Amazon, USA), Oguz Elibol (Amazon, USA) and Jasha Droppo (Amazon, USA)
- 19:00 Tue-E-V-1-11 1978 Joint Feature Enhancement and Speaker Recognition with Multi-Objective Task-Oriented Network, Yibo Wu (Tianjin University, China), Longbiao Wang (Tianjin University, China), Kong Aik Lee (A*STAR, Singapore), Meng Liu (Tianjin University, China) and Jianwu Dang (Tianjin University, China)
- 19:00 Tue-E-V-1-12 1980 Multi-Level Transfer Learning from Near-Field to Far-Field Speaker Verification, Li Zhang (Northwestern Polytechnical University, China), Qing Wang (Northwestern Polytechnical University, China), Kong Aik Lee (A*STAR, Singapore), Lei Xie (Northwestern Polytechnical University, China) and Haizhou Li (NUS, Singapore)
- 19:00 Tue-E-V-1-13 1070 Speaker Anonymisation Using the McAdams Coefficient, Jose Patino (EURECOM, France), Natalia Tomashenko (LIA (EA 4128), France), Massimiliano Todisco (EURECOM, France), Andreas Nautsch (EURECOM, France) and Nicholas Evans (EURECOM, France)
Tue-E-V-2 Tuesday, August 31, 19:00-21:00 Virtual: Source separation, dereverberation and echo cancellation
- 19:00 Tue-E-V-2-1 366 Multi-Stream Gated and Pyramidal Temporal Convolutional Neural Networks for Audio-Visual Speech Separation in Multi-Talker Environments, Yiyu Luo (BIT, China), Jing Wang (BIT, China), Liang Xu (BIT, China) and Lidong Yang (IMUST, China)
- 19:00 Tue-E-V-2-2 481 TeCANet: Temporal-Contextual Attention Network for Environment-Aware Speech Dereverberation, Helin Wang (Peking University, China), Bo Wu (Tencent, China), Lianwu Chen (Tencent, China), Meng Yu (Tencent, USA), Jianwei Yu (Tencent, China), Yong Xu (Tencent, USA), Shi-Xiong Zhang (Tencent, USA), Chao Weng (Tencent, China), Dan Su (Tencent, China) and Dong Yu (Tencent, USA)
- 19:00 Tue-E-V-2-3 538 Residual Echo and Noise Cancellation with Feature Attention Module and Multi-Domain Loss Function, Jianjun Gu (CAS, China), Longbiao Cheng (CAS, China), Xingwei Sun (CAS, China), Junfeng Li (CAS, China) and Yonghong Yan (CAS, China)
- 19:00 Tue-E-V-2-4 570 MIMO Self-Attentive RNN Beamformer for Multi-Speaker Speech Separation, Xiyun Li (CAS, China), Yong Xu (Tencent, USA), Meng Yu (Tencent, USA), Shi-Xiong Zhang (Tencent, USA), Jiaming Xu (CAS, China), Bo Xu (CAS, China) and Dong Yu (Tencent, USA)
- 19:00 Tue-E-V-2-5 694 Personalized PercepNet: Real-Time, Low-Complexity Target Voice Separation and Enhancement, Ritwik Giri (Amazon, USA), Shrikant Venkataramani (Amazon, USA), Jean-Marc Valin (Amazon, Canada), Umut Isik (Amazon, USA) and Arvindh Krishnaswamy (Amazon, USA)
- 19:00 Tue-E-V-2-6 889 Scene-Agnostic Multi-Microphone Speech Dereverberation, Yochai Yemini (Bar-Ilan University, Israel), Ethan Fetaya (Bar-Ilan University, Israel), Haggai Maron (NVIDIA, Israel) and Sharon Gannot (Bar-Ilan University, Israel)
- 19:00 Tue-E-V-2-7 1029 Manifold-Aware Deep Clustering: Maximizing Angles Between Embedding Vectors Based on Regular Simplex, Keitaro Tanaka (Waseda University, Japan), Ryosuke Sawata (Sony, Japan) and Shusuke Takahashi (Sony, Japan)
- 19:00 Tue-E-V-2-8 1508 A Deep Learning Approach to Multi-Channel and Multi-Microphone Acoustic Echo Cancellation, Hao Zhang (Ohio State University, USA) and DeLiang Wang (Ohio State University, USA)
- 19:00 Tue-E-V-2-9 1950 Joint Online Multichannel Acoustic Echo Cancellation, Speech Dereverberation and Source Separation, Yueyue Na (Alibaba, China), Ziteng Wang (Alibaba, China), Zhang Liu (Alibaba, China), Biao Tian (Alibaba, China) and Qiang Fu (Alibaba, China)
- 19:00 Tue-E-V-2-10 2253 Should We Always Separate?: Switching Between Enhanced and Observed Signals for Overlapping Speech Recognition, Hiroshi Sato (NTT, Japan), Tsubasa Ochiai (NTT, Japan), Marc Delcroix (NTT, Japan), Keisuke Kinoshita (NTT, Japan), Takafumi Moriya (NTT, Japan) and Naoyuki Kamo (NTT, Japan)
Tue-E-V-3 Tuesday, August 31, 19:00-21:00 Virtual: Speech signal analysis and representation I
- 19:00 Tue-E-V-3-1 1375 Estimating Articulatory Movements in Speech Production with Transformer Networks, Sathvik Udupa (Indian Institute of Science, India), Anwesha Roy (Indian Institute of Science, India), Abhayjeet Singh (Indian Institute of Science, India), Aravind Illa (Amazon, India) and Prasanta Kumar Ghosh (Indian Institute of Science, India)
- 19:00 Tue-E-V-3-2 300 Unsupervised Multi-Target Domain Adaptation for Acoustic Scene Classification, Dongchao Yang (Peking University, China), Helin Wang (Peking University, China) and Yuexian Zou (Peking University, China)
- 19:00 Tue-E-V-3-3 47 Speech Decomposition Based on a Hybrid Speech Model and Optimal Segmentation, Alfredo Esquivel Jaramillo (Aalborg University, Denmark), Jesper Kjær Nielsen (Aalborg University, Denmark) and Mads Græsbøll Christensen (Aalborg University, Denmark)
- 19:00 Tue-E-V-3-4 1066 Dropout Regularization for Self-Supervised Learning of Transformer Encoder Speech Representation, Jian Luo (Ping An Technology, China), Jianzong Wang (Ping An Technology, China), Ning Cheng (Ping An Technology, China) and Jing Xiao (Ping An Technology, China)
- 19:00 Tue-E-V-3-5 1307 Noise Robust Pitch Stylization Using Minimum Mean Absolute Error Criterion, Chiranjeevi Yarra (IIIT Hyderabad, India) and Prasanta Kumar Ghosh (Indian Institute of Science, India)
- 19:00 Tue-E-V-3-6 1341 An Attribute-Aligned Strategy for Learning Speech Representation, Yu-Lin Huang (National Tsing Hua University, Taiwan), Bo-Hao Su (National Tsing Hua University, Taiwan), Y.-W. Peter Hong (National Tsing Hua University, Taiwan) and Chi-Chun Lee (National Tsing Hua University, Taiwan)
- 19:00 Tue-E-V-3-7 1429 Raw Speech-to-Articulatory Inversion by Temporal Filtering and Decimation, Abdolreza Sabzi Shahrebabaki (NTNU, Norway), Sabato Marco Siniscalchi (NTNU, Norway) and Torbjørn Svendsen (NTNU, Norway)
- 19:00 Tue-E-V-3-8 1690 Unsupervised Training of a DNN-Based Formant Tracker, Jason Lilley (Nemours, USA) and H. Timothy Bunnell (Nemours, USA)
- 19:00 Tue-E-V-3-9 1775 SUPERB: Speech Processing Universal PERformance Benchmark, Shu-wen Yang (National Taiwan University, Taiwan), Po-Han Chi (National Taiwan University, Taiwan), Yung-Sung Chuang (National Taiwan University, Taiwan), Cheng-I Jeff Lai (MIT, USA), Kushal Lakhotia (Facebook, USA), Yist Y. Lin (National Taiwan University, Taiwan), Andy T. Liu (National Taiwan University, Taiwan), Jiatong Shi (Johns Hopkins University, USA), Xuankai Chang (Carnegie Mellon University, USA), Guan-Ting Lin (National Taiwan University, Taiwan), Tzu-Hsien Huang (National Taiwan University, Taiwan), Wei-Cheng Tseng (National Taiwan University, Taiwan), Ko-tik Lee (National Taiwan University, Taiwan), Da-Rong Liu (National Taiwan University, Taiwan), Zili Huang (Johns Hopkins University, USA), Shuyan Dong (Amazon, USA), Shang-Wen Li (Amazon, USA), Shinji Watanabe (Carnegie Mellon University, USA), Abdelrahman Mohamed (Facebook, USA) and Hung-yi Lee (National Taiwan University, Taiwan)
- 19:00 Tue-E-V-3-10 1841 Synchronising Speech Segments with Musical Beats in Mandarin and English Singing, Cong Zhang (Radboud Universiteit, The Netherlands) and Jian Zhu (University of Michigan, USA)
- 19:00 Tue-E-V-3-11 2070 FRILL: A Non-Semantic Speech Embedding for Mobile Devices, Jacob Peplinski (University of Washington, USA), Joel Shor (Google, Japan), Sachin Joglekar (Google, USA), Jake Garrison (Google, USA) and Shwetak Patel (University of Washington, USA)
- 19:00 Tue-E-V-3-12 2164 Pitch Contour Separation from Overlapping Speech, Hiroki Mori (Utsunomiya University, Japan)
- 19:00 Tue-E-V-3-13 347 Do Sound Event Representations Generalize to Other Audio Tasks? A Case Study in Audio Transfer Learning, Anurag Kumar (Facebook, USA), Yun Wang (Facebook, USA), Vamsi Krishna Ithapu (Facebook, USA) and Christian Fuegen (Facebook, USA)
Tue-E-V-4 Tuesday, August 31, 19:00-21:00 Virtual: Spoken Language Understanding I
- 19:00 Tue-E-V-4-1 117 Data Augmentation for Spoken Language Understanding via Pretrained Language Models, Baolin Peng (Microsoft, USA), Chenguang Zhu (Microsoft, USA), Michael Zeng (Microsoft, USA) and Jianfeng Gao (Microsoft, USA)
- 19:00 Tue-E-V-4-2 793 FANS: Fusing ASR and NLU for On-Device SLU, Martin Radfar (Amazon, USA), Athanasios Mouchtaris (Amazon, USA), Siegfried Kunzmann (Amazon, USA) and Ariya Rastrow (Amazon, USA)
- 19:00 Tue-E-V-4-3 1569 Sequential End-to-End Intent and Slot Label Classification and Localization, Yiran Cao (University of Waterloo, Canada), Nihal Potdar (University of Waterloo, Canada) and Anderson R. Avila (Huawei Technologies, Canada)
- 19:00 Tue-E-V-4-4 1877 DEXTER: Deep Encoding of External Knowledge for Named Entity Recognition in Virtual Assistants, Deepak Muralidharan (Apple, USA), Joel Ruben Antony Moniz (Apple, USA), Weicheng Zhang (Apple, USA), Stephen Pulman (Apple, UK), Lin Li (Apple, USA), Megan Barnes (University of Washington, USA), Jingjing Pan (Apple, USA), Jason Williams (Apple, USA) and Alex Acero (Apple, USA)
- 19:00 Tue-E-V-4-5 95 A Context-Aware Hierarchical BERT Fusion Network for Multi-Turn Dialog Act Detection, Ting-Wei Wu (Georgia Tech, USA), Ruolin Su (Georgia Tech, USA) and Biing-Hwang Juang (Georgia Tech, USA)
- 19:00 Tue-E-V-4-6 234 Pre-Training for Spoken Language Understanding with Joint Textual and Phonetic Representation Learning, Qian Chen (Alibaba, China), Wen Wang (Alibaba, China) and Qinglin Zhang (Alibaba, China)
- 19:00 Tue-E-V-4-7 580 Predicting Temporal Performance Drop of Deployed Production Spoken Language Understanding Models, Quynh Do (Amazon, Germany), Judith Gaspers (Amazon, Germany), Daniil Sorokin (Amazon, Germany) and Patrick Lehnen (Amazon, Germany)
- 19:00 Tue-E-V-4-8 1460 Integrating Dialog History into End-to-End Spoken Language Understanding Systems, Jatin Ganhotra (IBM, USA), Samuel Thomas (IBM, USA), Hong-Kwang J. Kuo (IBM, USA), Sachindra Joshi (IBM, USA), George Saon (IBM, USA), Zoltán Tüske (IBM, USA) and Brian Kingsbury (IBM, USA)
- 19:00 Tue-E-V-4-9 1463 Coreference Augmentation for Multi-Domain Task-Oriented Dialogue State Tracking, Ting Han (University of Illinois at Chicago, USA), Chongxuan Huang (Huawei Technologies, China) and Wei Peng (Huawei Technologies, China)
- 19:00 Tue-E-V-4-10 1537 Rethinking End-to-End Evaluation of Decomposable Tasks: A Case Study on Spoken Language Understanding, Siddhant Arora (Carnegie Mellon University, USA), Alissa Ostapenko (Carnegie Mellon University, USA), Vijay Viswanathan (Carnegie Mellon University, USA), Siddharth Dalmia (Carnegie Mellon University, USA), Florian Metze (Carnegie Mellon University, USA), Shinji Watanabe (Carnegie Mellon University, USA) and Alan W. Black (Carnegie Mellon University, USA)
Tue-E-V-5 Tuesday, August 31, 19:00-21:00 Virtual: Topics in ASR: Adaptation, transfer learning, children's speech, and low-resource settings
- 19:00 Tue-E-V-5-1 1162 Semantic Data Augmentation for End-to-End Mandarin Speech Recognition, Jianwei Sun (KE, China), Zhiyuan Tang (KE, China), Hengxin Yin (KE, China), Wei Wang (KE, China), Xi Zhao (KE, China), Shuaijiang Zhao (KE, China), Xiaoning Lei (KE, China), Wei Zou (KE, China) and Xiangang Li (KE, China)
- 19:00 Tue-E-V-5-2 1075 Layer-Wise Fast Adaptation for End-to-End Multi-Accent Speech Recognition, Xun Gong (SJTU, China), Yizhou Lu (SJTU, China), Zhikai Zhou (SJTU, China) and Yanmin Qian (SJTU, China)
- 19:00 Tue-E-V-5-3 1974 Low Resource German ASR with Untranscribed Data Spoken by Non-Native Children — INTERSPEECH 2021 Shared Task SPAPL System, Jinhan Wang (University of California at Los Angeles, USA), Yunzheng Zhu (University of California at Los Angeles, USA), Ruchao Fan (University of California at Los Angeles, USA), Wei Chu (PAII, USA) and Abeer Alwan (University of California at Los Angeles, USA)
- 19:00 Tue-E-V-5-4 318 Robust Continuous On-Device Personalization for Automatic Speech Recognition, Khe Chai Sim (Google, USA), Angad Chandorkar (Google, USA), Fan Gao (Google, USA), Mason Chua (Google, USA), Tsendsuren Munkhdalai (Google, USA) and Françoise Beaufays (Google, USA)
- 19:00 Tue-E-V-5-5 467 Speaker Normalization Using Joint Variational Autoencoder, Shashi Kumar (Samsung, India), Shakti P. Rath (Reverie Language Technologies, India) and Abhishek Pandey (Samsung, India)
- 19:00 Tue-E-V-5-6 1104 The TAL System for the INTERSPEECH2021 Shared Task on Automatic Speech Recognition for Non-Native Childrens Speech, Gaopeng Xu (TAL, China), Song Yang (TAL, China), Lu Ma (TAL, China), Chengfei Li (TAL, China) and Zhongqin Wu (TAL, China)
- 19:00 Tue-E-V-5-7 1679 On-the-Fly Aligned Data Augmentation for Sequence-to-Sequence ASR, Tsz Kin Lam (Universität Heidelberg, Germany), Mayumi Ohta (Universität Heidelberg, Germany), Shigehiko Schamoni (Universität Heidelberg, Germany) and Stefan Riezler (Universität Heidelberg, Germany)
- 19:00 Tue-E-V-5-8 1843 Zero-Shot Cross-Lingual Phonetic Recognition with External Language Embedding, Heting Gao (University of Illinois at Urbana-Champaign, USA), Junrui Ni (University of Illinois at Urbana-Champaign, USA), Yang Zhang (MIT-IBM Watson AI Lab, USA), Kaizhi Qian (MIT-IBM Watson AI Lab, USA), Shiyu Chang (MIT-IBM Watson AI Lab, USA) and Mark Hasegawa-Johnson (University of Illinois at Urbana-Champaign, USA)
- 19:00 Tue-E-V-5-9 1884 Rapid Speaker Adaptation for Conformer Transducer: Attention and Bias Are All You Need, Yan Huang (Microsoft, USA), Guoli Ye (Microsoft, USA), Jinyu Li (Microsoft, USA) and Yifan Gong (Microsoft, USA)
- 19:00 Tue-E-V-5-10 1888 Best of Both Worlds: Robust Accented Speech Recognition with Adversarial Transfer Learning, Nilaksh Das (Georgia Tech, USA), Sravan Bodapati (Amazon, USA), Monica Sunkara (Amazon, USA), Sundararajan Srinivasan (Amazon, USA) and Duen Horng Chau (Georgia Tech, USA)
- 19:00 Tue-E-V-5-11 2053 Extending Pronunciation Dictionary with Automatically Detected Word Mispronunciations to Improve PAII’s System for Interspeech 2021 Non-Native Child English Close Track ASR Challenge, Wei Chu (PAII, USA), Peng Chang (PAII, USA) and Jing Xiao (PAII, USA)
Tue-E-V-6 Tuesday, August 31, 19:00-21:00 Virtual: Voice Conversion and Adaptation I
- 19:00 Tue-E-V-6-1 137 CVC: Contrastive Learning for Non-Parallel Voice Conversion, Tingle Li (Tsinghua University, China), Yichen Liu (Tsinghua University, China), Chenxu Hu (Tsinghua University, China) and Hang Zhao (Tsinghua University, China)
- 19:00 Tue-E-V-6-2 208 A Preliminary Study of a Two-Stage Paradigm for Preserving Speaker Identity in Dysarthric Voice Conversion, Wen-Chin Huang (Nagoya University, Japan), Kazuhiro Kobayashi (Nagoya University, Japan), Yu-Huai Peng (Academia Sinica, Taiwan), Ching-Feng Liu (Chi Mei Hospital, Taiwan), Yu Tsao (Academia Sinica, Taiwan), Hsin-Min Wang (Academia Sinica, Taiwan) and Tomoki Toda (Nagoya University, Japan)
- 19:00 Tue-E-V-6-3 221 One-Shot Voice Conversion with Speaker-Agnostic StarGAN, Sefik Emre Eskimez (Microsoft, USA), Dimitrios Dimitriadis (Microsoft, USA), Kenichi Kumatani (Microsoft, USA) and Robert Gmyr (Microsoft, USA)
- 19:00 Tue-E-V-6-4 244 Fine-Tuning Pre-Trained Voice Conversion Model for Adding New Target Speakers with Limited Data, Takeshi Koshizuka (Tokyo University of Science, Japan), Hidefumi Ohmura (Tokyo University of Science, Japan) and Kouichi Katsurada (Tokyo University of Science, Japan)
- 19:00 Tue-E-V-6-5 283 VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-Shot Voice Conversion, Disong Wang (CUHK, China), Liqun Deng (Huawei Technologies, China), Yu Ting Yeung (Huawei Technologies, China), Xiao Chen (Huawei Technologies, China), Xunying Liu (CUHK, China) and Helen Meng (CUHK, China)
- 19:00 Tue-E-V-6-6 319 StarGANv2-VC: A Diverse, Unsupervised, Non-Parallel Framework for Natural-Sounding Voice Conversion, Yinghao Aaron Li (Columbia University, USA), Ali Zare (Columbia University, USA) and Nima Mesgarani (Columbia University, USA)
- 19:00 Tue-E-V-6-7 441 Normalization Driven Zero-Shot Multi-Speaker Speech Synthesis, Neeraj Kumar (Hike, India), Srishti Goel (Hike, India), Ankur Narang (Hike, India) and Brejesh Lall (IIT Delhi, India)
- 19:00 Tue-E-V-6-8 492 StarGAN-VC+ASR: StarGAN-Based Non-Parallel Voice Conversion Regularized by Automatic Speech Recognition, Shoki Sakamoto (Ritsumeikan University, Japan), Akira Taniguchi (Ritsumeikan University, Japan), Tadahiro Taniguchi (Ritsumeikan University, Japan) and Hirokazu Kameoka (NTT, Japan)
- 19:00 Tue-E-V-6-9 506 Two-Pathway Style Embedding for Arbitrary Voice Conversion, Xuexin Xu (Xiamen University, China), Liang Shi (Xiamen University, China), Jinhui Chen (Prefectural University of Hiroshima, Japan), Xunquan Chen (Kobe University, Japan), Jie Lian (Xiamen University, China), Pingyuan Lin (Xiamen University, China), Zhihong Zhang (Xiamen University, China) and Edwin R. Hancock (University of York, UK)
- 19:00 Tue-E-V-6-10 557 Non-Parallel Any-to-Many Voice Conversion by Replacing Speaker Statistics, Yufei Liu (Tencent, China), Chengzhu Yu (Tencent, China), Wang Shuai (Tencent, China), Zhenchuan Yang (Tencent, China), Yang Chao (Tencent, China) and Weibin Zhang (SCUT, China)
- 19:00 Tue-E-V-6-11 687 Cross-Lingual Voice Conversion with a Cycle Consistency Loss on Linguistic Representation, Yi Zhou (NUS, Singapore), Xiaohai Tian (NUS, Singapore), Zhizheng Wu (Facebook, USA) and Haizhou Li (NUS, Singapore)
- 19:00 Tue-E-V-6-12 2132 Improving Robustness of One-Shot Voice Conversion with Deep Discriminative Speaker Encoder, Hongqiang Du (Northwestern Polytechnical University, China) and Lei Xie (Northwestern Polytechnical University, China)
Tue-E-SS-1 Tuesday, August 31, 19:00-21:00 Special-Hybrid: Voice quality characterization for clinical voice assessment: Voice production, acoustics, and auditory perception
- 19:00 Introduction
- 19:05 Tue-E-SS-1-1 711 Optimizing an Automatic Creaky Voice Detection Method for Australian English Speaking Females, Hannah White (Macquarie University, Australia), Joshua Penney (Macquarie University, Australia), Andy Gibson (Macquarie University, Australia), Anita Szakay (Macquarie University, Australia) and Felicity Cox (Macquarie University, Australia)
- 19:20 Tue-E-SS-1-2 729 A Comparison of Acoustic Correlates of Voice Quality Across Different Recording Devices: A Cautionary Tale, Joshua Penney (Macquarie University, Australia), Andy Gibson (Macquarie University, Australia), Felicity Cox (Macquarie University, Australia), Michael Proctor (Macquarie University, Australia) and Anita Szakay (Macquarie University, Australia)
- 19:35 Tue-E-SS-1-3 870 Investigating Voice Function Characteristics of Greek Speakers with Hearing Loss Using Automatic Glottal Source Feature Extraction, Anna Sfakianaki (University of Crete, Greece) and George P. Kafentzis (University of Crete, Greece)
- 19:50 Tue-E-SS-1-4 1507 Automated Detection of Voice Disorder in the Saarbrücken Voice Database: Effects of Pathology Subset and Audio Materials, Mark Huckvale (University College London, UK) and Catinca Buciuleac (University College London, UK)
- 20:05 Tue-E-SS-1-5 1918 Accelerometer-Based Measurements of Voice Quality in Children During Semi-Occluded Vocal Tract Exercise with a Narrow Straw in Air, Steven M. Lulich (Indiana University, USA) and Rita R. Patel (Indiana University, USA)
- 20:20 Tue-E-SS-1-6 688 Articulatory Coordination for Speech Motor Tracking in Huntington Disease, Matthew Perez (University of Michigan, USA), Amrit Romana (University of Michigan, USA), Angela Roberts (Northwestern University, USA), Noelle Carlozzi (University of Michigan, USA), Jennifer Ann Miner (University of Michigan, USA), Praveen Dayalu (University of Michigan, USA) and Emily Mower Provost (University of Michigan, USA)
- 20:35 Tue-E-SS-1-7 1540 Modeling Dysphonia Severity as a Function of Roughness and Breathiness Ratings in the GRBAS Scale, Carlos A. Ferrer (Universidad Central de Las Villas, Cuba), Efren Aragón (Universidad Central de Las Villas, Cuba), María E. Hdez-Díaz (Universiteit Antwerpen, Belgium), Marc S. de Bodt (Universiteit Antwerpen, Belgium), Roman Cmejla (Czech Technical University in Prague, Czech Republic), Marina Englert (Universidade Federal de São Paulo, Brazil), Mara Behlau (Universidade Federal de São Paulo, Brazil) and Elmar Nöth (FAU Erlangen-Nürnberg, Germany)
- 20:50 Panel discussion
Wed-M-O-1 Wednesday, September 1, 11:00-13:00 In-person Oral: Miscellaneous topics in ASR
- 11:00 Wed-M-O-1-1 462 Golos: Russian Dataset for Speech Research, Nikolay Karpov (SberBank, Russia), Alexander Denisenko (SberBank, Russia) and Fedor Minkin (SberBank, Russia)
- 11:20 Wed-M-O-1-2 643 Radically Old Way of Computing Spectra: Applications in End-to-End ASR, Samik Sadhu (Johns Hopkins University, USA) and Hynek Hermansky (Johns Hopkins University, USA)
- 11:40 Wed-M-O-1-3 1710 Self-Supervised End-to-End ASR for Low Resource L2 Swedish, Ragheb Al-Ghezi (Aalto University, Finland), Yaroslav Getman (Aalto University, Finland), Aku Rouhe (Aalto University, Finland), Raili Hildén (University of Helsinki, Finland) and Mikko Kurimo (Aalto University, Finland)
- 12:00 Wed-M-O-1-4 1860 SPGISpeech: 5,000 Hours of Transcribed Financial Audio for Fully Formatted End-to-End Speech Recognition, Patrick K. O’Neill (Kensho Technologies, USA), Vitaly Lavrukhin (NVIDIA, USA), Somshubra Majumdar (NVIDIA, USA), Vahid Noroozi (NVIDIA, USA), Yuekai Zhang (Johns Hopkins University, USA), Oleksii Kuchaiev (NVIDIA, USA), Jagadeesh Balam (NVIDIA, USA), Yuliya Dovzhenko (Kensho Technologies, USA), Keenan Freyberg (Kensho Technologies, USA), Michael D. Shulman (Kensho Technologies, USA), Boris Ginsburg (NVIDIA, USA), Shinji Watanabe (Johns Hopkins University, USA) and Georg Kucsko (Kensho Technologies, USA)
- 12:20 Wed-M-O-1-5 556 LeBenchmark: A Reproducible Framework for Assessing Self-Supervised Representation Learning from Speech, Solène Evain (LIG (UMR 5217), France), Ha Nguyen (LIG (UMR 5217), France), Hang Le (LIG (UMR 5217), France), Marcely Zanon Boito (LIG (UMR 5217), France), Salima Mdhaffar (LIA (EA 4128), France), Sina Alisamir (LIG (UMR 5217), France), Ziyi Tong (LIG (UMR 5217), France), Natalia Tomashenko (LIA (EA 4128), France), Marco Dinarelli (LIG (UMR 5217), France), Titouan Parcollet (LIA (EA 4128), France), Alexandre Allauzen (LAMSADE (UMR 7243), France), Yannick Estève (LIA (EA 4128), France), Benjamin Lecouteux (LIG (UMR 5217), France), François Portet (LIG (UMR 5217), France), Solange Rossato (LIG (UMR 5217), France), Fabien Ringeval (LIG (UMR 5217), France), Didier Schwab (LIG (UMR 5217), France) and Laurent Besacier (LIG (UMR 5217), France)
Wed-M-O-2 Wednesday, September 1, 11:00-13:00 In-person Oral: Phonetics I
- 11:00 Wed-M-O-2-1 130 Prosodic Accommodation in Face-to-Face and Telephone Dialogues, Pavel Šturm (Charles University, Czech Republic), Radek Skarnitzl (Charles University, Czech Republic) and Tomáš Nechanský (Charles University, Czech Republic)
- 11:20 Wed-M-O-2-2 1090 Dialect Features in Heterogeneous and Homogeneous Gheg Speaking Communities, Josiane Riverin-Coutlée (LMU München, Germany), Conceição Cunha (LMU München, Germany), Enkeleida Kapia (LMU München, Germany) and Jonathan Harrington (LMU München, Germany)
- 11:40 Wed-M-O-2-3 1328 An Exploration of the Acoustic Space of Rhotics and Laterals in Ruruuli, Margaret Zellers (CAU, Germany), Alena Witzlack-Makarevich (Hebrew University of Jerusalem, Israel), Lilja Saeboe (University of Oxford, UK) and Saudah Namyalo (Makerere University, Uganda)
- 12:00 Wed-M-O-2-4 2230 Domain-Initial Strengthening in Turkish: Acoustic Cues to Prosodic Hierarchy in Stop Consonants, Kubra Bodur (LPL (UMR 7309), France), Sweeney Branje (LPL (UMR 7309), France), Morgane Peirolo (LPL (UMR 7309), France), Ingrid Tiscareno (LPL (UMR 7309), France) and James S. German (LPL (UMR 7309), France)
Wed-M-O-3 Wednesday, September 1, 11:00-13:00 In-person Oral: Target speaker detection, localization and separation
- 11:00 Wed-M-O-3-1 986 Auxiliary Loss Function for Target Speech Extraction and Recognition with Weak Supervision Based on Speaker Characteristics, Katerina Zmolikova (Brno University of Technology, Czech Republic), Marc Delcroix (NTT, Japan), Desh Raj (Johns Hopkins University, USA), Shinji Watanabe (Johns Hopkins University, USA) and Jan Černocký (Brno University of Technology, Czech Republic)
- 11:20 Wed-M-O-3-2 1939 Universal Speaker Extraction in the Presence and Absence of Target Speakers for Speech of One and Two Talkers, Marvin Borsdorf (Universität Bremen, Germany), Chenglin Xu (NUS, Singapore), Haizhou Li (NUS, Singapore) and Tanja Schultz (Universität Bremen, Germany)
- 11:40 Wed-M-O-3-3 192 Using X-Vectors for Speech Activity Detection in Broadcast Streams, Lukas Mateju (Technical University of Liberec, Czech Republic), Frantisek Kynych (Technical University of Liberec, Czech Republic), Petr Cerva (Technical University of Liberec, Czech Republic), Jindrich Zdansky (Technical University of Liberec, Czech Republic) and Jiri Malek (Technical University of Liberec, Czech Republic)
- 12:00 Wed-M-O-3-4 988 Time Delay Estimation for Speaker Localization Using CNN-Based Parametrized GCC-PHAT Features, Daniele Salvati (Università di Udine, Italy), Carlo Drioli (Università di Udine, Italy) and Gian Luca Foresti (Università di Udine, Italy)
- 12:20 Wed-M-O-3-5 331 Real-Time Speaker Counting in a Cocktail Party Scenario Using Attention-Guided Convolutional Neural Network, Midia Yousefi (University of Texas at Dallas, USA) and John H.L. Hansen (University of Texas at Dallas, USA)
Wed-M-V-1 Wednesday, September 1, 11:00-13:00 Virtual: Language and Accent Recognition
- 11:00 Wed-M-V-1-1 82 End-to-End Language Diarization for Bilingual Code-Switching Speech, Hexin Liu (NTU, Singapore), Leibny Paola García Perera (Johns Hopkins University, USA), Xinyi Zhang (NTU, Singapore), Justin Dauwels (Technische Universiteit Delft, The Netherlands), Andy W.H. Khong (NTU, Singapore), Sanjeev Khudanpur (Johns Hopkins University, USA) and Suzy J. Styles (NTU, Singapore)
- 11:00 Wed-M-V-1-2 277 Modeling and Training Strategies for Language Recognition Systems, Raphaël Duroselle (Loria (UMR 7503), France), Md. Sahidullah (Loria (UMR 7503), France), Denis Jouvet (Loria (UMR 7503), France) and Irina Illina (Loria (UMR 7503), France)
- 11:00 Wed-M-V-1-3 776 A Weight Moving Average Based Alternate Decoupled Learning Algorithm for Long-Tailed Language Identification, Hui Wang (USTC, China), Lin Liu (iFLYTEK, China), Yan Song (USTC, China), Lei Fang (iFLYTEK, China), Ian McLoughlin (SIT, Singapore) and Li-Rong Dai (USTC, China)
- 11:00 Wed-M-V-1-4 1186 Improving Accent Identification and Accented Speech Recognition Under a Framework of Self-Supervised Learning, Keqi Deng (Tencent, China), Songjun Cao (Tencent, China) and Long Ma (Tencent, China)
- 11:00 Wed-M-V-1-5 1280 Exploring wav2vec 2.0 on Speaker Verification and Language Identification, Zhiyun Fan (CAS, China), Meng Li (CAS, China), Shiyu Zhou (CAS, China) and Bo Xu (CAS, China)
- 11:00 Wed-M-V-1-6 1310 Self-Supervised Phonotactic Representations for Language Identification, G. Ramesh (IIT Hyderabad, India), C. Shiva Kumar (IIT Hyderabad, India) and K. Sri Rama Murty (IIT Hyderabad, India)
- 11:00 Wed-M-V-1-7 1495 E2E-Based Multi-Task Learning Approach to Joint Speech and Accent Recognition, Jicheng Zhang (Xinjiang University, China), Yizhou Peng (Xinjiang University, China), Van Tung Pham (NTU, Singapore), Haihua Xu (NTU, Singapore), Hao Huang (Xinjiang University, China) and Eng Siong Chng (NTU, Singapore)
- 11:00 Wed-M-V-1-8 1672 Excitation Source Feature Based Dialect Identification in Ao — A Low Resource Language, Moakala Tzudir (IIT Guwahati, India), Shikha Baghel (IIT Guwahati, India), Priyankoo Sarmah (IIT Guwahati, India) and S.R. Mahadeva Prasanna (IIT Dharwad, India)
Wed-M-V-2 Wednesday, September 1, 11:00-13:00 Virtual: Low-resource speech recognition
- 11:00 Wed-M-V-2-1 2062 Low Resource ASR: The Surprising Effectiveness of High Resource Transliteration, Shreya Khare (IBM, India), Ashish Mittal (IBM, India), Anuj Diwan (IIT Bombay, India), Sunita Sarawagi (IIT Bombay, India), Preethi Jyothi (IIT Bombay, India) and Samarth Bharadwaj (IBM, India)
- 11:00 Wed-M-V-2-2 1664 Unsupervised Acoustic Unit Discovery by Leveraging a Language-Independent Subword Discriminative Feature Representation, Siyuan Feng (Technische Universiteit Delft, The Netherlands), Piotr Żelasko (Johns Hopkins University, USA), Laureano Moro-Velázquez (Johns Hopkins University, USA) and Odette Scharenborg (Technische Universiteit Delft, The Netherlands)
- 11:00 Wed-M-V-2-3 50 Towards Unsupervised Phone and Word Segmentation Using Self-Supervised Vector-Quantized Neural Networks, Herman Kamper (Stellenbosch University, South Africa) and Benjamin van Niekerk (Stellenbosch University, South Africa)
- 11:00 Wed-M-V-2-4 391 Speech SimCLR: Combining Contrastive and Reconstruction Objective for Self-Supervised Speech Representation Learning, Dongwei Jiang (YuanFuDao, China), Wubo Li (DiDi Chuxing, China), Miao Cao (DiDi Chuxing, China), Wei Zou (DiDi Chuxing, China) and Xiangang Li (DiDi Chuxing, China)
- 11:00 Wed-M-V-2-5 461 Multilingual Transfer of Acoustic Word Embeddings Improves When Training on Languages Related to the Target Zero-Resource Language, Christiaan Jacobs (Stellenbosch University, South Africa) and Herman Kamper (Stellenbosch University, South Africa)
- 11:00 Wed-M-V-2-6 1182 Analyzing Speaker Information in Self-Supervised Models to Improve Zero-Resource Speech Processing, Benjamin van Niekerk (Stellenbosch University, South Africa), Leanne Nortje (Stellenbosch University, South Africa), Matthew Baas (Stellenbosch University, South Africa) and Herman Kamper (Stellenbosch University, South Africa)
- 11:00 Wed-M-V-2-7 1340 Unsupervised Neural-Based Graph Clustering for Variable-Length Speech Representation Discovery of Zero-Resource Languages, Shun Takahashi (NAIST, Japan), Sakriani Sakti (NAIST, Japan) and Satoshi Nakamura (NAIST, Japan)
- 11:00 Wed-M-V-2-8 1503 Speech Representation Learning Combining Conformer CPC with Deep Cluster for the ZeroSpeech Challenge 2021, Takashi Maekaku (Yahoo, Japan), Xuankai Chang (Carnegie Mellon University, USA), Yuya Fujita (Yahoo, Japan), Li-Wei Chen (Carnegie Mellon University, USA), Shinji Watanabe (Carnegie Mellon University, USA) and Alexander Rudnicky (Carnegie Mellon University, USA)
- 11:00 Wed-M-V-2-9 1525 Identifying Indicators of Vulnerability from Short Speech Segments Using Acoustic and Textual Features, Xia Cui (University of Manchester, UK), Amila Gamage (VoiceIQ, UK), Terry Hanley (University of Manchester, UK) and Tingting Mu (University of Manchester, UK)
- 11:00 Wed-M-V-2-10 1755 The Zero Resource Speech Challenge 2021: Spoken Language Modelling, Ewan Dunbar (University of Toronto, Canada), Mathieu Bernard (LSCP (UMR 8554), France), Nicolas Hamilakis (LSCP (UMR 8554), France), Tu Anh Nguyen (LSCP (UMR 8554), France), Maureen de Seyssel (LSCP (UMR 8554), France), Patricia Rozé (LSCP (UMR 8554), France), Morgane Rivière (Facebook, France), Eugene Kharitonov (Facebook, France) and Emmanuel Dupoux (LSCP (UMR 8554), France)
- 11:00 Wed-M-V-2-11 2264 Zero-Shot Federated Learning with New Classes for Audio Classification, Gautham Krishna Gudur (Ericsson, India) and Satheesh Kumar Perepu (Ericsson, India)
- 11:00 Wed-M-V-2-12 1312 AVLnet: Learning Audio-Visual Language Representations from Instructional Videos, Andrew Rouditchenko (MIT, USA), Angie Boggust (MIT, USA), David Harwath (University of Texas at Austin, USA), Brian Chen (Columbia University, USA), Dhiraj Joshi (IBM, USA), Samuel Thomas (IBM, USA), Kartik Audhkhasi (Google, USA), Hilde Kuehne (IBM, USA), Rameswar Panda (IBM, USA), Rogerio Feris (IBM, USA), Brian Kingsbury (IBM, USA), Michael Picheny (NYU, USA), Antonio Torralba (MIT, USA) and James Glass (MIT, USA)
Wed-M-V-3 Wednesday, September 1, 11:00-13:00 Virtual: Speech Synthesis: Singing, Multimodal, Crosslingual Synthesis
- 11:00 Wed-M-V-3-1 239 N-Singer: A Non-Autoregressive Korean Singing Voice Synthesis System for Pronunciation Enhancement, Gyeong-Hoon Lee (NCSOFT, Korea), Tae-Woo Kim (NCSOFT, Korea), Hanbin Bae (NCSOFT, Korea), Min-Ji Lee (NCSOFT, Korea), Young-Ik Kim (NCSOFT, Korea) and Hoon-Young Cho (NCSOFT, Korea)
- 11:00 Wed-M-V-3-2 327 Cross-Lingual Low Resource Speaker Adaptation Using Phonological Features, Georgia Maniati (Samsung, Greece), Nikolaos Ellinas (Samsung, Greece), Konstantinos Markopoulos (Samsung, Greece), Georgios Vamvoukakis (Samsung, Greece), June Sig Sung (Samsung, Korea), Hyoungmin Park (Samsung, Korea), Aimilios Chalamandaris (Samsung, Greece) and Pirros Tsiakoulis (Samsung, Greece)
- 11:00 Wed-M-V-3-3 474 Improve Cross-Lingual Text-To-Speech Synthesis on Monolingual Corpora with Pitch Contour Information, Haoyue Zhan (NetEase, China), Haitong Zhang (NetEase, China), Wenjie Ou (NetEase, China) and Yue Lin (NetEase, China)
- 11:00 Wed-M-V-3-4 552 Cross-Lingual Voice Conversion with Disentangled Universal Linguistic Representations, Zhenchuan Yang (SCUT, China), Weibin Zhang (VoiceAI Technologies, China), Yufei Liu (SCUT, China) and Xiaofen Xing (SCUT, China)
- 11:00 Wed-M-V-3-5 771 EfficientSing: A Chinese Singing Voice Synthesis System Using Duration-Free Acoustic Model and HiFi-GAN Vocoder, Zhengchen Liu (Ping An Technology, China), Chenfeng Miao (Ping An Technology, China), Qingying Zhu (Ping An Technology, China), Minchuan Chen (Ping An Technology, China), Jun Ma (Ping An Technology, China), Shaojun Wang (Ping An Technology, China) and Jing Xiao (Ping An Technology, China)
- 11:00 Wed-M-V-3-6 897 Cross-Lingual Speaker Adaptation Using Domain Adaptation and Speaker Consistency Loss for Text-To-Speech Synthesis, Detai Xin (University of Tokyo, Japan), Yuki Saito (University of Tokyo, Japan), Shinnosuke Takamichi (University of Tokyo, Japan), Tomoki Koriyama (University of Tokyo, Japan) and Hiroshi Saruwatari (University of Tokyo, Japan)
- 11:00 Wed-M-V-3-7 1265 Incorporating Cross-Speaker Style Transfer for Multi-Language Text-to-Speech, Zengqiang Shang (CAS, China), Zhihua Huang (UCAS, China), Haozhe Zhang (CAS, China), Pengyuan Zhang (CAS, China) and Yonghong Yan (CAS, China)
- 11:00 Wed-M-V-3-8 1585 Investigating Contributions of Speech and Facial Landmarks for Talking Head Generation, Ege Kesim (Koç University, Turkey) and Engin Erzin (Koç University, Turkey)
- 11:00 Wed-M-V-3-9 1996 Speech2Video: Cross-Modal Distillation for Speech to Video Generation, Shijing Si (Ping An Technology, China), Jianzong Wang (Ping An Technology, China), Xiaoyang Qu (Ping An Technology, China), Ning Cheng (Ping An Technology, China), Wenqi Wei (Ping An Technology, China), Xinghua Zhu (Ping An Technology, China) and Jing Xiao (Ping An Technology, China)
Wed-M-V-4 Wednesday, September 1, 11:00-13:00 Virtual: Speech coding and privacy
- 11:00 Wed-M-V-4-1 36 NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling, Junhyeok Lee (MINDs Lab, Korea) and Seungu Han (MINDs Lab, Korea)
- 11:00 Wed-M-V-4-2 670 QISTA-Net-Audio: Audio Super-Resolution via Non-Convex ℓq-Norm Minimization, Gang-Xuan Lin (Academia Sinica, Taiwan), Shih-Wei Hu (Academia Sinica, Taiwan), Yen-Ju Lu (Academia Sinica, Taiwan), Yu Tsao (Academia Sinica, Taiwan) and Chun-Shien Lu (Academia Sinica, Taiwan)
- 11:00 Wed-M-V-4-3 812 X-net: A Joint Scale Down and Scale Up Method for Voice Call, Liang Wen (Samsung, China), Lizhong Wang (Samsung, China), Xue Wen (Samsung, China), Yuxing Zheng (Samsung, China), Youngo Park (Samsung, Korea) and Kwang Pyo Choi (Samsung, Korea)
- 11:00 Wed-M-V-4-4 892 WSRGlow: A Glow-Based Waveform Generative Model for Audio Super-Resolution, Kexun Zhang (Zhejiang University, China), Yi Ren (Zhejiang University, China), Changliang Xu (Xinhua News Agency, China) and Zhou Zhao (Zhejiang University, China)
- 11:00 Wed-M-V-4-5 930 Half-Truth: A Partially Fake Audio Detection Dataset, Jiangyan Yi (CAS, China), Ye Bai (CAS, China), Jianhua Tao (CAS, China), Haoxin Ma (CAS, China), Zhengkun Tian (CAS, China), Chenglong Wang (CAS, China), Tao Wang (CAS, China) and Ruibo Fu (CAS, China)
- 11:00 Wed-M-V-4-6 1180 Data Quality as Predictor of Voice Anti-Spoofing Generalization, Bhusan Chettri (University of Eastern Finland, Finland), Rosa González Hautamäki (University of Eastern Finland, Finland), Md. Sahidullah (Loria (UMR 7503), France) and Tomi Kinnunen (University of Eastern Finland, Finland)
- 11:00 Wed-M-V-4-7 1204 Coded Speech Enhancement Using Neural Network-Based Vector-Quantized Residual Features, Youngju Cheon (GIST, Korea), Soojoong Hwang (GIST, Korea), Sangwook Han (GIST, Korea), Inseon Jang (ETRI, Korea) and Jong Won Shin (GIST, Korea)
- 11:00 Wed-M-V-4-8 1214 Multi-Channel Opus Compression for Far-Field Automatic Speech Recognition with a Fixed Bitrate Budget, Lukas Drude (Amazon, Germany), Jahn Heymann (Amazon, Germany), Andreas Schwarz (Amazon, Germany) and Jean-Marc Valin (Amazon, USA)
- 11:00 Wed-M-V-4-9 1354 Effects of Prosodic Variations on Accidental Triggers of a Commercial Voice Assistant, Ingo Siegert (OvG Universität Magdeburg, Germany)
- 11:00 Wed-M-V-4-10 1555 Improving the Expressiveness of Neural Vocoding with Non-Affine Normalizing Flows, Adam Gabryś (Amazon, Poland), Yunlong Jiao (Amazon, UK), Viacheslav Klimkov (Amazon, Germany), Daniel Korzekwa (Amazon, Poland) and Roberto Barra-Chicote (Amazon, UK)
- 11:00 Wed-M-V-4-11 1573 Voice Privacy Through x-Vector and CycleGAN-Based Anonymization, Gauri P. Prajapati (DA-IICT, India), Dipesh K. Singh (DA-IICT, India), Preet P. Amin (DA-IICT, India) and Hemant A. Patil (DA-IICT, India)
- 11:00 Wed-M-V-4-12 1941 A Two-Stage Approach to Speech Bandwidth Extension, Ju Lin (Clemson University, USA), Yun Wang (Facebook, USA), Kaustubh Kalgaonkar (Facebook, USA), Gil Keren (Facebook, USA), Didi Zhang (Facebook, USA) and Christian Fuegen (Facebook, USA)
- 11:00 Wed-M-V-4-13 2151 Development of a Psychoacoustic Loss Function for the Deep Neural Network (DNN)-Based Speech Coder, Joon Byun (Yonsei University, Korea), Seungmin Shin (Yonsei University, Korea), Youngcheol Park (Yonsei University, Korea), Jongmo Sung (ETRI, Korea) and Seungkwon Beack (ETRI, Korea)
- 11:00 Wed-M-V-4-14 2163 Protecting Gender and Identity with Disentangled Speech Representations, Dimitrios Stoidis (Queen Mary University of London, UK) and Andrea Cavallaro (Queen Mary University of London, UK)
Wed-M-V-5 Wednesday, September 1, 11:00-13:00 Virtual: Speech perception II
- 11:00 Wed-M-V-5-1 39 Perception of Standard Arabic Synthetic Speech Rate, Yahya Aldholmi (King Saud University, Saudi Arabia), Rawan Aldhafyan (King Saud University, Saudi Arabia) and Asma Alqahtani (King Saud University, Saudi Arabia)
- 11:00 Wed-M-V-5-2 89 The Influence of Parallel Processing on Illusory Vowels, Takeshi Kishiyama (University of Tokyo, Japan)
- 11:00 Wed-M-V-5-3 306 Exploring the Potential of Lexical Paraphrases for Mitigating Noise-Induced Comprehension Errors, Anupama Chingacham (Universität des Saarlandes, Germany), Vera Demberg (Universität des Saarlandes, Germany) and Dietrich Klakow (Universität des Saarlandes, Germany)
- 11:00 Wed-M-V-5-4 324 SPEECHADJUSTER: A Tool for Investigating Listener Preferences and Speech Intelligibility, Olympia Simantiraki (Universidad del País Vasco, Spain) and Martin Cooke (Ikerbasque, Spain)
- 11:00 Wed-M-V-5-5 464 VocalTurk: Exploring Feasibility of Crowdsourced Speaker Identification, Susumu Saito (Waseda University, Japan), Yuta Ide (Waseda University, Japan), Teppei Nakano (Waseda University, Japan) and Tetsuji Ogawa (Waseda University, Japan)
- 11:00 Wed-M-V-5-6 682 Effects of Aging and Age-Related Hearing Loss on Talker Discrimination, Min Xu (CAS, China), Jing Shao (HKBU, China) and Lan Wang (CAS, China)
- 11:00 Wed-M-V-5-7 721 Relationships Between Perceptual Distinctiveness, Articulatory Complexity and Functional Load in Speech Communication, Yuqing Zhang (BLCU, China), Zhu Li (BLCU, China), Bin Wu (NAIST, Japan), Yanlu Xie (BLCU, China), Binghuai Lin (Tencent, China) and Jinsong Zhang (BLCU, China)
- 11:00 Wed-M-V-5-8 1225 Human Spoofing Detection Performance on Degraded Speech, Camryn Terblanche (University of Cape Town, South Africa), Philip Harrison (University of York, UK) and Amelia J. Gully (University of York, UK)
- 11:00 Wed-M-V-5-9 1524 Reliable Estimates of Interpretable Cue Effects with Active Learning in Psycholinguistic Research, Marieke Einfeldt (Universität Konstanz, Germany), Rita Sevastjanova (Universität Konstanz, Germany), Katharina Zahner-Ritter (Universität Trier, Germany), Ekaterina Kazak (University of Manchester, UK) and Bettina Braun (Universität Konstanz, Germany)
- 11:00 Wed-M-V-5-10 1718 Towards the Explainability of Multimodal Speech Emotion Recognition, Puneet Kumar (IIT Roorkee, India), Vishesh Kaushik (IIT Kanpur, India) and Balasubramanian Raman (IIT Roorkee, India)
- 11:00 Wed-M-V-5-11 1741 Primacy of Mouth over Eyes: Eye Movement Evidence from Audiovisual Mandarin Lexical Tones and Vowels, Biao Zeng (University of South Wales, UK), Rui Wang (Guangdong Pharmaceutical University, China), Guoxing Yu (University of Bristol, UK) and Christian Dobel (FSU Jena, Germany)
- 11:00 Wed-M-V-5-12 2091 Investigating the Impact of Spectral and Temporal Degradation on End-to-End Automatic Speech Recognition Performance, Takanori Ashihara (NTT, Japan), Takafumi Moriya (NTT, Japan) and Makio Kashino (NTT, Japan)
Wed-M-V-6 Wednesday, September 1, 11:00-13:00 Virtual: Streaming for ASR/RNN Transducers
- 11:00 Wed-M-V-6-1 1114 Super-Human Performance in Online Low-Latency Recognition of Conversational Speech, Thai-Son Nguyen (KIT, Germany), Sebastian Stüker (KIT, Germany) and Alex Waibel (KIT, Germany)
- 11:00 Wed-M-V-6-2 1298 Multiple Softmax Architecture for Streaming Multilingual End-to-End ASR Systems, Vikas Joshi (Microsoft, India), Amit Das (Microsoft, USA), Eric Sun (Microsoft, USA), Rupesh R. Mehta (Microsoft, India), Jinyu Li (Microsoft, USA) and Yifan Gong (Microsoft, USA)
- 11:00 Wed-M-V-6-3 1566 Contextualized Streaming End-to-End Speech Recognition with Trie-Based Deep Biasing and Shallow Fusion, Duc Le (Facebook, USA), Mahaveer Jain (Facebook, USA), Gil Keren (Facebook, USA), Suyoun Kim (Facebook, USA), Yangyang Shi (Facebook, USA), Jay Mahadeokar (Facebook, USA), Julian Chan (Facebook, USA), Yuan Shangguan (Facebook, USA), Christian Fuegen (Facebook, USA), Ozlem Kalinli (Facebook, USA), Yatharth Saraf (Facebook, USA) and Michael L. Seltzer (Facebook, USA)
- 11:00 Wed-M-V-6-4 206 An Efficient Streaming Non-Recurrent On-Device End-to-End Model with Improvements to Rare-Word Modeling, Tara N. Sainath (Google, USA), Yanzhang He (Google, USA), Arun Narayanan (Google, USA), Rami Botros (Google, USA), Ruoming Pang (Google, USA), David Rybach (Google, USA), Cyril Allauzen (Google, USA), Ehsan Variani (Google, USA), James Qin (Google, USA), Quoc-Nam Le-The (Google, USA), Shuo-Yiin Chang (Google, USA), Bo Li (Google, USA), Anmol Gulati (Google, USA), Jiahui Yu (Google, USA), Chung-Cheng Chiu (Google, USA), Diamantino Caseiro (Google, USA), Wei Li (Google, USA), Qiao Liang (Google, USA) and Pat Rondon (Google, USA)
- 11:00 Wed-M-V-6-5 207 Streaming Multi-Talker Speech Recognition with Joint Speaker Identification, Liang Lu (Microsoft, USA), Naoyuki Kanda (Microsoft, USA), Jinyu Li (Microsoft, USA) and Yifan Gong (Microsoft, USA)
- 11:00 Wed-M-V-6-6 437 Streaming End-to-End Speech Recognition for Hybrid RNN-T/Attention Architecture, Takafumi Moriya (NTT, Japan), Tomohiro Tanaka (NTT, Japan), Takanori Ashihara (NTT, Japan), Tsubasa Ochiai (NTT, Japan), Hiroshi Sato (NTT, Japan), Atsushi Ando (NTT, Japan), Ryo Masumura (NTT, Japan), Marc Delcroix (NTT, Japan) and Taichi Asami (NTT, Japan)
- 11:00 Wed-M-V-6-7 542 Improving RNN-T ASR Accuracy Using Context Audio, Andreas Schwarz (Amazon, Germany), Ilya Sklyar (Amazon, Germany) and Simon Wiesler (Amazon, Germany)
- 11:00 Wed-M-V-6-8 586 HMM-Free Encoder Pre-Training for Streaming RNN Transducer, Lu Huang (ByteDance, China), Jingyu Sun (ByteDance, China), Yufeng Tang (ByteDance, China), Junfeng Hou (ByteDance, China), Jinkun Chen (ByteDance, China), Jun Zhang (ByteDance, China) and Zejun Ma (ByteDance, China)
- 11:00 Wed-M-V-6-9 587 Reducing Exposure Bias in Training Recurrent Neural Network Transducers, Xiaodong Cui (IBM, USA), Brian Kingsbury (IBM, USA), George Saon (IBM, USA), David Haws (IBM, USA) and Zoltán Tüske (IBM, USA)
- 11:00 Wed-M-V-6-10 637 Bridging the Gap Between Streaming and Non-Streaming ASR Systems by Distilling Ensembles of CTC and RNN-T Models, Thibault Doutre (Google, USA), Wei Han (Google, USA), Chung-Cheng Chiu (Google, USA), Ruoming Pang (Google, USA), Olivier Siohan (Google, USA) and Liangliang Cao (Google, USA)
- 11:00 Wed-M-V-6-11 720 Mixture Model Attention: Flexible Streaming and Non-Streaming Automatic Speech Recognition, Kartik Audhkhasi (Google, USA), Tongzhou Chen (Google, USA), Bhuvana Ramabhadran (Google, USA) and Pedro J. Moreno (Google, USA)
- 11:00 Wed-M-V-6-12 1110 StableEmit: Selection Probability Discount for Reducing Emission Latency of Streaming Monotonic Attention ASR, Hirofumi Inaguma (Kyoto University, Japan) and Tatsuya Kawahara (Kyoto University, Japan)
- 11:00 Wed-M-V-6-13 1693 Dual Causal/Non-Causal Self-Attention for Streaming End-to-End Speech Recognition, Niko Moritz (MERL, USA), Takaaki Hori (MERL, USA) and Jonathan Le Roux (MERL, USA)
- 11:00 Wed-M-V-6-14 1953 Multi-Mode Transformer Transducer with Stochastic Future Context, Kwangyoun Kim (ASAPP, USA), Felix Wu (ASAPP, USA), Prashant Sridhar (ASAPP, USA), Kyu J. Han (ASAPP, USA) and Shinji Watanabe (Carnegie Mellon University, USA)
Wed-M-SS-1 Wednesday, September 1, 11:00-13:00 Special-Virtual: ConferencingSpeech 2021 challenge: Far-field Multi-Channel Speech Enhancement for Video Conferencing
- 11:00 Introduction of challenge
- 11:20 Wed-M-SS-1-1 1457 A Causal U-Net Based Neural Beamforming Network for Real-Time Multi-Channel Speech Enhancement, Xinlei Ren (Kuaishou Technology, China), Xu Zhang (Kuaishou Technology, China), Lianwu Chen (Kuaishou Technology, China), Xiguang Zheng (Kuaishou Technology, China), Chen Zhang (Kuaishou Technology, China), Liang Guo (Kuaishou Technology, China) and Bing Yu (Kuaishou Technology, China)
- 11:40 Short presentations 1
- 12:00 Short presentations 2
- 12:20 Panel discussion
- 12:30 Wed-M-SS-1-2 135 A Partitioned-Block Frequency-Domain Adaptive Kalman Filter for Stereophonic Acoustic Echo Cancellation, Rui Zhu (Tencent, China), Feiran Yang (CAS, China), Yuepeng Li (Tencent, China) and Shidong Shang (Tencent, China)
- 12:30 Wed-M-SS-1-3 146 Real-Time Independent Vector Analysis Using Semi-Supervised Nonnegative Matrix Factorization as a Source Model, Taihui Wang (CAS, China), Feiran Yang (CAS, China), Rui Zhu (Tencent, China) and Jun Yang (CAS, China)
- 12:30 Wed-M-SS-1-4 298 Improving Channel Decorrelation for Multi-Channel Target Speech Extraction, Jiangyu Han (Shanghai Normal University, China), Wei Rao (Tencent, China), Yannan Wang (Tencent, China) and Yanhua Long (Shanghai Normal University, China)
- 12:30 Wed-M-SS-1-5 899 Inplace Gated Convolutional Recurrent Neural Network for Dual-Channel Speech Enhancement, Jinjiang Liu (Inner Mongolia University, China) and Xueliang Zhang (Inner Mongolia University, China)
- 12:30 Wed-M-SS-1-6 1111 SRIB-LEAP Submission to Far-Field Multi-Channel Speech Enhancement Challenge for Video Conferencing, R.G. Prithvi Raj (Samsung, India), Rohit Kumar (Indian Institute of Science, India), M.K. Jayesh (Samsung, India), Anurenjan Purushothaman (Indian Institute of Science, India), Sriram Ganapathy (Indian Institute of Science, India) and M.A. Basha Shaik (Samsung, India)
- 12:30 Wed-M-SS-1-7 2266 Real-Time Multi-Channel Speech Enhancement Based on Neural Network Masking with Attention Model, Cheng Xue (Alibaba, China), Weilong Huang (Alibaba, China), Weiguang Chen (Alibaba, China) and Jinwei Feng (Alibaba, USA)
Wed-A-O-1 Wednesday, September 1, 16:00-18:00 In-person Oral: Language Modeling and Text-based Innovations for ASR
- 16:00 Wed-A-O-1-1 313 BERT-Based Semantic Model for Rescoring N-Best Speech Recognition List, Dominique Fohr (Loria (UMR 7503), France) and Irina Illina (Loria (UMR 7503), France)
- 16:20 Wed-A-O-1-5 1191 Fast Text-Only Domain Adaptation of RNN-Transducer Prediction Network, Janne Pylkkönen (Speechly, Finland), Antti Ukkonen (Speechly, Finland), Juho Kilpikoski (Speechly, Finland), Samu Tamminen (Speechly, Finland) and Hannes Heikinheimo (Speechly, Finland)
- 16:40 Wed-A-O-1-3 627 Text Augmentation for Language Models in High Error Recognition Scenario, Karel Beneš (Brno University of Technology, Czech Republic) and Lukáš Burget (Brno University of Technology, Czech Republic)
- 17:00 Wed-A-O-1-4 1067 On Sampling-Based Training Criteria for Neural Language Modeling, Yingbo Gao (RWTH Aachen University, Germany), David Thulke (RWTH Aachen University, Germany), Alexander Gerstenberger (RWTH Aachen University, Germany), Khoa Viet Tran (RWTH Aachen University, Germany), Ralf Schlüter (RWTH Aachen University, Germany) and Hermann Ney (RWTH Aachen University, Germany)
Wed-A-O-2 Wednesday, September 1, 16:00-18:00 In-person Oral: Speaker, Language, and Privacy
- 16:00 Wed-A-O-2-6 1712 Adversarial Disentanglement of Speaker Representation for Attribute-Driven Privacy Preservation, Paul-Gauthier Noé (LIA (EA 4128), France), Mohammad Mohammadamini (LIA (EA 4128), France), Driss Matrouf (LIA (EA 4128), France), Titouan Parcollet (LIA (EA 4128), France), Andreas Nautsch (EURECOM, France) and Jean-François Bonastre (LIA (EA 4128), France)
- 16:20 Wed-A-O-2-2 1611 Using Games to Augment Corpora for Language Recognition and Confusability, Christopher Cieri (University of Pennsylvania, USA), James Fiumara (University of Pennsylvania, USA) and Jonathan Wright (University of Pennsylvania, USA)
- 16:40 Wed-A-O-2-3 1857 Fair Voice Biometrics: Impact of Demographic Imbalance on Group Fairness in Speaker Recognition, Gianni Fenu (Università di Cagliari, Italy), Mirko Marras (EPFL, Switzerland), Giacomo Medda (Università di Cagliari, Italy) and Giacomo Meloni (Università di Cagliari, Italy)
- 17:00 Wed-A-O-2-4 2119 Knowledge Distillation from Multi-Modality to Single-Modality for Person Verification, Leying Zhang (SJTU, China), Zhengyang Chen (SJTU, China) and Yanmin Qian (SJTU, China)
Wed-A-O-3 Wednesday, September 1, 16:00-18:00 In-person Oral: Assessment of pathological speech and language I
- 16:00 Wed-A-O-3-1 1694 Automatically Detecting Errors and Disfluencies in Read Speech to Predict Cognitive Impairment in People with Parkinson’s Disease, Amrit Romana (University of Michigan, USA), John Bandon (University of Michigan, USA), Matthew Perez (University of Michigan, USA), Stephanie Gutierrez (Northwestern University, USA), Richard Richter (Northwestern University, USA), Angela Roberts (Northwestern University, USA) and Emily Mower Provost (University of Michigan, USA)
- 16:20 Wed-A-O-3-2 1736 Automatic Extraction of Speech Rhythm Descriptors for Speech Intelligibility Assessment in the Context of Head and Neck Cancers, Robin Vaysse (IRIT (UMR 5505), France), Jérôme Farinas (IRIT (UMR 5505), France), Corine Astésano (URI Octogone-Lordat (EA 4156), France) and Régine André-Obrecht (IRIT (UMR 5505), France)
- 16:40 Wed-A-O-3-3 2180 Speech Disorder Classification Using Extended Factorized Hierarchical Variational Auto-Encoders, Jinzi Qi (KU Leuven, Belgium) and Hugo Van hamme (KU Leuven, Belgium)
- 17:00 Wed-A-O-3-4 1403 The Impact of Forced-Alignment Errors on Automatic Pronunciation Evaluation, Vikram C. Mathad (Arizona State University, USA), Tristan J. Mahr (UW–Madison, USA), Nancy Scherer (Arizona State University, USA), Kathy Chapman (University of Utah, USA), Katherine C. Hustad (UW–Madison, USA), Julie Liss (Arizona State University, USA) and Visar Berisha (Arizona State University, USA)
- 17:20 Wed-A-O-3-5 1288 Late Fusion of the Available Lexicon and Raw Waveform-Based Acoustic Modeling for Depression and Dementia Recognition, Esaú Villatoro-Tello (UAM, Mexico), S. Pavankumar Dubagunta (Idiap Research Institute, Switzerland), Julian Fritsch (Idiap Research Institute, Switzerland), Gabriela Ramírez-de-la-Rosa (UAM, Mexico), Petr Motlicek (Idiap Research Institute, Switzerland) and Mathew Magimai-Doss (Idiap Research Institute, Switzerland)
- 17:40 Wed-A-O-3-6 1466 Neural Speaker Embeddings for Ultrasound-Based Silent Speech Interfaces, Amin Honarmandi Shandiz (University of Szeged, Hungary), László Tóth (University of Szeged, Hungary), Gábor Gosztolya (MTA-SZTE RGAI, Hungary), Alexandra Markó (ELTE, Hungary) and Tamás Gábor Csapó (MTA-ELTE LingArt, Hungary)
Wed-A-V-1 Wednesday, September 1, 16:00-18:00 Virtual: Communication and interaction, multimodality
- 16:00 Wed-A-V-1-1 2135 Cross-Modal Learning for Audio-Visual Video Parsing, Jatin Lamba (IIT Bombay, India), Abhishek (IIT Bombay, India), Jayaprakash Akula (IIT Bombay, India), Rishabh Dabral (IIT Bombay, India), Preethi Jyothi (IIT Bombay, India) and Ganesh Ramakrishnan (IIT Bombay, India)
- 16:00 Wed-A-V-1-2 2249 A Psychology-Driven Computational Analysis of Political Interviews, Darren Cook (University of Liverpool, UK), Miri Zilka (University of Sussex, UK), Simon Maskell (University of Liverpool, UK) and Laurence Alison (University of Liverpool, UK)
- 16:00 Wed-A-V-1-3 411 Speech Emotion Recognition Based on Attention Weight Correction Using Word-Level Confidence Measure, Jennifer Santoso (University of Tsukuba, Japan), Takeshi Yamada (University of Tsukuba, Japan), Shoji Makino (University of Tsukuba, Japan), Kenkichi Ishizuka (Revcomm, Japan) and Takekatsu Hiramura (Revcomm, Japan)
- 16:00 Wed-A-V-1-4 701 Effects of Voice Type and Task on L2 Learners’ Awareness of Pronunciation Errors, Alif Silpachai (Iowa State University, USA), Ivana Rehman (Iowa State University, USA), Taylor Anne Barriuso (Iowa State University, USA), John Levis (Iowa State University, USA), Evgeny Chukharev-Hudilainen (Iowa State University, USA), Guanlong Zhao (Texas A&M University, USA) and Ricardo Gutierrez-Osuna (Texas A&M University, USA)
- 16:00 Wed-A-V-1-5 1441 Lexical Entrainment and Intra-Speaker Variability in Cooperative Dialogues, Alla Menshikova (Saint Petersburg State University, Russia), Daniil Kocharov (Saint Petersburg State University, Russia) and Tatiana Kachkovskaia (Saint Petersburg State University, Russia)
- 16:00 Wed-A-V-1-6 1526 Detecting Alzheimer’s Disease Using Interactional and Acoustic Features from Spontaneous Speech, Shamila Nasreen (Queen Mary University of London, UK), Julian Hough (Queen Mary University of London, UK) and Matthew Purver (Queen Mary University of London, UK)
- 16:00 Wed-A-V-1-7 1796 Investigating the Interplay Between Affective, Phonatory and Motoric Subsystems in Autism Spectrum Disorder Using a Multimodal Dialogue Agent, Hardik Kothare (Modality.AI, USA), Vikram Ramanarayanan (Modality.AI, USA), Oliver Roesler (Modality.AI, USA), Michael Neumann (Modality.AI, USA), Jackson Liscombe (Modality.AI, USA), William Burke (Modality.AI, USA), Andrew Cornish (Modality.AI, USA), Doug Habberstad (Modality.AI, USA), Alaa Sakallah (University of California at San Francisco, USA), Sara Markuson (University of California at San Francisco, USA), Seemran Kansara (University of California at San Francisco, USA), Afik Faerman (University of California at San Francisco, USA), Yasmine Bensidi-Slimane (University of California at San Francisco, USA), Laura Fry (University of California at San Francisco, USA), Saige Portera (University of California at San Francisco, USA), David Suendermann-Oeft (Modality.AI, USA), David Pautler (Modality.AI, USA) and Carly Demopoulos (University of California at San Francisco, USA)
- 16:00 Wed-A-V-1-8 2134 Analysis of Eye Gaze Reasons and Gaze Aversions During Three-Party Conversations, Carlos Toshinori Ishi (RIKEN, Japan) and Taiken Shintani (RIKEN, Japan)
Wed-A-V-2 Wednesday, September 1, 16:00-18:00 Virtual: Language and Lexical Modeling for ASR
- 16:00 Wed-A-V-2-1 1929 Semantic Distance: A New Metric for ASR Performance Analysis Towards Spoken Language Understanding, Suyoun Kim (Facebook, USA), Abhinav Arora (Facebook, USA), Duc Le (Facebook, USA), Ching-Feng Yeh (Facebook, USA), Christian Fuegen (Facebook, USA), Ozlem Kalinli (Facebook, USA) and Michael L. Seltzer (Facebook, USA)
- 16:00 Wed-A-V-2-2 379 A Light-Weight Contextual Spelling Correction Model for Customizing Transducer-Based Speech Recognition Systems, Xiaoqiang Wang (Microsoft, China), Yanqing Liu (Microsoft, China), Sheng Zhao (Microsoft, China) and Jinyu Li (Microsoft, USA)
- 16:00 Wed-A-V-2-3 1708 Incorporating External POS Tagger for Punctuation Restoration, Ning Shi (Alibaba, China), Wei Wang (Alibaba, China), Boxin Wang (University of Illinois at Urbana-Champaign, USA), Jinfeng Li (Alibaba, China), Xiangyu Liu (Alibaba, China) and Zhouhan Lin (SJTU, China)
- 16:00 Wed-A-V-2-4 1787 Phonetically Induced Subwords for End-to-End Speech Recognition, Vasileios Papadourakis (Amazon, USA), Markus Müller (Amazon, USA), Jing Liu (Amazon, USA), Athanasios Mouchtaris (Amazon, USA) and Maurizio Omologo (Amazon, USA)
- 16:00 Wed-A-V-2-5 1908 Revisiting Parity of Human vs. Machine Conversational Speech Transcription, Courtney Mansfield (University of Washington, USA), Sara Ng (University of Washington, USA), Gina-Anne Levow (University of Washington, USA), Richard A. Wright (University of Washington, USA) and Mari Ostendorf (University of Washington, USA)
- 16:00 Wed-A-V-2-6 340 Lookup-Table Recurrent Language Models for Long Tail Speech Recognition, W. Ronny Huang (Google, USA), Tara N. Sainath (Google, USA), Cal Peyser (Google, USA), Shankar Kumar (Google, USA), David Rybach (Google, USA) and Trevor Strohman (Google, USA)
- 16:00 Wed-A-V-2-7 443 Contextual Density Ratio for Language Model Biasing of Sequence to Sequence ASR Systems, Jesús Andrés-Ferrer (Nuance Communications, Spain), Dario Albesano (Nuance Communications, Italy), Puming Zhan (Nuance Communications, USA) and Paul Vozila (Nuance Communications, USA)
- 16:00 Wed-A-V-2-8 661 Token-Level Supervised Contrastive Learning for Punctuation Restoration, Qiushi Huang (SUSTech, China), Tom Ko (SUSTech, China), H. Lilian Tang (University of Surrey, UK), Xubo Liu (University of Surrey, UK) and Bo Wu (MIT-IBM Watson AI Lab, USA)
- 16:00 Wed-A-V-2-9 739 BART Based Semantic Correction for Mandarin Automatic Speech Recognition System, Yun Zhao (Cloudwalk Technology, China), Xuerui Yang (Cloudwalk Technology, China), Jinchao Wang (Cloudwalk Technology, China), Yongyu Gao (Cloudwalk Technology, China), Chao Yan (Cloudwalk Technology, China) and Yuanfu Zhou (Cloudwalk Technology, China)
- 16:00 Wed-A-V-2-10 1080 Class-Based Neural Network Language Model for Second-Pass Rescoring in ASR, Lingfeng Dai (SJTU, China), Qi Liu (SJTU, China) and Kai Yu (SJTU, China)
- 16:00 Wed-A-V-2-11 1656 Improving Customization of Neural Transducers by Mitigating Acoustic Mismatch of Synthesized Audio, Gakuto Kurata (IBM, Japan), George Saon (IBM, USA), Brian Kingsbury (IBM, USA), David Haws (IBM, USA) and Zoltán Tüske (IBM, USA)
- 16:00 Wed-A-V-2-12 1767 A Discriminative Entity-Aware Language Model for Virtual Assistants, Mandana Saebi (University of Notre Dame, USA), Ernest Pusateri (Apple, USA), Aaksha Meghawat (Apple, USA) and Christophe Van Gysel (Apple, USA)
- 16:00 Wed-A-V-2-13 591 Correcting Automated and Manual Speech Transcription Errors Using Warped Language Models, Mahdi Namazifar (Amazon, USA), John Malik (Amazon, USA), Li Erran Li (Amazon, USA), Gokhan Tur (Amazon, USA) and Dilek Hakkani Tür (Amazon, USA)
Wed-A-V-3 Wednesday, September 1, 16:00-18:00 Virtual: Novel neural network architectures for ASR
- 16:00 Wed-A-V-3-1 1272 Dynamic Encoder Transducer: A Flexible Solution for Trading Off Accuracy for Latency, Yangyang Shi (Facebook, USA), Varun Nagaraja (Facebook, USA), Chunyang Wu (Facebook, USA), Jay Mahadeokar (Facebook, USA), Duc Le (Facebook, USA), Rohit Prabhavalkar (Facebook, USA), Alex Xiao (Facebook, USA), Ching-Feng Yeh (Facebook, USA), Julian Chan (Facebook, USA), Christian Fuegen (Facebook, USA), Ozlem Kalinli (Facebook, USA) and Michael L. Seltzer (Facebook, USA)
- 16:00 Wed-A-V-3-2 1477 Domain-Aware Self-Attention for Multi-Domain Neural Machine Translation, Shiqi Zhang (Alibaba, China), Yan Liu (Tianjin University, China), Deyi Xiong (Tianjin University, China), Pei Zhang (Alibaba, China) and Boxing Chen (Alibaba, China)
- 16:00 Wed-A-V-3-3 1510 Librispeech Transducer Model with Internal Language Model Prior Correction, Albert Zeyer (RWTH Aachen University, Germany), André Merboldt (RWTH Aachen University, Germany), Wilfried Michel (RWTH Aachen University, Germany), Ralf Schlüter (RWTH Aachen University, Germany) and Hermann Ney (RWTH Aachen University, Germany)
- 16:00 Wed-A-V-3-4 165 A Deliberation-Based Joint Acoustic and Text Decoder, Sepand Mavandadi (Google, USA), Tara N. Sainath (Google, USA), Ke Hu (Google, USA) and Zelin Wu (Google, USA)
- 16:00 Wed-A-V-3-5 211 On the Limit of English Conversational Speech Recognition, Zoltán Tüske (IBM, USA), George Saon (IBM, USA) and Brian Kingsbury (IBM, USA)
- 16:00 Wed-A-V-3-6 387 Deformable TDNN with Adaptive Receptive Fields for Speech Recognition, Keyu An (Tsinghua University, China), Yi Zhang (Tsinghua University, China) and Zhijian Ou (Tsinghua University, China)
- 16:00 Wed-A-V-3-7 427 Transformer-Based End-to-End Speech Recognition with Residual Gaussian-Based Self-Attention, Chengdong Liang (Northwestern Polytechnical University, China), Menglong Xu (Northwestern Polytechnical University, China) and Xiao-Lei Zhang (Northwestern Polytechnical University, China)
- 16:00 Wed-A-V-3-8 478 SpeechMoE: Scaling to Large Acoustic Models with Dynamic Routing Mixture of Experts, Zhao You (Tencent, China), Shulin Feng (Tencent, China), Dan Su (Tencent, China) and Dong Yu (Tencent, USA)
- 16:00 Wed-A-V-3-9 545 Online Compressive Transformer for End-to-End Speech Recognition, Chi-Hang Leong (NYCU, Taiwan), Yu-Han Huang (NYCU, Taiwan) and Jen-Tzung Chien (NYCU, Taiwan)
- 16:00 Wed-A-V-3-10 774 End to End Transformer-Based Contextual Speech Recognition Based on Pointer Network, Binghuai Lin (Tencent, China) and Liyuan Wang (Tencent, China)
- 16:00 Wed-A-V-3-11 775 A Comparative Study on Neural Architectures and Training Methods for Japanese Speech Recognition, Shigeki Karita (Google, Japan), Yotaro Kubo (Google, Japan), Michiel Adriaan Unico Bacchiani (Google, Japan) and Llion Jones (Google, Japan)
- 16:00 Wed-A-V-3-12 1643 Advanced Long-Context End-to-End Speech Recognition Using Context-Expanded Transformers, Takaaki Hori (MERL, USA), Niko Moritz (MERL, USA), Chiori Hori (MERL, USA) and Jonathan Le Roux (MERL, USA)
- 16:00 Wed-A-V-3-13 1743 Transformer-Based ASR Incorporating Time-Reduction Layer and Fine-Tuning with Self-Knowledge Distillation, Md. Akmal Haidar (Huawei Technologies, Canada), Chao Xing (Huawei Technologies, Canada) and Mehdi Rezagholizadeh (Huawei Technologies, Canada)
- 16:00 Wed-A-V-3-14 1921 Flexi-Transducer: Optimizing Latency, Accuracy and Compute for Multi-Domain On-Device Scenarios, Jay Mahadeokar (Facebook, USA), Yangyang Shi (Facebook, USA), Yuan Shangguan (Facebook, USA), Chunyang Wu (Facebook, USA), Alex Xiao (Facebook, USA), Hang Su (Facebook, USA), Duc Le (Facebook, USA), Ozlem Kalinli (Facebook, USA), Christian Fuegen (Facebook, USA) and Michael L. Seltzer (Facebook, USA)
Wed-A-V-4 Wednesday, September 1, 16:00-18:00 Virtual: Speech Localization, Enhancement, and Quality Assessment
- 16:00 Wed-A-V-4-1 16 Difference in Perceived Speech Signal Quality Assessment Among Monolingual and Bilingual Teenage Students, Przemyslaw Falkowski-Gilski (Gdansk University of Technology, Poland)
- 16:00 Wed-A-V-4-2 124 PILOT: Introducing Transformers for Probabilistic Sound Event Localization, Christopher Schymura (Ruhr-Universität Bochum, Germany), Benedikt Bönninghoff (Ruhr-Universität Bochum, Germany), Tsubasa Ochiai (NTT, Japan), Marc Delcroix (NTT, Japan), Keisuke Kinoshita (NTT, Japan), Tomohiro Nakatani (NTT, Japan), Shoko Araki (NTT, Japan) and Dorothea Kolossa (Ruhr-Universität Bochum, Germany)
- 16:00 Wed-A-V-4-3 126 Sound Source Localization with Majorization Minimization, Masahito Togami (LINE, Japan) and Robin Scheibler (LINE, Japan)
- 16:00 Wed-A-V-4-4 299 NISQA: A Deep CNN-Self-Attention Model for Multidimensional Speech Quality Prediction with Crowdsourced Datasets, Gabriel Mittag (Technische Universität Berlin, Germany), Babak Naderi (Technische Universität Berlin, Germany), Assmaa Chehadi (Technische Universität Berlin, Germany) and Sebastian Möller (Technische Universität Berlin, Germany)
- 16:00 Wed-A-V-4-5 343 Subjective Evaluation of Noise Suppression Algorithms in Crowdsourcing, Babak Naderi (Technische Universität Berlin, Germany) and Ross Cutler (Microsoft, USA)
- 16:00 Wed-A-V-4-6 375 Reliable Intensity Vector Selection for Multi-Source Direction-of-Arrival Estimation Using a Single Acoustic Vector Sensor, Jianhua Geng (ShanghaiTech University, China), Sifan Wang (ShanghaiTech University, China), Juan Li (ShanghaiTech University, China), JingWei Li (ShanghaiTech University, China) and Xin Lou (ShanghaiTech University, China)
- 16:00 Wed-A-V-4-7 659 MetricNet: Towards Improved Modeling For Non-Intrusive Speech Quality Assessment, Meng Yu (Tencent, USA), Chunlei Zhang (Tencent, USA), Yong Xu (Tencent, USA), Shi-Xiong Zhang (Tencent, USA) and Dong Yu (Tencent, USA)
- 16:00 Wed-A-V-4-8 886 CNN-Based Processing of Acoustic and Radio Frequency Signals for Speaker Localization from MAVs, Andrea Toma (Università di Udine, Italy), Daniele Salvati (Università di Udine, Italy), Carlo Drioli (Università di Udine, Italy) and Gian Luca Foresti (Università di Udine, Italy)
- 16:00 Wed-A-V-4-9 1050 Assessment of von Mises-Bernoulli Deep Neural Network in Sound Source Localization, Katsutoshi Itoyama (Tokyo Tech, Japan), Yoshiya Morimoto (Tokyo Tech, Japan), Shungo Masaki (Tokyo Tech, Japan), Ryosuke Kojima (Kyoto University, Japan), Kenji Nishida (Tokyo Tech, Japan) and Kazuhiro Nakadai (Tokyo Tech, Japan)
- 16:00 Wed-A-V-4-10 1051 Feature Fusion by Attention Networks for Robust DOA Estimation, Rongliang Liu (Shenzhen University, China), Nengheng Zheng (Shenzhen University, China) and Xi Chen (Shenzhen University, China)
- 16:00 Wed-A-V-4-11 1160 Far-Field Speaker Localization and Adaptive GLMB Tracking, Shoufeng Lin (Curtin University, Australia) and Zhaojie Luo (Osaka University, Japan)
- 16:00 Wed-A-V-4-12 1890 On the Design of Deep Priors for Unsupervised Audio Restoration, Vivek Sivaraman Narayanaswamy (Arizona State University, USA), Jayaraman J. Thiagarajan (LLNL, USA) and Andreas Spanias (Arizona State University, USA)
- 16:00 Wed-A-V-4-13 2267 Cramér-Rao Lower Bound for DOA Estimation with an Array of Directional Microphones in Reverberant Environments, Weiguang Chen (Hunan University, China), Cheng Xue (Hunan University, China) and Xionghu Zhong (Hunan University, China)
Wed-A-V-5 Wednesday, September 1, 16:00-18:00 Virtual: Speech Synthesis: Neural Waveform Generation
- 16:00 Wed-A-V-5-1 41 GAN Vocoder: Multi-Resolution Discriminator Is All You Need, Jaeseong You (MoneyBrain, Korea), Dalhyun Kim (MoneyBrain, Korea), Gyuhyeon Nam (MoneyBrain, Korea), Geumbyeol Hwang (MoneyBrain, Korea) and Gyeongsu Chae (MoneyBrain, Korea)
- 16:00 Wed-A-V-5-2 414 Glow-WaveGAN: Learning Speech Representations from GAN-Based Variational Auto-Encoder for High Fidelity Flow-Based Speech Synthesis, Jian Cong (Northwestern Polytechnical University, China), Shan Yang (Tencent, China), Lei Xie (Northwestern Polytechnical University, China) and Dan Su (Tencent, China)
- 16:00 Wed-A-V-5-3 517 Unified Source-Filter GAN: Unified Source-Filter Network Based On Factorization of Quasi-Periodic Parallel WaveGAN, Reo Yoneyama (Nagoya University, Japan), Yi-Chiao Wu (Nagoya University, Japan) and Tomoki Toda (Nagoya University, Japan)
- 16:00 Wed-A-V-5-4 583 Harmonic WaveGAN: GAN-Based Speech Waveform Generation Model with Harmonic Structure Discriminator, Kazuki Mizuta (University of Tokyo, Japan), Tomoki Koriyama (University of Tokyo, Japan) and Hiroshi Saruwatari (University of Tokyo, Japan)
- 16:00 Wed-A-V-5-5 845 Fre-GAN: Adversarial Frequency-Consistent Audio Synthesis, Ji-Hoon Kim (Korea University, Korea), Sang-Hoon Lee (Korea University, Korea), Ji-Hyun Lee (Korea University, Korea) and Seong-Whan Lee (Korea University, Korea)
- 16:00 Wed-A-V-5-6 971 GANSpeech: Adversarial Training for High-Fidelity Multi-Speaker Speech Synthesis, Jinhyeok Yang (NCSOFT, Korea), Jae-Sung Bae (NCSOFT, Korea), Taejun Bak (NCSOFT, Korea), Young-Ik Kim (NCSOFT, Korea) and Hoon-Young Cho (NCSOFT, Korea)
- 16:00 Wed-A-V-5-7 1016 UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation, Won Jang (Kakao, Korea), Dan Lim (Kakao, Korea), Jaesam Yoon (Kakao, Korea), Bongwan Kim (Kakao, Korea) and Juntae Kim (Kakao, Korea)
- 16:00 Wed-A-V-5-8 1600 Continuous Wavelet Vocoder-Based Decomposition of Parametric Speech Waveform Synthesis, Mohammed Salah Al-Radhi (BME, Hungary), Tamás Gábor Csapó (BME, Hungary), Csaba Zainkó (BME, Hungary) and Géza Németh (BME, Hungary)
- 16:00 Wed-A-V-5-9 1984 High-Fidelity and Low-Latency Universal Neural Vocoder Based on Multiband WaveRNN with Data-Driven Linear Prediction for Discrete Waveform Modeling, Patrick Lumban Tobing (Nagoya University, Japan) and Tomoki Toda (Nagoya University, Japan)
- 16:00 Wed-A-V-5-10 2173 Basis-MelGAN: Efficient Neural Vocoder Based on Audio Decomposition, Zhengxi Liu (Sun Yat-sen University, China) and Yanmin Qian (SJTU, China)
- 16:00 Wed-A-V-5-11 976 High-Fidelity Parallel WaveGAN with Multi-Band Harmonic-Plus-Noise Model, Min-Jae Hwang (Search Solutions, Korea), Ryuichi Yamamoto (LINE, Japan), Eunwoo Song (Naver, Korea) and Jae-Min Kim (Naver, Korea)
Wed-A-V-6 Wednesday, September 1, 16:00-18:00 Virtual: Spoken machine translation
- 16:00 Wed-A-V-6-1 733 SpecRec: An Alternative Solution for Improving End-to-End Speech-to-Text Translation via Spectrogram Reconstruction, Junkun Chen (Oregon State University, USA), Mingbo Ma (Baidu, USA), Renjie Zheng (Baidu, USA) and Liang Huang (Baidu, USA)
- 16:00 Wed-A-V-6-2 744 Subtitle Translation as Markup Translation, Colin Cherry (Google, USA), Naveen Arivazhagan (Google, USA), Dirk Padfield (Google, USA) and Maxim Krikun (Google, USA)
- 16:00 Wed-A-V-6-3 1912 Large-Scale Self- and Semi-Supervised Learning for Speech Translation, Changhan Wang (Facebook, USA), Anne Wu (Facebook, USA), Juan Pino (Facebook, USA), Alexei Baevski (Facebook, USA), Michael Auli (Facebook, USA) and Alexis Conneau (Facebook, USA)
- 16:00 Wed-A-V-6-4 2027 CoVoST 2 and Massively Multilingual Speech Translation, Changhan Wang (Facebook, USA), Anne Wu (Facebook, USA), Jiatao Gu (Facebook, USA) and Juan Pino (Facebook, USA)
- 16:00 Wed-A-V-6-5 526 AlloST: Low-Resource Speech Translation Without Source Transcription, Yao-Fei Cheng (Academia Sinica, Taiwan), Hung-Shin Lee (Academia Sinica, Taiwan) and Hsin-Min Wang (Academia Sinica, Taiwan)
- 16:00 Wed-A-V-6-6 970 Weakly-Supervised Speech-to-Text Mapping with Visually Connected Non-Parallel Speech-Text Data Using Cyclic Partially-Aligned Transformer, Johanes Effendi (NAIST, Japan), Sakriani Sakti (NAIST, Japan) and Satoshi Nakamura (NAIST, Japan)
- 16:00 Wed-A-V-6-7 1020 Transcribing Paralinguistic Acoustic Cues to Target Language Text in Transformer-Based Speech-to-Text Translation, Hirotaka Tokuyama (NAIST, Japan), Sakriani Sakti (NAIST, Japan), Katsuhito Sudoh (NAIST, Japan) and Satoshi Nakamura (NAIST, Japan)
- 16:00 Wed-A-V-6-8 1065 End-to-End Speech Translation via Cross-Modal Progressive Training, Rong Ye (ByteDance, China), Mingxuan Wang (ByteDance, China) and Lei Li (ByteDance, China)
- 16:00 Wed-A-V-6-9 1105 ASR Posterior-Based Loss for Multi-Task End-to-End Speech Translation, Yuka Ko (NAIST, Japan), Katsuhito Sudoh (NAIST, Japan), Sakriani Sakti (NAIST, Japan) and Satoshi Nakamura (NAIST, Japan)
- 16:00 Wed-A-V-6-10 201 Towards Simultaneous Machine Interpretation, Alejandro Pérez-González-de-Martos (Universitat Politècnica de València, Spain), Javier Iranzo-Sánchez (Universitat Politècnica de València, Spain), Adrià Giménez Pastor (Universitat Politècnica de València, Spain), Javier Jorge (Universitat Politècnica de València, Spain), Joan-Albert Silvestre-Cerdà (Universitat Politècnica de València, Spain), Jorge Civera (Universitat Politècnica de València, Spain), Albert Sanchis (Universitat Politècnica de València, Spain) and Alfons Juan (Universitat Politècnica de València, Spain)
- 16:00 Wed-A-V-6-11 265 Lexical Modeling of ASR Errors for Robust Speech Translation, Giuseppe Martucci (Università di Trento, Italy), Mauro Cettolo (FBK, Italy), Matteo Negri (FBK, Italy) and Marco Turchi (FBK, Italy)
- 16:00 Wed-A-V-6-12 2007 Optimally Encoding Inductive Biases into the Transformer Improves End-to-End Speech Translation, Piyush Vyas (Indiana University, USA), Anastasia Kuznetsova (Indiana University, USA) and Donald S. Williamson (Indiana University, USA)
- 16:00 Wed-A-V-6-13 1863 Effects of Feature Scaling and Fusion on Sign Language Translation, Tejaswini Ananthanarayana (Rochester Institute of Technology, USA), Lipisha Chaudhary (Rochester Institute of Technology, USA) and Ifeoma Nwogu (Rochester Institute of Technology, USA)
Wed-A-SS-1 Wednesday, September 1, 16:00-18:00 Special-Virtual: SdSV Challenge 2021: Analysis and Exploration of New Ideas on Short-Duration Speaker Verification
- 16:00 Wed-A-SS-1-1 1553 The ID R&D System Description for Short-Duration Speaker Verification Challenge 2021, Alexander Alenin (ID R&D, USA), Anton Okhotnikov (ID R&D, USA), Rostislav Makarov (ID R&D, USA), Nikita Torgashov (ID R&D, USA), Ilya Shigabeev (ID R&D, USA) and Konstantin Simonchik (ID R&D, USA)
- 16:00 Wed-A-SS-1-2 1570 Integrating Frequency Translational Invariance in TDNNs and Frequency Positional Information in 2D ResNets to Enhance Speaker Verification, Jenthe Thienpondt (Ghent University, Belgium), Brecht Desplanques (Ghent University, Belgium) and Kris Demuynck (Ghent University, Belgium)
- 16:00 Wed-A-SS-1-3 1737 SdSVC Challenge 2021: Tips and Tricks to Boost the Short-Duration Speaker Verification System Performance, Aleksei Gusev (ITMO University, Russia), Alisa Vinogradova (ITMO University, Russia), Sergey Novoselov (ITMO University, Russia) and Sergei Astapov (ITMO University, Russia)
- 16:00 Wed-A-SS-1-4 249 Team02 Text-Independent Speaker Verification System for SdSV Challenge 2021, Woo Hyun Kang (CRIM, Canada) and Nam Soo Kim (Seoul National University, Korea)
- 16:00 Wed-A-SS-1-5 398 Our Learned Lessons from Cross-Lingual Speaker Verification: The CRMI-DKU System Description for the Short-Duration Speaker Verification Challenge 2021, Xiaoyi Qin (Wuhan University, China), Chao Wang (China Mobile, China), Yong Ma (China Mobile, China), Min Liu (China Mobile, China), Shilei Zhang (China Mobile, China) and Ming Li (Wuhan University, China)
- 16:00 Wed-A-SS-1-6 743 Investigation of IMU&Elevoc Submission for the Short-Duration Speaker Verification Challenge 2021, Peng Zhang (Inner Mongolia University, China), Peng Hu (Elevoc Technology, China) and Xueliang Zhang (Inner Mongolia University, China)
- 16:00 Wed-A-SS-1-7 965 The Sogou System for Short-Duration Speaker Verification Challenge 2021, Jie Yan (Sogou, China), Shengyu Yao (Sogou, China), Yiqian Pan (Sogou, China) and Wei Chen (Sogou, China)
- 16:00 Wed-A-SS-1-8 2136 The SJTU System for Short-Duration Speaker Verification Challenge 2021, Bing Han (SJTU, China), Zhengyang Chen (SJTU, China), Zhikai Zhou (SJTU, China) and Yanmin Qian (SJTU, China)
Wed-A-S&T-1 Wednesday, September 1, 16:00-18:00 Show and Tell: Show and Tell 2
- 16:00 Wed-A-S&T-1-1 ST08 Multi-Speaker Emotional Text-to-Speech Synthesizer, Sungjae Cho (KIST, Korea) and Soo-Young Lee (KAIST, Korea)
- 16:00 Wed-A-S&T-1-2 ST09 Live TV Subtitling Through Respeaking, Aleš Pražák (University of West Bohemia, Czech Republic), Zdeněk Loose (SpeechTech, Czech Republic), Josef V. Psutka (University of West Bohemia, Czech Republic), Vlasta Radová (University of West Bohemia, Czech Republic), Josef Psutka (University of West Bohemia, Czech Republic) and Jan Švec (University of West Bohemia, Czech Republic)
- 16:00 Wed-A-S&T-1-3 ST10 Autonomous Robot for Measuring Room Impulse Responses, Stefan Fragner (Technische Universität Graz, Austria), Tobias Topar (Technische Universität Graz, Austria), Maximilian Giller (Technische Universität Graz, Austria), Lukas Pfeifenberger (Evolve, Austria) and Franz Pernkopf (Technische Universität Graz, Austria)
- 16:00 Wed-A-S&T-1-4 ST11 Expressive Robot Performance Based on Facial Motion Capture, Jonas Beskow (Furhat Robotics, Sweden), Charlie Caper (Furhat Robotics, Sweden), Johan Ehrenfors (Furhat Robotics, Sweden), Nils Hagberg (Furhat Robotics, Sweden), Anne Jansen (Furhat Robotics, Sweden) and Chris Wood (Furhat Robotics, Sweden)
- 16:00 Wed-A-S&T-1-5 ST12 ThemePro 2.0: Showcasing the Role of Thematic Progression in Engaging Human-Computer Interaction, Mónica Domínguez (Universitat Pompeu Fabra, Spain), Juan Soler-Company (Universitat Pompeu Fabra, Spain) and Leo Wanner (Universitat Pompeu Fabra, Spain)
- 16:00 Wed-A-S&T-1-6 ST13 Addressing Compliance in Call Centers with Entity Extraction, Sai Guruju (Observe.AI, India) and Jithendra Vepa (Observe.AI, India)
- 16:00 Wed-A-S&T-1-7 ST14 Audio Segmentation Based Conversational Silence Detection for Contact Center Calls, Krishnachaitanya Gogineni (Observe.AI, India), Tarun Reddy Yadama (Observe.AI, India) and Jithendra Vepa (Observe.AI, India)
Wed-E-O-1 Wednesday, September 1, 19:00-21:00 In-person Oral: Graph and End-to-End Learning for Speaker Recognition
- 19:00 Wed-E-O-1-1 323 Reformulating DOVER-Lap Label Mapping as a Graph Partitioning Problem, Desh Raj (Johns Hopkins University, USA) and Sanjeev Khudanpur (Johns Hopkins University, USA)
- 19:20 Wed-E-O-1-2 993 Graph Attention Networks for Anti-Spoofing, Hemlata Tak (EURECOM, France), Jee-weon Jung (Naver, Korea), Jose Patino (EURECOM, France), Massimiliano Todisco (EURECOM, France) and Nicholas Evans (EURECOM, France)
- 19:40 Wed-E-O-1-3 1085 Log-Likelihood-Ratio Cost Function as Objective Loss for Speaker Verification Systems, Victoria Mingote (Universidad de Zaragoza, Spain), Antonio Miguel (Universidad de Zaragoza, Spain), Alfonso Ortega (Universidad de Zaragoza, Spain) and Eduardo Lleida (Universidad de Zaragoza, Spain)
- 20:00 Wed-E-O-1-4 2025 Effective Phase Encoding for End-To-End Speaker Verification, Junyi Peng (Ping An Technology, China), Xiaoyang Qu (Ping An Technology, China), Rongzhi Gu (Peking University, China), Jianzong Wang (Ping An Technology, China), Jing Xiao (Ping An Technology, China), Lukáš Burget (Brno University of Technology, Czech Republic) and Jan Černocký (Brno University of Technology, Czech Republic)
Wed-E-O-2 Wednesday, September 1, 19:00-21:00 In-person Oral: Spoken Language Processing II
- 19:00 Wed-E-O-2-1 608 Impact of Encoding and Segmentation Strategies on End-to-End Simultaneous Speech Translation, Ha Nguyen (LIG (UMR 5217), France), Yannick Estève (LIA (EA 4128), France) and Laurent Besacier (LIG (UMR 5217), France)
- 19:20 Wed-E-O-2-2 2232 Lost in Interpreting: Speech Translation from Source or Interpreter?, Dominik Macháček (Charles University, Czech Republic), Matúš Žilinec (Charles University, Czech Republic) and Ondřej Bojar (Charles University, Czech Republic)
- 19:40 Wed-E-O-2-3 80 Active Speaker Detection as a Multi-Objective Optimization with Uncertainty-Based Multimodal Fusion, Baptiste Pouthier (NXP Semiconductors, France), Laurent Pilati (NXP Semiconductors, France), Leela K. Gudupudi (NXP Semiconductors, France), Charles Bouveyron (I3S (UMR 7271), France) and Frederic Precioso (I3S (UMR 7271), France)
- 20:00 Wed-E-O-2-4 1658 It’s Not What You Said, it’s How You Said it: Discriminative Perception of Speech as a Multichannel Communication System, Sarenne Wallbridge (University of Edinburgh, UK), Peter Bell (University of Edinburgh, UK) and Catherine Lai (University of Edinburgh, UK)
Wed-E-O-3 Wednesday, September 1, 19:00-21:00 In-person Oral: Speech and audio analysis
- 19:00 Wed-E-O-3-1 314 Extending the Fullband E-Model Towards Background Noise, Bursty Packet Loss, and Conversational Degradations, Thilo Michael (Technische Universität Berlin, Germany), Gabriel Mittag (Technische Universität Berlin, Germany), Andreas Bütow (Technische Universität Berlin, Germany) and Sebastian Möller (Technische Universität Berlin, Germany)
- 19:20 Wed-E-O-3-2 616 ORCA-SLANG: An Automatic Multi-Stage Semi-Supervised Deep Learning Framework for Large-Scale Killer Whale Call Type Identification, Christian Bergler (FAU Erlangen-Nürnberg, Germany), Manuel Schmitt (FAU Erlangen-Nürnberg, Germany), Andreas Maier (FAU Erlangen-Nürnberg, Germany), Helena Symonds (OrcaLab, Canada), Paul Spong (OrcaLab, Canada), Steven R. Ness (University of Victoria, Canada), George Tzanetakis (University of Victoria, Canada) and Elmar Nöth (FAU Erlangen-Nürnberg, Germany)
- 19:40 Wed-E-O-3-3 695 Audiovisual Transfer Learning for Audio Tagging and Sound Event Detection, Wim Boes (KU Leuven, Belgium) and Hugo Van hamme (KU Leuven, Belgium)
- 20:00 Wed-E-O-3-4 1685 Non-Intrusive Speech Quality Assessment with Transfer Learning and Subject-Specific Scaling, Natalia Nessler (EPFL, Switzerland), Milos Cernak (Logitech, Switzerland), Paolo Prandoni (EPFL, Switzerland) and Pablo Mainar (Logitech, Switzerland)
- 20:20 Wed-E-O-3-5 2227 Audio Retrieval with Natural Language Queries, Andreea-Maria Oncescu (University of Oxford, UK), A. Sophia Koepke (Universität Tübingen, Germany), João F. Henriques (University of Oxford, UK), Zeynep Akata (Universität Tübingen, Germany) and Samuel Albanie (University of Oxford, UK)
Wed-E-V-1 Wednesday, September 1, 19:00-21:00 Virtual: Cross/multi-lingual and code-switched ASR
- 19:00 Wed-E-V-1-1 198 Bootstrap an End-to-End ASR System by Multilingual Training, Transfer Learning, Text-to-Text Mapping and Synthetic Audio, Manuel Giollo (Amazon, Italy), Deniz Gunceler (Amazon, Germany), Yulan Liu (Amazon, UK) and Daniel Willett (Amazon, Germany)
- 19:00 Wed-E-V-1-2 216 Efficient Weight Factorization for Multilingual Speech Recognition, Ngoc-Quan Pham (KIT, Germany), Tuan-Nam Nguyen (KIT, Germany), Sebastian Stüker (KIT, Germany) and Alex Waibel (KIT, Germany)
- 19:00 Wed-E-V-1-3 329 Unsupervised Cross-Lingual Representation Learning for Speech Recognition, Alexis Conneau (Facebook, USA), Alexei Baevski (Facebook, USA), Ronan Collobert (Facebook, USA), Abdelrahman Mohamed (Facebook, USA) and Michael Auli (Facebook, USA)
- 19:00 Wed-E-V-1-4 390 Language and Speaker-Independent Feature Transformation for End-to-End Multilingual Speech Recognition, Tomoaki Hayakawa (University of Yamanashi, Japan), Chee Siang Leow (University of Yamanashi, Japan), Akio Kobayashi (NTUT, Japan), Takehito Utsuro (University of Tsukuba, Japan) and Hiromitsu Nishizaki (University of Yamanashi, Japan)
- 19:00 Wed-E-V-1-5 631 Using Large Self-Supervised Models for Low-Resource Speech Recognition, Krishna D. N. (Freshworks, India), Pinyi Wang (Freshworks, India) and Bruno Bozza (Freshworks, India)
- 19:00 Wed-E-V-1-6 978 Dual Script E2E Framework for Multilingual and Code-Switching ASR, Mari Ganesh Kumar (IIT Madras, India), Jom Kuriakose (IIT Madras, India), Anand Thyagachandran (IIT Madras, India), Arun Kumar A. (IIT Madras, India), Ashish Seth (IIT Madras, India), Lodagala V.S.V. Durga Prasad (IIT Madras, India), Saish Jaiswal (IIT Madras, India), Anusha Prakash (IIT Madras, India) and Hema A. Murthy (IIT Madras, India)
- 19:00 Wed-E-V-1-7 1339 MUCS 2021: Multilingual and Code-Switching ASR Challenges for Low Resource Indian Languages, Anuj Diwan (IIT Bombay, India), Rakesh Vaideeswaran (Indian Institute of Science, India), Sanket Shah (Microsoft, India), Ankita Singh (IIT Bombay, India), Srinivasa Raghavan (Navana Tech, India), Shreya Khare (IBM, India), Vinit Unni (IIT Bombay, India), Saurabh Vyas (Navana Tech, India), Akash Rajpuria (Navana Tech, India), Chiranjeevi Yarra (IIIT Hyderabad, India), Ashish Mittal (IBM, India), Prasanta Kumar Ghosh (Indian Institute of Science, India), Preethi Jyothi (IIT Bombay, India), Kalika Bali (Microsoft, India), Vivek Seshadri (Microsoft, India), Sunayana Sitaram (Microsoft, India), Samarth Bharadwaj (IBM, India), Jai Nanavati (Navana Tech, India), Raoul Nanavati (Navana Tech, India) and Karthik Sankaranarayanan (IBM, India)
- 19:00 Wed-E-V-1-8 1390 Adapt-and-Adjust: Overcoming the Long-Tail Problem of Multilingual Speech Recognition, Genta Indra Winata (HKUST, China), Guangsen Wang (Salesforce, Singapore), Caiming Xiong (Salesforce, USA) and Steven Hoi (Salesforce, Singapore)
- 19:00 Wed-E-V-1-9 1578 SRI-B End-to-End System for Multilingual and Code-Switching ASR Challenges for Low Resource Indian Languages, Hardik Sailor (Samsung, India), Kiran Praveen T. (Samsung, India), Vikas Agrawal (Samsung, India), Abhinav Jain (Samsung, India) and Abhishek Pandey (Samsung, India)
- 19:00 Wed-E-V-1-10 1803 Hierarchical Phone Recognition with Compositional Phonetics, Xinjian Li (Carnegie Mellon University, USA), Juncheng Li (Carnegie Mellon University, USA), Florian Metze (Carnegie Mellon University, USA) and Alan W. Black (Carnegie Mellon University, USA)
- 19:00 Wed-E-V-1-11 1809 Towards One Model to Rule All: Multilingual Strategy for Dialectal Code-Switching Arabic ASR, Shammur Absar Chowdhury (HBKU, Qatar), Amir Hussein (HBKU, Qatar), Ahmed Abdelali (HBKU, Qatar) and Ahmed Ali (HBKU, Qatar)
- 19:00 Wed-E-V-1-12 1944 Differentiable Allophone Graphs for Language-Universal Speech Recognition, Brian Yan (Carnegie Mellon University, USA), Siddharth Dalmia (Carnegie Mellon University, USA), David R. Mortensen (Carnegie Mellon University, USA), Florian Metze (Carnegie Mellon University, USA) and Shinji Watanabe (Carnegie Mellon University, USA)
Wed-E-V-2 Wednesday, September 1, 19:00-21:00 Virtual: Health and Affect II
- 19:00 Wed-E-V-2-1 291 Automatic Speech Recognition Systems Errors for Objective Sleepiness Detection Through Voice, Vincent P. Martin (LaBRI (UMR 5800), France), Jean-Luc Rouas (LaBRI (UMR 5800), France), Florian Boyer (LaBRI (UMR 5800), France) and Pierre Philip (SANPSY (USR 3413), France)
- 19:00 Wed-E-V-2-2 353 Robust Laughter Detection in Noisy Environments, Jon Gillick (University of California at Berkeley, USA), Wesley Deng (University of California at Berkeley, USA), Kimiko Ryokai (University of California at Berkeley, USA) and David Bamman (University of California at Berkeley, USA)
- 19:00 Wed-E-V-2-3 827 Impact of Emotional State on Estimation of Willingness to Buy from Advertising Speech, Mizuki Nagano (NTT, Japan), Yusuke Ijima (NTT, Japan) and Sadao Hiroya (NTT, Japan)
- 19:00 Wed-E-V-2-4 904 Stacked Recurrent Neural Networks for Speech-Based Inference of Attachment Condition in School Age Children, Huda Alsofyani (University of Glasgow, UK) and Alessandro Vinciarelli (University of Glasgow, UK)
- 19:00 Wed-E-V-2-5 928 Language or Paralanguage, This is the Problem: Comparing Depressed and Non-Depressed Speakers Through the Analysis of Gated Multimodal Units, Nujud Aloshban (University of Glasgow, UK), Anna Esposito (Università della Campania “Luigi Vanvitelli”, Italy) and Alessandro Vinciarelli (University of Glasgow, UK)
- 19:00 Wed-E-V-2-6 1100 Emotion Carrier Recognition from Personal Narratives, Aniruddha Tammewar (Università di Trento, Italy), Alessandra Cervone (Università di Trento, Italy) and Giuseppe Riccardi (Università di Trento, Italy)
- 19:00 Wed-E-V-2-7 1159 Non-Verbal Vocalisation and Laughter Detection Using Sequence-to-Sequence Models and Multi-Label Training, Scott Condron (Speech Graphics, UK), Georgia Clarke (Speech Graphics, UK), Anita Klementiev (Speech Graphics, UK), Daniela Morse-Kopp (Speech Graphics, UK), Jack Parry (Speech Graphics, UK) and Dimitri Palaz (Speech Graphics, UK)
- 19:00 Wed-E-V-2-8 1176 TDCA-Net: Time-Domain Channel Attention Network for Depression Detection, Cong Cai (CAS, China), Mingyue Niu (CAS, China), Bin Liu (CAS, China), Jianhua Tao (CAS, China) and Xuefei Liu (CAS, China)
- 19:00 Wed-E-V-2-9 1717 Visual Speech for Obstructive Sleep Apnea Detection, Catarina Botelho (INESC-ID Lisboa, Portugal), Alberto Abad (INESC-ID Lisboa, Portugal), Tanja Schultz (Universität Bremen, Germany) and Isabel Trancoso (INESC-ID Lisboa, Portugal)
- 19:00 Wed-E-V-2-10 1932 Analysis of Contextual Voice Changes in Remote Meetings, Hector A. Cordourier Maruri (Intel, Mexico), Sinem Aslan (Intel, USA), Georg Stemmer (Intel, Germany), Nese Alyuz (Intel, USA) and Lama Nachman (Intel, USA)
- 19:00 Wed-E-V-2-11 1967 Speech Based Depression Severity Level Classification Using a Multi-Stage Dilated CNN-LSTM Model, Nadee Seneviratne (University of Maryland at College Park, USA) and Carol Espy-Wilson (University of Maryland at College Park, USA)
Wed-E-V-3 Wednesday, September 1, 19:00-21:00 Virtual: Neural network training methods for ASR
- 19:00 Wed-E-V-3-1 1169 Multi-Domain Knowledge Distillation via Uncertainty-Matching for End-to-End ASR Models, Ho-Gyeong Kim (Samsung, Korea), Min-Joong Lee (Samsung, Korea), Hoshik Lee (Samsung, Korea), Tae Gyoon Kang (Samsung, Korea), Jihyun Lee (Samsung, Korea), Eunho Yang (KAIST, Korea) and Sung Ju Hwang (KAIST, Korea)
- 19:00 Wed-E-V-3-2 1575 Learning a Neural Diff for Speech Models, Jonathan Macoskey (Amazon, USA), Grant P. Strimel (Amazon, USA) and Ariya Rastrow (Amazon, USA)
- 19:00 Wed-E-V-3-3 280 Stochastic Attention Head Removal: A Simple and Effective Method for Improving Transformer Based ASR Models, Shucong Zhang (University of Edinburgh, UK), Erfan Loweimi (University of Edinburgh, UK), Peter Bell (University of Edinburgh, UK) and Steve Renals (University of Edinburgh, UK)
- 19:00 Wed-E-V-3-4 355 Model-Agnostic Fast Adaptive Multi-Objective Balancing Algorithm for Multilingual Automatic Speech Recognition Model Training, Jiabin Xue (Harbin Institute of Technology, China), Tieran Zheng (Harbin Institute of Technology, China) and Jiqing Han (Harbin Institute of Technology, China)
- 19:00 Wed-E-V-3-5 563 Towards Lifelong Learning of End-to-End ASR, Heng-Jui Chang (National Taiwan University, Taiwan), Hung-yi Lee (National Taiwan University, Taiwan) and Lin-shan Lee (National Taiwan University, Taiwan)
- 19:00 Wed-E-V-3-6 614 Self-Adaptive Distillation for Multilingual Speech Recognition: Leveraging Student Independence, Isabel Leal (Google, USA), Neeraj Gaur (Google, USA), Parisa Haghani (Google, USA), Brian Farris (Google, USA), Pedro J. Moreno (Google, USA), Manasa Prasad (Google, USA), Bhuvana Ramabhadran (Google, USA) and Yun Zhu (Google, USA)
- 19:00 Wed-E-V-3-7 648 Regularizing Word Segmentation by Creating Misspellings, Hainan Xu (Google, USA), Kartik Audhkhasi (Google, USA), Yinghui Huang (Google, USA), Jesse Emond (Google, USA) and Bhuvana Ramabhadran (Google, USA)
- 19:00 Wed-E-V-3-8 683 Multitask Training with Text Data for End-to-End Speech Recognition, Peidong Wang (Google, USA), Tara N. Sainath (Google, USA) and Ron J. Weiss (Google, USA)
- 19:00 Wed-E-V-3-9 894 Emitting Word Timings with HMM-Free End-to-End System in Automatic Speech Recognition, Xianzhao Chen (Tianjin University, China), Hao Ni (ByteDance, China), Yi He (ByteDance, China), Kang Wang (ByteDance, China), Zejun Ma (ByteDance, China) and Zongxia Xie (Tianjin University, China)
- 19:00 Wed-E-V-3-10 1644 Scaling Laws for Acoustic Models, Jasha Droppo (Amazon, USA) and Oguz Elibol (Amazon, USA)
- 19:00 Wed-E-V-3-11 1657 Leveraging Non-Target Language Resources to Improve ASR Performance in a Target Language, Jayadev Billa (University of Southern California, USA)
- 19:00 Wed-E-V-3-12 1962 4-Bit Quantization of LSTM-Based Speech Recognition Models, Andrea Fasoli (IBM, USA), Chia-Yu Chen (IBM, USA), Mauricio Serrano (IBM, USA), Xiao Sun (IBM, USA), Naigang Wang (IBM, USA), Swagath Venkataramani (IBM, USA), George Saon (IBM, USA), Xiaodong Cui (IBM, USA), Brian Kingsbury (IBM, USA), Wei Zhang (IBM, USA), Zoltán Tüske (IBM, USA) and Kailash Gopalakrishnan (IBM, USA)
- 19:00 Wed-E-V-3-13 2043 Unified Autoregressive Modeling for Joint End-to-End Multi-Talker Overlapped Speech Recognition and Speaker Attribute Estimation, Ryo Masumura (NTT, Japan), Daiki Okamura (NTT, Japan), Naoki Makishima (NTT, Japan), Mana Ihori (NTT, Japan), Akihiko Takashima (NTT, Japan), Tomohiro Tanaka (NTT, Japan) and Shota Orihashi (NTT, Japan)
- 19:00 Wed-E-V-3-14 2075 Minimum Word Error Rate Training with Language Model Fusion for End-to-End Speech Recognition, Zhong Meng (Microsoft, USA), Yu Wu (Microsoft, China), Naoyuki Kanda (Microsoft, USA), Liang Lu (Microsoft, USA), Xie Chen (Microsoft, USA), Guoli Ye (Microsoft, USA), Eric Sun (Microsoft, USA), Jinyu Li (Microsoft, USA) and Yifan Gong (Microsoft, USA)
- 19:00 Wed-E-V-3-15 2198 Variable Frame Rate Acoustic Models Using Minimum Error Reinforcement Learning, Dongcheng Jiang (University of Cambridge, UK), Chao Zhang (University of Cambridge, UK) and Philip C. Woodland (University of Cambridge, UK)
Wed-E-V-4 Wednesday, September 1, 19:00-21:00 Virtual: Prosodic features and structure
- 19:00 Wed-E-V-4-1 6 How f0 and Phrase Position Affect Papuan Malay Word Identification, Constantijn Kaland (Universität zu Köln, Germany) and Matthew Gordon (University of California at Santa Barbara, USA)
- 19:00 Wed-E-V-4-2 190 On the Feasibility of the Danish Model of Intonational Transcription: Phonetic Evidence from Jutlandic Danish, Anna Bothe Jespersen (Aarhus University, Denmark), Pavel Šturm (Charles University, Czech Republic) and Míša Hejná (Aarhus University, Denmark)
- 19:00 Wed-E-V-4-3 294 An Experiment in Paratone Detection in a Prosodically Annotated EAP Spoken Corpus, Adrien Méli (CLILLAC-ARP (EA 3967), France), Nicolas Ballier (CLILLAC-ARP (EA 3967), France), Achille Falaise (LLF (UMR 7110), France) and Alice Henderson (Lidilem (EA 609), France)
- 19:00 Wed-E-V-4-4 304 ProsoBeast Prosody Annotation Tool, Branislav Gerazov (UKiM, Macedonia) and Michael Wagner (McGill University, Canada)
- 19:00 Wed-E-V-4-5 373 Assessing the Use of Prosody in Constituency Parsing of Imperfect Transcripts, Trang Tran (University of Southern California, USA) and Mari Ostendorf (University of Washington, USA)
- 19:00 Wed-E-V-4-6 434 Targeted and Targetless Neutral Tones in Taiwanese Southern Min, Roger Cheng-yen Liu (National Tsing Hua University, Taiwan), Feng-fan Hsieh (National Tsing Hua University, Taiwan) and Yueh-chin Chang (National Tsing Hua University, Taiwan)
- 19:00 Wed-E-V-4-7 594 The Interaction of Word Complexity and Word Duration in an Agglutinative Language, Mária Gósy (ELKH, Hungary) and Kálmán Abari (University of Debrecen, Hungary)
- 19:00 Wed-E-V-4-8 672 Taiwan Min Nan (Taiwanese) Checked Tones Sound Change, Ho-hsien Pan (NYCU, Taiwan) and Shao-ren Lyu (NYCU, Taiwan)
- 19:00 Wed-E-V-4-9 1172 In-Group Advantage in the Perception of Emotions: Evidence from Three Varieties of German, Moritz Jakob (Universität Konstanz, Germany), Bettina Braun (Universität Konstanz, Germany) and Katharina Zahner-Ritter (Universität Trier, Germany)
- 19:00 Wed-E-V-4-10 1625 The LF Model in the Frequency Domain for Glottal Airflow Modelling Without Aliasing Distortion, Christer Gobl (Trinity College Dublin, Ireland)
- 19:00 Wed-E-V-4-11 1684 Parsing Speech for Grouping and Prominence, and the Typology of Rhythm, Michael Wagner (McGill University, Canada), Alvaro Iturralde Zurita (McGill University, Canada) and Sijia Zhang (McGill University, Canada)
- 19:00 Wed-E-V-4-12 1776 Prosody of Case Markers in Urdu, Benazir Mumtaz (Universität Konstanz, Germany), Massimiliano Canzi (Universität Konstanz, Germany) and Miriam Butt (Universität Konstanz, Germany)
- 19:00 Wed-E-V-4-13 1903 Articulatory Characteristics of Icelandic Voiced Fricative Lenition: Gradience, Categoricity, and Speaker/Gesture-Specific Effects, Brynhildur Stefansdottir (Cornell University, USA), Francesco Burroni (Cornell University, USA) and Sam Tilsen (Cornell University, USA)
- 19:00 Wed-E-V-4-14 1780 Leveraging the Uniformity Framework to Examine Crosslinguistic Similarity for Long-Lag Stops in Spontaneous Cantonese-English Bilingual Speech, Khia A. Johnson (University of British Columbia, Canada)
Wed-E-V-5 Wednesday, September 1, 19:00-21:00 Virtual: Single-channel speech enhancement
- 19:00 Wed-E-V-5-1 1868 Personalized Speech Enhancement Through Self-Supervised Data Augmentation and Purification, Aswin Sivaraman (Indiana University, USA), Sunwoo Kim (Indiana University, USA) and Minje Kim (Indiana University, USA)
- 19:00 Wed-E-V-5-2 1973 Speech Denoising with Auditory Models, Mark R. Saddler (MIT, USA), Andrew Francl (MIT, USA), Jenelle Feather (MIT, USA), Kaizhi Qian (MIT-IBM Watson AI Lab, USA), Yang Zhang (MIT-IBM Watson AI Lab, USA) and Josh H. McDermott (MIT, USA)
- 19:00 Wed-E-V-5-3 220 Human Listening and Live Captioning: Multi-Task Training for Speech Enhancement, Sefik Emre Eskimez (Microsoft, USA), Xiaofei Wang (Microsoft, USA), Min Tang (Microsoft, USA), Hemin Yang (Microsoft, USA), Zirun Zhu (Microsoft, USA), Zhuo Chen (Microsoft, USA), Huaming Wang (Microsoft, USA) and Takuya Yoshioka (Microsoft, USA)
- 19:00 Wed-E-V-5-4 520 Multi-Stage Progressive Speech Enhancement Network, Xinmeng Xu (vivo, China), Yang Wang (vivo, China), Dongxiang Xu (vivo, China), Yiyuan Peng (vivo, China), Cong Zhang (vivo, China), Jie Jia (vivo, China) and Binbin Chen (vivo, China)
- 19:00 Wed-E-V-5-5 859 Single-Channel Speech Enhancement Using Learnable Loss Mixup, Oscar Chang (Columbia University, USA), Dung N. Tran (Microsoft, USA) and Kazuhito Koishida (Microsoft, USA)
- 19:00 Wed-E-V-5-6 922 A Maximum Likelihood Approach to SNR-Progressive Learning Using Generalized Gaussian Distribution for LSTM-Based Speech Enhancement, Xiao-Qi Zhang (USTC, China), Jun Du (USTC, China), Li Chai (USTC, China) and Chin-Hui Lee (Georgia Tech, USA)
- 19:00 Wed-E-V-5-7 953 Whisper Speech Enhancement Using Joint Variational Autoencoder for Improved Speech Recognition, Vikas Agrawal (Samsung, India), Shashi Kumar (Samsung, India) and Shakti P. Rath (Reverie Language Technologies, India)
- 19:00 Wed-E-V-5-8 1025 DEMUCS-Mobile : On-Device Lightweight Speech Enhancement, Lukas Lee (Naver, Korea), Youna Ji (Naver, Korea), Minjae Lee (Naver, Korea) and Min-Seok Choi (Naver, Korea)
- 19:00 Wed-E-V-5-9 1130 Speech Denoising Without Clean Training Data: A Noise2Noise Approach, Madhav Mahesh Kashyap (PES University, India), Anuj Tambwekar (PES University, India), Krishnamoorthy Manohara (PES University, India) and S. Natarajan (PES University, India)
- 19:00 Wed-E-V-5-10 1134 Improved Speech Enhancement Using a Complex-Domain GAN with Fused Time-Domain and Time-Frequency Domain Constraints, Feng Dang (CAS, China), Pengyuan Zhang (CAS, China) and Hangting Chen (CAS, China)
- 19:00 Wed-E-V-5-11 1411 Speech Enhancement with Topology-Enhanced Generative Adversarial Networks (GANs), Xudong Zhang (CUNY Graduate Center, USA), Liang Zhao (CUNY Lehman College, USA) and Feng Gu (CUNY CSI, USA)
- 19:00 Wed-E-V-5-12 1859 Learning Speech Structure to Improve Time-Frequency Masks, Suliang Bu (Mizzou, USA), Yunxin Zhao (Mizzou, USA), Shaojun Wang (PAII, USA) and Mei Han (PAII, USA)
- 19:00 Wed-E-V-5-13 2207 SE-Conformer: Time-Domain Speech Enhancement Using Conformer, Eesung Kim (Kakao, Korea) and Hyeji Seo (Kakao, Korea)
Wed-E-V-6 Wednesday, September 1, 19:00-21:00 Virtual: Speech Synthesis: tools, data, evaluation
- 19:00 Wed-E-V-6-1 2258 Spectral and Latent Speech Representation Distortion for TTS Evaluation, Thananchai Kongthaworn (Chulalongkorn University, Thailand), Burin Naowarat (Chulalongkorn University, Thailand) and Ekapol Chuangsuwanich (Chulalongkorn University, Thailand)
- 19:00 Wed-E-V-6-2 286 Detection and Analysis of Attention Errors in Sequence-to-Sequence Text-to-Speech, Cassia Valentini-Botinhao (University of Edinburgh, UK) and Simon King (University of Edinburgh, UK)
- 19:00 Wed-E-V-6-3 341 RyanSpeech: A Corpus for Conversational Text-to-Speech Synthesis, Rohola Zandie (University of Denver, USA), Mohammad H. Mahoor (University of Denver, USA), Julia Madsen (DreamFace Technologies, USA) and Eshrat S. Emamian (DreamFace Technologies, USA)
- 19:00 Wed-E-V-6-4 755 AISHELL-3: A Multi-Speaker Mandarin TTS Corpus, Yao Shi (Wuhan University, China), Hui Bu (Beijing Shell Shell Technology, China), Xin Xu (Beijing Shell Shell Technology, China), Shaoji Zhang (Beijing Shell Shell Technology, China) and Ming Li (Wuhan University, China)
- 19:00 Wed-E-V-6-5 800 Comparing Speech Enhancement Techniques for Voice Adaptation-Based Speech Synthesis, Nicholas Eng (University of Auckland, New Zealand), C.T. Justine Hui (University of Auckland, New Zealand), Yusuke Hioka (University of Auckland, New Zealand) and Catherine I. Watson (University of Auckland, New Zealand)
- 19:00 Wed-E-V-6-6 1148 EMOVIE: A Mandarin Emotion Speech Dataset with a Simple Emotional Text-to-Speech Model, Chenye Cui (Zhejiang University, China), Yi Ren (Zhejiang University, China), Jinglin Liu (Zhejiang University, China), Feiyang Chen (Zhejiang University, China), Rongjie Huang (Zhejiang University, China), Ming Lei (Alibaba, China) and Zhou Zhao (Zhejiang University, China)
- 19:00 Wed-E-V-6-7 1229 Perception of Social Speaker Characteristics in Synthetic Speech, Sai Sirisha Rallabandi (Technische Universität Berlin, Germany), Abhinav Bharadwaj (Technische Universität Berlin, Germany), Babak Naderi (Technische Universität Berlin, Germany) and Sebastian Möller (Technische Universität Berlin, Germany)
- 19:00 Wed-E-V-6-8 1599 Hi-Fi Multi-Speaker English TTS Dataset, Evelina Bakhturina (NVIDIA, USA), Vitaly Lavrukhin (NVIDIA, USA), Boris Ginsburg (NVIDIA, USA) and Yang Zhang (NVIDIA, USA)
- 19:00 Wed-E-V-6-9 2013 Utilizing Self-Supervised Representations for MOS Prediction, Wei-Cheng Tseng (National Taiwan University, Taiwan), Chien-yu Huang (National Taiwan University, Taiwan), Wei-Tsung Kao (National Taiwan University, Taiwan), Yist Y. Lin (National Taiwan University, Taiwan) and Hung-yi Lee (National Taiwan University, Taiwan)
- 19:00 Wed-E-V-6-10 2124 KazakhTTS: An Open-Source Kazakh Text-to-Speech Synthesis Dataset, Saida Mussakhojayeva (Nazarbayev University, Kazakhstan), Aigerim Janaliyeva (Nazarbayev University, Kazakhstan), Almas Mirzakhmetov (Nazarbayev University, Kazakhstan), Yerbolat Khassanov (Nazarbayev University, Kazakhstan) and Huseyin Atakan Varol (Nazarbayev University, Kazakhstan)
- 19:00 Wed-E-V-6-11 2203 Confidence Intervals for ASR-Based TTS Evaluation, Jason Taylor (University of Edinburgh, UK) and Korin Richmond (University of Edinburgh, UK)
Wed-E-SS-1 Wednesday, September 1, 19:00-21:00 Special-Virtual: INTERSPEECH 2021 Deep Noise Suppression Challenge
- 19:00 Wed-E-SS-1-1 1609 INTERSPEECH 2021 Deep Noise Suppression Challenge, Chandan K.A. Reddy (Microsoft, USA), Harishchandra Dubey (Microsoft, USA), Kazuhito Koishida (Microsoft, USA), Arun Nair (Johns Hopkins University, USA), Vishak Gopal (Microsoft, USA), Ross Cutler (Microsoft, USA), Sebastian Braun (Microsoft, USA), Hannes Gamper (Microsoft, USA), Robert Aichner (Microsoft, USA) and Sriram Srinivasan (Microsoft, USA)
- 19:00 Wed-E-SS-1-2 1137 A Simultaneous Denoising and Dereverberation Framework with Target Decoupling, Andong Li (CAS, China), Wenzhe Liu (CAS, China), Xiaoxue Luo (CAS, China), Guochen Yu (CAS, China), Chengshi Zheng (CAS, China) and Xiaodong Li (CAS, China)
- 19:00 Wed-E-SS-1-3 936 Deep Noise Suppression with Non-Intrusive PESQNet Supervision Enabling the Use of Real Training Data, Ziyi Xu (Technische Universität Braunschweig, Germany), Maximilian Strake (Technische Universität Braunschweig, Germany) and Tim Fingscheidt (Technische Universität Braunschweig, Germany)
- 19:00 Wed-E-SS-1-4 296 DPCRN: Dual-Path Convolution Recurrent Network for Single Channel Speech Enhancement, Xiaohuai Le (Nanjing University, China), Hongsheng Chen (Nanjing University, China), Kai Chen (Nanjing University, China) and Jing Lu (Nanjing University, China)
- 20:00 Wed-E-SS-1-5 1482 DCCRN+: Channel-Wise Subband DCCRN with SNR Estimation for Speech Enhancement, Shubo Lv (Northwestern Polytechnical University, China), Yanxin Hu (Northwestern Polytechnical University, China), Shimin Zhang (Northwestern Polytechnical University, China) and Lei Xie (Northwestern Polytechnical University, China)
- 20:00 Wed-E-SS-1-6 1042 DBNet: A Dual-Branch Network Architecture Processing on Spectrum and Waveform for Single-Channel Speech Enhancement, Kanghao Zhang (Inner Mongolia University, China), Shulin He (Inner Mongolia University, China), Hao Li (Inner Mongolia University, China) and Xueliang Zhang (Inner Mongolia University, China)
- 20:00 Wed-E-SS-1-7 1410 Low-Delay Speech Enhancement Using Perceptually Motivated Target and Loss, Xu Zhang (Kuaishou Technology, China), Xinlei Ren (Kuaishou Technology, China), Xiguang Zheng (Kuaishou Technology, China), Lianwu Chen (Kuaishou Technology, China), Chen Zhang (Kuaishou Technology, China), Liang Guo (Kuaishou Technology, China) and Bing Yu (Kuaishou Technology, China)
- 20:00 Wed-E-SS-1-8 668 Lightweight Causal Transformer with Local Self-Attention for Real-Time Speech Enhancement, Koen Oostermeijer (USTC, China), Qing Wang (USTC, China) and Jun Du (USTC, China)
Thu-M-O-1 Thursday, September 2, 11:00-13:00 In-person Oral: Neural Network Training Methods and Architectures for ASR
- 11:00 Thu-M-O-1-1 155 Self-Paced Ensemble Learning for Speech and Audio Classification, Nicolae-Cătălin Ristea (UPB, Romania) and Radu Tudor Ionescu (University of Bucharest, Romania)
- 11:20 Thu-M-O-1-2 175 Knowledge Distillation for Streaming Transformer–Transducer, Atsushi Kojima (Advanced Media, Japan)
- 11:40 Thu-M-O-1-3 555 Multi-Encoder Learning and Stream Fusion for Transformer-Based End-to-End Automatic Speech Recognition, Timo Lohrenz (Technische Universität Braunschweig, Germany), Zhengyang Li (Technische Universität Braunschweig, Germany) and Tim Fingscheidt (Technische Universität Braunschweig, Germany)
- 12:00 Thu-M-O-1-4 1027 Conditional Independence for Pretext Task Selection in Self-Supervised Speech Representation Learning, Salah Zaiem (LTCI (UMR 5141), France), Titouan Parcollet (LIA (EA 4128), France) and Slim Essid (LTCI (UMR 5141), France)
- 12:20 Thu-M-O-1-5 1255 Investigating Methods to Improve Language Model Integration for Attention-Based Encoder-Decoder ASR Models, Mohammad Zeineldeen (RWTH Aachen University, Germany), Aleksandr Glushko (RWTH Aachen University, Germany), Wilfried Michel (RWTH Aachen University, Germany), Albert Zeyer (RWTH Aachen University, Germany), Ralf Schlüter (RWTH Aachen University, Germany) and Hermann Ney (RWTH Aachen University, Germany)
- 12:40 Thu-M-O-1-6 1683 Comparing CTC and LFMMI for Out-of-Domain Adaptation of wav2vec 2.0 Acoustic Model, Apoorv Vyas (Idiap Research Institute, Switzerland), Srikanth Madikeri (Idiap Research Institute, Switzerland) and Hervé Bourlard (Idiap Research Institute, Switzerland)
Thu-M-O-2 Thursday, September 2, 11:00-13:00 In-person Oral: Emotion and Sentiment Analysis I
- 11:00 Thu-M-O-2-1 573 Speaker Attentive Speech Emotion Recognition, Clément Le Moine (STMS (UMR 9912), France), Nicolas Obin (STMS (UMR 9912), France) and Axel Roebel (STMS (UMR 9912), France)
- 11:20 Thu-M-O-2-2 1438 Separation of Emotional and Reconstruction Embeddings on Ladder Network to Improve Speech Emotion Recognition Robustness in Noisy Conditions, Seong-Gyun Leem (University of Texas at Dallas, USA), Daniel Fulford (Boston University, USA), Jukka-Pekka Onnela (Harvard University, USA), David Gard (San Francisco State University, USA) and Carlos Busso (University of Texas at Dallas, USA)
- 11:40 Thu-M-O-2-3 1739 M³: MultiModal Masking Applied to Sentiment Analysis, Efthymios Georgiou (NTUA, Greece), Georgios Paraskevopoulos (NTUA, Greece) and Alexandros Potamianos (NTUA, Greece)
Thu-M-O-3 Thursday, September 2, 11:00-13:00 In-person Oral: Linguistic Components in end-to-end ASR
- 11:00 Thu-M-O-3-1 1035 The CSTR System for Multilingual and Code-Switching ASR Challenges for Low Resource Indian Languages, Ondřej Klejch (University of Edinburgh, UK), Electra Wallington (University of Edinburgh, UK) and Peter Bell (University of Edinburgh, UK)
- 11:20 Thu-M-O-3-2 1623 Acoustic Data-Driven Subword Modeling for End-to-End Speech Recognition, Wei Zhou (RWTH Aachen University, Germany), Mohammad Zeineldeen (RWTH Aachen University, Germany), Zuoyun Zheng (RWTH Aachen University, Germany), Ralf Schlüter (RWTH Aachen University, Germany) and Hermann Ney (RWTH Aachen University, Germany)
- 11:40 Thu-M-O-3-3 1671 Equivalence of Segmental and Neural Transducer Modeling: A Proof of Concept, Wei Zhou (RWTH Aachen University, Germany), Albert Zeyer (RWTH Aachen University, Germany), André Merboldt (RWTH Aachen University, Germany), Ralf Schlüter (RWTH Aachen University, Germany) and Hermann Ney (RWTH Aachen University, Germany)
- 12:00 Thu-M-O-3-4 1735 Modeling Dialectal Variation for Swiss German Automatic Speech Recognition, Abbas Khosravani (Idiap Research Institute, Switzerland), Philip N. Garner (Idiap Research Institute, Switzerland) and Alexandros Lazaridis (Swisscom, Switzerland)
- 12:20 Thu-M-O-3-5 1756 Out-of-Vocabulary Words Detection with Attention and CTC Alignments in an End-to-End ASR System, Ekaterina Egorova (Brno University of Technology, Czech Republic), Hari Krishna Vydana (Brno University of Technology, Czech Republic), Lukáš Burget (Brno University of Technology, Czech Republic) and Jan Černocký (Brno University of Technology, Czech Republic)
- 12:40 Thu-M-O-3-6 2127 Training Hybrid Models on Noisy Transliterated Transcripts for Code-Switched Speech Recognition, Matthew Wiesner (Johns Hopkins University, USA), Mousmita Sarma (GoVivace, USA), Ashish Arora (Johns Hopkins University, USA), Desh Raj (Johns Hopkins University, USA), Dongji Gao (Johns Hopkins University, USA), Ruizhe Huang (Johns Hopkins University, USA), Supreet Preet (GoVivace, USA), Moris Johnson (GoVivace, USA), Zikra Iqbal (GoVivace, USA), Nagendra Goel (GoVivace, USA), Jan Trmal (Johns Hopkins University, USA), Leibny Paola García Perera (Johns Hopkins University, USA) and Sanjeev Khudanpur (Johns Hopkins University, USA)
Thu-M-V-1 Thursday, September 2, 11:00-13:00 Virtual: Assessment of pathological speech and language II
- 11:00 Thu-M-V-1-1 1189 Speech Intelligibility of Dysarthric Speech: Human Scores and Acoustic-Phonetic Features, Wei Xue (Radboud Universiteit, The Netherlands), Roeland van Hout (Radboud Universiteit, The Netherlands), Fleur Boogmans (Radboud Universiteit, The Netherlands), Mario Ganzeboom (Radboud Universiteit, The Netherlands), Catia Cucchiarini (Radboud Universiteit, The Netherlands) and Helmer Strik (Radboud Universiteit, The Netherlands)
- 11:00 Thu-M-V-1-2 2111 Analyzing Short Term Dynamic Speech Features for Understanding Behavioral Traits of Children with Autism Spectrum Disorder, Young-Kyung Kim (University of Southern California, USA), Rimita Lahiri (University of Southern California, USA), Md. Nasir (Microsoft, USA), So Hyun Kim (Cornell University, USA), Somer Bishop (University of California at San Francisco, USA), Catherine Lord (University of California at Los Angeles, USA) and Shrikanth S. Narayanan (University of Southern California, USA)
- 11:00 Thu-M-V-1-3 1239 Vocalization Recognition of People with Profound Intellectual and Multiple Disabilities (PIMD) Using Machine Learning Algorithms, Waldemar Jęśko (PSNC, Poland)
- 11:00 Thu-M-V-1-4 1862 Phonetic Complexity, Speech Accuracy and Intelligibility Assessment of Italian Dysarthric Speech, Barbara Gili Fivela (Università del Salento, Italy), Vincenzo Sallustio (ASL Lecce, Italy), Silvia Pede (ASL Lecce, Italy) and Danilo Patrocinio (Università Cattolica del Sacro Cuore, Italy)
- 11:00 Thu-M-V-1-5 1305 Detection of Consonant Errors in Disordered Speech Based on Consonant-Vowel Segment Embedding, Si-Ioi Ng (CUHK, China), Cymie Wing-Yee Ng (CUHK, China), Jingyu Li (CUHK, China) and Tan Lee (CUHK, China)
- 11:00 Thu-M-V-1-6 69 Assessing Posterior-Based Mispronunciation Detection on Field-Collected Recordings from Child Speech Therapy Sessions, Adam Hair (Texas A&M University, USA), Guanlong Zhao (Texas A&M University, USA), Beena Ahmed (UNSW Sydney, Australia), Kirrie J. Ballard (University of Sydney, Australia) and Ricardo Gutierrez-Osuna (Texas A&M University, USA)
- 11:00 Thu-M-V-1-7 915 Identifying Cognitive Impairment Using Sentence Representation Vectors, Bahman Mirheidari (University of Sheffield, UK), Yilin Pan (University of Sheffield, UK), Daniel Blackburn (University of Sheffield, UK), Ronan O’Malley (University of Sheffield, UK) and Heidi Christensen (University of Sheffield, UK)
- 11:00 Thu-M-V-1-8 1297 Parental Spoken Scaffolding and Narrative Skills in Crowd-Sourced Storytelling Samples of Young Children, Zhengjun Yue (University of Sheffield, UK), Jon Barker (University of Sheffield, UK), Heidi Christensen (University of Sheffield, UK), Cristina McKean (Newcastle University, UK), Elaine Ashton (Newcastle University, UK), Yvonne Wren (North Bristol NHS Trust, UK), Swapnil Gadgil (Therapy Box, UK) and Rebecca Bright (Therapy Box, UK)
- 11:00 Thu-M-V-1-9 1320 Uncertainty-Aware COVID-19 Detection from Imbalanced Sound Data, Tong Xia (University of Cambridge, UK), Jing Han (University of Cambridge, UK), Lorena Qendro (University of Cambridge, UK), Ting Dang (University of Cambridge, UK) and Cecilia Mascolo (University of Cambridge, UK)
- 11:00 Thu-M-V-1-10 2139 Unsupervised Domain Adaptation for Dysarthric Speech Detection via Domain Adversarial Training and Mutual Information Minimization, Disong Wang (CUHK, China), Liqun Deng (Huawei Technologies, China), Yu Ting Yeung (Huawei Technologies, China), Xiao Chen (Huawei Technologies, China), Xunying Liu (CUHK, China) and Helen Meng (CUHK, China)
- 11:00 Thu-M-V-1-11 2008 Source and Vocal Tract Cues for Speech-Based Classification of Patients with Parkinson’s Disease and Healthy Subjects, Tanuka Bhattacharjee (Indian Institute of Science, India), Jhansi Mallela (Indian Institute of Science, India), Yamini Belur (NIMHANS, India), Nalini Atchayaram (NIMHANS, India), Ravi Yadav (NIMHANS, India), Pradeep Reddy (NIMHANS, India), Dipanjan Gope (Indian Institute of Science, India) and Prasanta Kumar Ghosh (Indian Institute of Science, India)
- 11:00 Thu-M-V-1-12 1810 CLAC: A Speech Corpus of Healthy English Speakers, R’mani Haulcy (MIT, USA) and James Glass (MIT, USA)
Thu-M-V-2 Thursday, September 2, 11:00-13:00 Virtual: Multimodal systems
- 11:00 Thu-M-V-2-1 49 Direct Multimodal Few-Shot Learning of Speech and Images, Leanne Nortje (Stellenbosch University, South Africa) and Herman Kamper (Stellenbosch University, South Africa)
- 11:00 Thu-M-V-2-2 96 Talk, Don’t Write: A Study of Direct Speech-Based Image Retrieval, Ramon Sanabria (University of Edinburgh, UK), Austin Waters (Google, USA) and Jason Baldridge (Google, USA)
- 11:00 Thu-M-V-2-3 287 A Fast Discrete Two-Step Learning Hashing for Scalable Cross-Modal Retrieval, Huan Zhao (Hunan University, China) and Kaili Ma (Hunan University, China)
- 11:00 Thu-M-V-2-4 432 Cross-Modal Knowledge Distillation Method for Automatic Cued Speech Recognition, Jianrong Wang (Tianjin University, China), Ziyue Tang (Tianjin University, China), Xuewei Li (Tianjin University, China), Mei Yu (Tianjin University, China), Qiang Fang (CASS, China) and Li Liu (CUHK, China)
- 11:00 Thu-M-V-2-5 435 Attention-Based Keyword Localisation in Speech Using Visual Grounding, Kayode Olaleye (Stellenbosch University, South Africa) and Herman Kamper (Stellenbosch University, South Africa)
- 11:00 Thu-M-V-2-6 496 Evaluation of Audio-Visual Alignments in Visually Grounded Speech Models, Khazar Khorrami (Tampere University, Finland) and Okko Räsänen (Tampere University, Finland)
- 11:00 Thu-M-V-2-7 723 Automatic Lip-Reading with Hierarchical Pyramidal Convolution and Self-Attention for Image Sequences with No Word Boundaries, Hang Chen (USTC, China), Jun Du (USTC, China), Yu Hu (USTC, China), Li-Rong Dai (USTC, China), Bao-Cai Yin (iFLYTEK, China) and Chin-Hui Lee (Georgia Tech, USA)
- 11:00 Thu-M-V-2-8 1352 Cascaded Multilingual Audio-Visual Learning from Videos, Andrew Rouditchenko (MIT, USA), Angie Boggust (MIT, USA), David Harwath (University of Texas at Austin, USA), Samuel Thomas (IBM, USA), Hilde Kuehne (IBM, USA), Brian Chen (Columbia University, USA), Rameswar Panda (IBM, USA), Rogerio Feris (IBM, USA), Brian Kingsbury (IBM, USA), Michael Picheny (NYU, USA) and James Glass (MIT, USA)
- 11:00 Thu-M-V-2-9 1360 LiRA: Learning Visual Speech Representations from Audio Through Self-Supervision, Pingchuan Ma (Imperial College London, UK), Rodrigo Mira (Imperial College London, UK), Stavros Petridis (Facebook, UK), Björn W. Schuller (Imperial College London, UK) and Maja Pantic (Imperial College London, UK)
- 11:00 Thu-M-V-2-10 1621 End-to-End Audio-Visual Speech Recognition for Overlapping Speech, Richard Rose (Google, USA), Olivier Siohan (Google, USA), Anshuman Tripathi (Google, USA) and Otavio Braga (Google, USA)
- 11:00 Thu-M-V-2-11 2128 Audio-Visual Multi-Talker Speech Recognition in a Cocktail Party, Yifei Wu (SJTU, China), Chenda Li (SJTU, China), Song Yang (TAL, China), Zhongqin Wu (TAL, China) and Yanmin Qian (SJTU, China)
Thu-M-V-3 Thursday, September 2, 11:00-13:00 Virtual: Source Separation I
- 11:00 Thu-M-V-3-1 142 Ultra Fast Speech Separation Model with Teacher Student Learning, Sanyuan Chen (Harbin Institute of Technology, China), Yu Wu (Microsoft, China), Zhuo Chen (Microsoft, USA), Jian Wu (Microsoft, China), Takuya Yoshioka (Microsoft, USA), Shujie Liu (Microsoft, China), Jinyu Li (Microsoft, USA) and Xiangzhan Yu (Harbin Institute of Technology, China)
- 11:00 Thu-M-V-3-2 164 Group Delay Based Re-Weighted Sparse Recovery Algorithms for Robust and High-Resolution Source Separation in DOA Framework, Murtiza Ali (IIT Jammu, India), Ashwani Koul (IIT Jammu, India) and Karan Nathwani (IIT Jammu, India)
- 11:00 Thu-M-V-3-3 338 Continuous Speech Separation Using Speaker Inventory for Long Recording, Cong Han (Columbia University, USA), Yi Luo (Columbia University, USA), Chenda Li (SJTU, China), Tianyan Zhou (Microsoft, USA), Keisuke Kinoshita (NTT, Japan), Shinji Watanabe (Johns Hopkins University, USA), Marc Delcroix (NTT, Japan), Hakan Erdogan (Google, USA), John R. Hershey (Google, USA), Nima Mesgarani (Columbia University, USA) and Zhuo Chen (Microsoft, USA)
- 11:00 Thu-M-V-3-4 433 Crossfire Conditional Generative Adversarial Networks for Singing Voice Extraction, Weitao Yuan (Tiangong University, China), Shengbei Wang (Tiangong University, China), Xiangrui Li (Tiangong University, China), Masashi Unoki (JAIST, Japan) and Wenwu Wang (University of Surrey, UK)
- 11:00 Thu-M-V-3-5 504 End-to-End Speech Separation Using Orthogonal Representation in Complex and Real Time-Frequency Domain, Kai Wang (Xinjiang University, China), Hao Huang (Xinjiang University, China), Ying Hu (Xinjiang University, China), Zhihua Huang (Xinjiang University, China) and Sheng Li (NICT, Japan)
- 11:00 Thu-M-V-3-6 523 Efficient and Stable Adversarial Learning Using Unpaired Data for Unsupervised Multichannel Speech Separation, Yu Nakagome (Waseda University, Japan), Masahito Togami (LINE, Japan), Tetsuji Ogawa (Waseda University, Japan) and Tetsunori Kobayashi (Waseda University, Japan)
- 11:00 Thu-M-V-3-7 763 Stabilizing Label Assignment for Speech Separation by Self-Supervised Pre-Training, Sung-Feng Huang (National Taiwan University, Taiwan), Shun-Po Chuang (National Taiwan University, Taiwan), Da-Rong Liu (National Taiwan University, Taiwan), Yi-Chen Chen (National Taiwan University, Taiwan), Gene-Ping Yang (University of Edinburgh, UK) and Hung-yi Lee (National Taiwan University, Taiwan)
- 11:00 Thu-M-V-3-8 858 Dual-Path Filter Network: Speaker-Aware Modeling for Speech Separation, Fan-Lin Wang (Academia Sinica, Taiwan), Yu-Huai Peng (Academia Sinica, Taiwan), Hung-Shin Lee (Academia Sinica, Taiwan) and Hsin-Min Wang (Academia Sinica, Taiwan)
- 11:00 Thu-M-V-3-9 921 Investigation of Practical Aspects of Single Channel Speech Separation for ASR, Jian Wu (Microsoft, China), Zhuo Chen (Microsoft, USA), Sanyuan Chen (Microsoft, China), Yu Wu (Microsoft, China), Takuya Yoshioka (Microsoft, USA), Naoyuki Kanda (Microsoft, USA), Shujie Liu (Microsoft, China) and Jinyu Li (Microsoft, USA)
- 11:00 Thu-M-V-3-10 1158 Implicit Filter-and-Sum Network for End-to-End Multi-Channel Speech Separation, Yi Luo (Columbia University, USA) and Nima Mesgarani (Columbia University, USA)
- 11:00 Thu-M-V-3-11 430 Generalized Spatio-Temporal RNN Beamformer for Target Speech Separation, Yong Xu (Tencent, USA), Zhuohuang Zhang (Indiana University, USA), Meng Yu (Tencent, USA), Shi-Xiong Zhang (Tencent, USA) and Dong Yu (Tencent, USA)
Thu-M-V-4 Thursday, September 2, 11:00-13:00 Virtual: Speaker Diarization I
- 11:00 Thu-M-V-4-1 1909 End-to-End Neural Diarization: From Transformer to Conformer, Yi Chieh Liu (Georgia Tech, USA), Eunjung Han (Amazon, USA), Chul Lee (Amazon, USA) and Andreas Stolcke (Amazon, USA)
- 11:00 Thu-M-V-4-2 149 Three-Class Overlapped Speech Detection Using a Convolutional Recurrent Neural Network, Jee-weon Jung (Naver, Korea), Hee-Soo Heo (Naver, Korea), Youngki Kwon (Naver, Korea), Joon Son Chung (Naver, Korea) and Bong-Jin Lee (Naver, Korea)
- 11:00 Thu-M-V-4-3 261 Online Speaker Diarization Equipped with Discriminative Modeling and Guided Inference, Xucheng Wan (Huawei Technologies, China), Kai Liu (Huawei Technologies, China) and Huan Zhou (Huawei Technologies, China)
- 11:00 Thu-M-V-4-4 384 Semi-Supervised Training with Pseudo-Labeling for End-To-End Neural Diarization, Yuki Takashima (Hitachi, Japan), Yusuke Fujita (Hitachi, Japan), Shota Horiguchi (Hitachi, Japan), Shinji Watanabe (Carnegie Mellon University, USA), Leibny Paola García Perera (Johns Hopkins University, USA) and Kenji Nagamatsu (Hitachi, Japan)
- 11:00 Thu-M-V-4-5 448 Adapting Speaker Embeddings for Speaker Diarisation, Youngki Kwon (Naver, Korea), Jee-weon Jung (Naver, Korea), Hee-Soo Heo (Naver, Korea), You Jin Kim (Naver, Korea), Bong-Jin Lee (Naver, Korea) and Joon Son Chung (Naver, Korea)
- 11:00 Thu-M-V-4-6 516 Scenario-Dependent Speaker Diarization for DIHARD-III Challenge, Yu-Xuan Wang (USTC, China), Jun Du (USTC, China), Maokui He (USTC, China), Shu-Tong Niu (USTC, China), Lei Sun (iFLYTEK, China) and Chin-Hui Lee (Georgia Tech, USA)
- 11:00 Thu-M-V-4-7 560 End-To-End Speaker Segmentation for Overlap-Aware Resegmentation, Hervé Bredin (IRIT (UMR 5505), France) and Antoine Laurent (LIUM (EA 4023), France)
- 11:00 Thu-M-V-4-8 708 Online Streaming End-to-End Neural Diarization Handling Overlapping Speech and Flexible Numbers of Speakers, Yawen Xue (Hitachi, Japan), Shota Horiguchi (Hitachi, Japan), Yusuke Fujita (Hitachi, Japan), Yuki Takashima (Hitachi, Japan), Shinji Watanabe (Carnegie Mellon University, USA), Leibny Paola García Perera (Johns Hopkins University, USA) and Kenji Nagamatsu (Hitachi, Japan)
- 11:00 Thu-M-V-4-9 87 A Thousand Words are Worth More Than One Recording: Word-Embedding Based Speaker Change Detection, Or Haim Anidjar (Ariel University, Israel), Itshak Lapidot (Afeka College, Israel), Chen Hajaj (Ariel University, Israel) and Amit Dvir (Ariel University, Israel)
Thu-M-V-5 Thursday, September 2, 11:00-13:00 Virtual: Speech Synthesis: Prosody Modeling I
- 11:00 Thu-M-V-5-1 252 Phrase Break Prediction with Bidirectional Encoder Representations in Japanese Text-to-Speech Synthesis, Kosuke Futamata (LINE, Japan), Byeongseon Park (LINE, Japan), Ryuichi Yamamoto (LINE, Japan) and Kentaro Tachibana (LINE, Japan)
- 11:00 Thu-M-V-5-2 562 Improving Multi-Speaker TTS Prosody Variance with a Residual Encoder and Normalizing Flows, Iván Vallés-Pérez (Amazon, UK), Julian Roth (Amazon, UK), Grzegorz Beringer (Amazon, Poland), Roberto Barra-Chicote (Amazon, UK) and Jasha Droppo (Amazon, USA)
- 11:00 Thu-M-V-5-3 802 Rich Prosody Diversity Modelling with Phone-Level Mixture Density Network, Chenpeng Du (SJTU, China) and Kai Yu (SJTU, China)
- 11:00 Thu-M-V-5-4 826 Phoneme Duration Modeling Using Speech Rhythm-Based Speaker Embeddings for Multi-Speaker Speech Synthesis, Kenichi Fujita (NTT, Japan), Atsushi Ando (NTT, Japan) and Yusuke Ijima (NTT, Japan)
- 11:00 Thu-M-V-5-5 883 Fine-Grained Prosody Modeling in Neural Speech Synthesis Using ToBI Representation, Yuxiang Zou (ByteDance, China), Shichao Liu (ByteDance, China), Xiang Yin (ByteDance, China), Haopeng Lin (ByteDance, China), Chunfeng Wang (ByteDance, China), Haoyu Zhang (ByteDance, China) and Zejun Ma (ByteDance, China)
- 11:00 Thu-M-V-5-6 1012 Intra-Sentential Speaking Rate Control in Neural Text-To-Speech for Automatic Dubbing, Mayank Sharma (Amazon, India), Yogesh Virkar (Amazon, USA), Marcello Federico (Amazon, USA), Roberto Barra-Chicote (Amazon, UK) and Robert Enyedi (Amazon, USA)
- 11:00 Thu-M-V-5-7 1049 Applying the Information Bottleneck Principle to Prosodic Representation Learning, Guangyan Zhang (CUHK, China), Ying Qin (Beijing Jiaotong University, China), Daxin Tan (CUHK, China) and Tan Lee (CUHK, China)
- 11:00 Thu-M-V-5-8 1123 A Prototypical Network Approach for Evaluating Generated Emotional Speech, Alice Baird (Universität Augsburg, Germany), Silvan Mertes (Universität Augsburg, Germany), Manuel Milling (Universität Augsburg, Germany), Lukas Stappen (Universität Augsburg, Germany), Thomas Wiest (Universität Augsburg, Germany), Elisabeth André (Universität Augsburg, Germany) and Björn W. Schuller (Universität Augsburg, Germany)
Thu-M-V-6 Thursday, September 2, 11:00-13:00 Virtual: Speech production II
- 11:00 Thu-M-V-6-1 231 A Simplified Model for the Vocal Tract of [s] with Inclined Incisors, Tsukasa Yoshinaga (Toyohashi Tech, Japan), Kohei Tada (Toyohashi Tech, Japan), Kazunori Nozaki (Osaka University Dental Hospital, Japan) and Akiyoshi Iida (Toyohashi Tech, Japan)
- 11:00 Thu-M-V-6-2 449 Vocal-Tract Models to Visualize the Airstream of Human Breath and Droplets While Producing Speech, Takayuki Arai (Sophia University, Japan)
- 11:00 Thu-M-V-6-3 906 Using Transposed Convolution for Articulatory-to-Acoustic Conversion from Real-Time MRI Data, Ryo Tanji (Tokyo University of Science, Japan), Hidefumi Ohmura (Tokyo University of Science, Japan) and Kouichi Katsurada (Tokyo University of Science, Japan)
- 11:00 Thu-M-V-6-4 929 Comparison Between Lumped-Mass Modeling and Flow Simulation of the Reed-Type Artificial Vocal Fold, Rafia Inaam (Toyohashi Tech, Japan), Tsukasa Yoshinaga (Toyohashi Tech, Japan), Takayuki Arai (Sophia University, Japan), Hiroshi Yokoyama (Toyohashi Tech, Japan) and Akiyoshi Iida (Toyohashi Tech, Japan)
- 11:00 Thu-M-V-6-5 1262 Inhalations in Speech: Acoustic and Physiological Characteristics, Raphael Werner (Universität des Saarlandes, Germany), Susanne Fuchs (ZAS, Germany), Jürgen Trouvain (Universität des Saarlandes, Germany) and Bernd Möbius (Universität des Saarlandes, Germany)
- 11:00 Thu-M-V-6-6 1422 Model-Based Exploration of Linking Between Vowel Articulatory Space and Acoustic Space, Anqi Xu (University College London, UK), Daniel van Niekerk (University College London, UK), Branislav Gerazov (UKiM, Macedonia), Paul Konstantin Krug (Technische Universität Dresden, Germany), Santitham Prom-on (KMUTT, Thailand), Peter Birkholz (Technische Universität Dresden, Germany) and Yi Xu (University College London, UK)
- 11:00 Thu-M-V-6-7 1496 Take a Breath: Respiratory Sounds Improve Recollection in Synthetic Speech, Mikey Elmers (Universität des Saarlandes, Germany), Raphael Werner (Universität des Saarlandes, Germany), Beeke Muhlack (Universität des Saarlandes, Germany), Bernd Möbius (Universität des Saarlandes, Germany) and Jürgen Trouvain (Universität des Saarlandes, Germany)
- 11:00 Thu-M-V-6-8 1746 Modeling Sensorimotor Adaptation in Speech Through Alterations to Forward and Inverse Models, Taijing Chen (UW–Madison, USA), Adam Lammert (Worcester Polytechnic Institute, USA) and Benjamin Parrell (UW–Madison, USA)
- 11:00 Thu-M-V-6-9 2073 Mixture of Orthogonal Sequences Made from Extended Time-Stretched Pulses Enables Measurement of Involuntary Voice Fundamental Frequency Response to Pitch Perturbation, Hideki Kawahara (Wakayama University, Japan), Toshie Matsui (Toyohashi Tech, Japan), Kohei Yatabe (Waseda University, Japan), Ken-Ichi Sakakibara (HSUH, Japan), Minoru Tsuzaki (KCUA, Japan), Masanori Morise (Meiji University, Japan) and Toshio Irino (Wakayama University, Japan)
Thu-M-V-7 Thursday, September 2, 11:00-13:00 Virtual: Spoken Dialogue Systems II
- 11:00 Thu-M-V-7-1 110 Contextualized Attention-Based Knowledge Transfer for Spoken Conversational Question Answering, Chenyu You (Yale University, USA), Nuo Chen (Peking University, China) and Yuexian Zou (Peking University, China)
- 11:00 Thu-M-V-7-2 229 Injecting Descriptive Meta-Information into Pre-Trained Language Models with Hypernetworks, Wenying Duan (Nanchang University, China), Xiaoxi He (ETH Zürich, Switzerland), Zimu Zhou (Singapore Management University, Singapore), Hong Rao (Nanchang University, China) and Lothar Thiele (ETH Zürich, Switzerland)
- 11:00 Thu-M-V-7-3 534 Causal Confusion Reduction for Robust Multi-Domain Dialogue Policy, Mahdin Rohmatillah (NYCU, Taiwan) and Jen-Tzung Chien (NYCU, Taiwan)
- 11:00 Thu-M-V-7-4 874 Timing Generating Networks: Neural Network Based Precise Turn-Taking Timing Prediction in Multiparty Conversation, Shinya Fujie (Chiba Institute of Technology, Japan), Hayato Katayama (Waseda University, Japan), Jin Sakuma (Waseda University, Japan) and Tetsunori Kobayashi (Waseda University, Japan)
- 11:00 Thu-M-V-7-5 994 Human-to-Human Conversation Dataset for Learning Fine-Grained Turn-Taking Action, Kehan Chen (Alibaba, China), Zezhong Li (Alibaba, China), Suyang Dai (Alibaba, China), Wei Zhou (Alibaba, China) and Haiqing Chen (Alibaba, China)
- 11:00 Thu-M-V-7-6 1582 PhonemeBERT: Joint Language Modelling of Phoneme Sequence and ASR Transcript, Mukuntha Narayanan Sundararaman (Observe.AI, India), Ayush Kumar (Observe.AI, India) and Jithendra Vepa (Observe.AI, India)
- 11:00 Thu-M-V-7-7 1689 Joint Retrieval-Extraction Training for Evidence-Aware Dialog Response Selection, Hongyin Luo (MIT, USA), James Glass (MIT, USA), Garima Lalwani (Amazon, USA), Yi Zhang (Amazon, USA) and Shang-Wen Li (Amazon, USA)
- 11:00 Thu-M-V-7-8 1849 Adapting Long Context NLM for ASR Rescoring in Conversational Agents, Ashish Shenoy (Amazon, USA), Sravan Bodapati (Amazon, USA), Monica Sunkara (Amazon, USA), Srikanth Ronanki (Amazon, USA) and Katrin Kirchhoff (Amazon, USA)
Thu-M-SS-1 Thursday, September 2, 11:00-13:00 Special-Virtual: Oriental Language Recognition
- 11:00 Thu-M-SS-1-1 2171 Oriental Language Recognition (OLR) 2020: Summary and Analysis, Jing Li (Xiamen University, China), Binling Wang (Xiamen University, China), Yiming Zhi (Xiamen University, China), Zheng Li (Xiamen University, China), Lin Li (Xiamen University, China), Qingyang Hong (Xiamen University, China) and Dong Wang (Tsinghua University, China)
- 11:20 Thu-M-SS-1-2 276 Language Recognition on Unknown Conditions: The LORIA-Inria-MULTISPEECH System for AP20-OLR Challenge, Raphaël Duroselle (Loria (UMR 7503), France), Md. Sahidullah (Loria (UMR 7503), France), Denis Jouvet (Loria (UMR 7503), France) and Irina Illina (Loria (UMR 7503), France)
- 11:40 Thu-M-SS-1-3 56 Dynamic Multi-Scale Convolution for Dialect Identification, Tianlong Kong (Tsinghua University, China), Shouyi Yin (Tsinghua University, China), Dawei Zhang (Kwai, China), Wang Geng (Kwai, China), Xin Wang (Kwai, China), Dandan Song (Tsinghua University, China), Jinwen Huang (Kwai, China), Huiyu Shi (Tsinghua University, China) and Xiaorui Wang (Kwai, China)
- 12:00 Thu-M-SS-1-4 374 An End-to-End Dialect Identification System with Transfer Learning from a Multilingual Automatic Speech Recognition Model, Ding Wang (HiThink RoyalFlush, China), Shuaishuai Ye (HiThink RoyalFlush, China), Xinhui Hu (HiThink RoyalFlush, China), Sheng Li (NICT, Japan) and Xinkang Xu (HiThink RoyalFlush, China)
- 12:20 Thu-M-SS-1-5 807 Language Recognition Based on Unsupervised Pretrained Models, Haibin Yu (Tsinghua University, China), Jing Zhao (Tsinghua University, China), Song Yang (TAL, China), Zhongqin Wu (TAL, China), Yuting Nie (Tsinghua University, China) and Wei-Qiang Zhang (Tsinghua University, China)
- 12:40 Thu-M-SS-1-6 1167 Additive Phoneme-Aware Margin Softmax Loss for Language Recognition, Zheng Li (Xiamen University, China), Yan Liu (Xiamen University, China), Lin Li (Xiamen University, China) and Qingyang Hong (Xiamen University, China)
Thu-M-SS-2 Thursday, September 2, 11:00-13:00 Special-Hybrid: Automatic Speech Recognition in Air Traffic Management
- 11:00 Introduction
- 11:10 Thu-M-SS-2-1 333 Towards an Accent-Robust Approach for ATC Communications Transcription, Nataly Jahchan (APSYS, France), Florentin Barbier (Airbus, France), Ariyanidevi Dharma Gita (APSYS, France), Khaled Khelif (Airbus, France) and Estelle Delpech (Airbus, France)
- 11:25 Thu-M-SS-2-2 1033 Detecting English Speech in the Air Traffic Control Voice Communication, Igor Szöke (Brno University of Technology, Czech Republic), Santosh Kesiraju (Brno University of Technology, Czech Republic), Ondřej Novotný (Brno University of Technology, Czech Republic), Martin Kocour (Brno University of Technology, Czech Republic), Karel Veselý (Brno University of Technology, Czech Republic) and Jan Černocký (Brno University of Technology, Czech Republic)
- 11:40 Thu-M-SS-2-3 935 Robust Command Recognition for Lithuanian Air Traffic Control Tower Utterances, Oliver Ohneiser (DLR, Germany), Seyyed Saeed Sarfjoo (Idiap Research Institute, Switzerland), Hartmut Helmke (DLR, Germany), Shruthi Shetty (DLR, Germany), Petr Motlicek (Idiap Research Institute, Switzerland), Matthias Kleinert (DLR, Germany), Heiko Ehr (DLR, Germany) and Šarūnas Murauskas (Oro navigacija, Lithuania)
- 11:55 Thu-M-SS-2-4 1373 Contextual Semi-Supervised Learning: An Approach to Leverage Air-Surveillance and Untranscribed ATC Data in ASR Systems, Juan Zuluaga-Gomez (Idiap Research Institute, Switzerland), Iuliia Nigmatulina (Idiap Research Institute, Switzerland), Amrutha Prasad (Idiap Research Institute, Switzerland), Petr Motlicek (Idiap Research Institute, Switzerland), Karel Veselý (Brno University of Technology, Czech Republic), Martin Kocour (Brno University of Technology, Czech Republic) and Igor Szöke (ReplayWell, Czech Republic)
- 12:10 Thu-M-SS-2-5 1619 Boosting of Contextual Information in ASR for Air-Traffic Call-Sign Recognition, Martin Kocour (Brno University of Technology, Czech Republic), Karel Veselý (Brno University of Technology, Czech Republic), Alexander Blatt (Universität des Saarlandes, Germany), Juan Zuluaga Gomez (Idiap Research Institute, Switzerland), Igor Szöke (Brno University of Technology, Czech Republic), Jan Černocký (Brno University of Technology, Czech Republic), Dietrich Klakow (Universität des Saarlandes, Germany) and Petr Motlicek (Idiap Research Institute, Switzerland)
- 12:25 Thu-M-SS-2-6 1650 Modeling the Effect of Military Oxygen Masks on Speech Characteristics, Benjamin Elie (LISN (UMR 9015), France), Jodie Gauvain (Vocapia Research, France), Jean-Luc Gauvain (LISN (UMR 9015), France) and Lori Lamel (LISN (UMR 9015), France)
- 12:40 Panel discussion
Thu-M-S&T-1 Thursday, September 2, 11:00-13:00 Show and Tell: Show and Tell 3
- 11:00 Thu-M-S&T-1-1 ST15 MoM: Minutes of Meeting Bot, Benjamin Milde (Universität Hamburg, Germany), Tim Fischer (Universität Hamburg, Germany), Steffen Remus (Universität Hamburg, Germany) and Chris Biemann (Universität Hamburg, Germany)
- 11:00 Thu-M-S&T-1-2 ST16 Articulatory Data Recorder: A Framework for Real-Time Articulatory Data Recording, Alexander Wilbrandt (Technische Universität Dresden, Germany), Simon Stone (Technische Universität Dresden, Germany) and Peter Birkholz (Technische Universität Dresden, Germany)
- 11:00 Thu-M-S&T-1-3 ST17 The INGENIOUS Multilingual Operations App, Joan Codina-Filbà (Universitat Pompeu Fabra, Spain), Guillermo Cámbara (Universitat Pompeu Fabra, Spain), Alex Peiró-Lilja (Universitat Pompeu Fabra, Spain), Jens Grivolla (Universitat Pompeu Fabra, Spain), Roberto Carlini (Universitat Pompeu Fabra, Spain) and Mireia Farrús (Universitat de Barcelona, Spain)
- 11:00 Thu-M-S&T-1-4 ST18 Digital Einstein Experience: Fast Text-to-Speech for Conversational AI, Joanna Rownicka (Aflorithmic Labs, UK), Kilian Sprenkamp (Aflorithmic Labs, UK), Antonio Tripiana (Aflorithmic Labs, UK), Volodymyr Gromoglasov (Aflorithmic Labs, UK) and Timo P. Kunz (Aflorithmic Labs, UK)
- 11:00 Thu-M-S&T-1-5 ST19 Live Subtitling for BigBlueButton with Open-Source Software, Robert Geislinger (HITeC, Germany), Benjamin Milde (HITeC, Germany), Timo Baumann (Universität Hamburg, Germany) and Chris Biemann (Universität Hamburg, Germany)
- 11:00 Thu-M-S&T-1-6 ST20 Expressive Latvian Speech Synthesis for Dialog Systems, Dāvis Nicmanis (Tilde, Latvia) and Askars Salimbajevs (Tilde, Latvia)
- 11:00 Thu-M-S&T-1-7 ST22 ViSTAFAE: A Visual Speech-Training Aid with Feedback of Articulatory Efforts, Pramod H. Kachare (IIT Bombay, India), Prem C. Pandey (IIT Bombay, India), Vishal Mane (Digital India, India), Hirak Dasgupta (IIT Bombay, India), K.S. Nataraj (IIT Bombay, India), Akshada Rathod (Digital India, India) and Sheetal K. Pathak (Digital India, India)
Thu-A-O-1 Thursday, September 2, 16:00-18:00 In-person Oral: Speech production I
- 16:00 Thu-A-O-1-1 184 Towards the Prediction of the Vocal Tract Shape from the Sequence of Phonemes to be Articulated, Vinicius Ribeiro (Loria (UMR 7503), France), Karyna Isaieva (IADI (Inserm U1254), France), Justine Leclere (IADI (Inserm U1254), France), Pierre-André Vuissoz (IADI (Inserm U1254), France) and Yves Laprie (Loria (UMR 7503), France)
- 16:20 Thu-A-O-1-2 975 Comparison of the Finite Element Method, the Multimodal Method and the Transmission-Line Model for the Computation of Vocal Tract Transfer Functions, Rémi Blandin (Technische Universität Dresden, Germany), Marc Arnela (Universitat Ramon Llull, Spain), Simon Félix (LAUM (UMR 6613), France), Jean-Baptiste Doc (LMSSC (EA 3196), France) and Peter Birkholz (Technische Universität Dresden, Germany)
- 16:40 Thu-A-O-1-3 1539 Effects of Time Pressure and Spontaneity on Phonotactic Innovations in German Dialogues, Petra Wagner (Universität Bielefeld, Germany), Sina Zarrieß (Universität Bielefeld, Germany) and Joana Cholin (Universität Bielefeld, Germany)
- 17:00 Thu-A-O-1-4 1732 Importance of Parasagittal Sensor Information in Tongue Motion Capture Through a Diphonic Analysis, Salvador Medina (Carnegie Mellon University, USA), Sarah Taylor (University of East Anglia, UK), Mark Tiede (Haskins Laboratories, USA), Alexander Hauptmann (Carnegie Mellon University, USA) and Iain Matthews (Epic Games, USA)
- 17:20 Thu-A-O-1-5 1604 Learning Robust Speech Representation with an Articulatory-Regularized Variational Autoencoder, Marc-Antoine Georges (GIPSA-lab (UMR 5216), France), Laurent Girin (GIPSA-lab (UMR 5216), France), Jean-Luc Schwartz (GIPSA-lab (UMR 5216), France) and Thomas Hueber (GIPSA-lab (UMR 5216), France)
- 17:40 Thu-A-O-1-6 1881 Changes in Glottal Source Parameter Values with Light to Moderate Physical Load, Heather Weston (ZAS, Germany), Laura L. Koenig (Adelphi University, USA) and Susanne Fuchs (ZAS, Germany)
Thu-A-O-2 Thursday, September 2, 16:00-18:00 In-person Oral: Speech enhancement and coding
- 16:00 Thu-A-O-2-1 867 End-to-End Optimized Multi-Stage Vector Quantization of Spectral Envelopes for Speech and Audio Coding, Mohammad Hassan Vali (Aalto University, Finland) and Tom Bäckström (Aalto University, Finland)
- 16:20 Thu-A-O-2-2 1184 Fusion-Net: Time-Frequency Information Fusion Y-Network for Speech Enhancement, Santhan Kumar Reddy Nareddula (IIT Tirupati, India), Subrahmanyam Gorthi (IIT Tirupati, India) and Rama Krishna Sai S. Gorthi (IIT Tirupati, India)
- 16:40 Thu-A-O-2-3 1878 N-MTTL SI Model: Non-Intrusive Multi-Task Transfer Learning-Based Speech Intelligibility Prediction Model with Scenery Classification, Ľuboš Marcinek (University of Manchester, UK), Michael Stone (University of Manchester, UK), Rebecca Millman (University of Manchester, UK) and Patrick Gaydecki (University of Manchester, UK)
Thu-A-V-1 Thursday, September 2, 16:00-18:00 Virtual: Emotion and Sentiment Analysis II
- 16:00 Thu-A-V-1-1 1840 Temporal Context in Speech Emotion Recognition, Yangyang Xia (Carnegie Mellon University, USA), Li-Wei Chen (Carnegie Mellon University, USA), Alexander Rudnicky (Carnegie Mellon University, USA) and Richard M. Stern (Carnegie Mellon University, USA)
- 16:00 Thu-A-V-1-2 158 Learning Fine-Grained Cross Modality Excitement for Speech Emotion Recognition, Hang Li (TAL, China), Wenbiao Ding (TAL, China), Zhongqin Wu (TAL, China) and Zitao Liu (TAL, China)
- 16:00 Thu-A-V-1-3 303 Automatic Analysis of the Emotional Content of Speech in Daylong Child-Centered Recordings from a Neonatal Intensive Care Unit, Einari Vaaras (Tampere University, Finland), Sari Ahlqvist-Björkroth (University of Turku, Finland), Konstantinos Drossos (Tampere University, Finland) and Okko Räsänen (Tampere University, Finland)
- 16:00 Thu-A-V-1-4 487 Multimodal Sentiment Analysis with Temporal Modality Attention, Fan Qian (Harbin Institute of Technology, China) and Jiqing Han (Harbin Institute of Technology, China)
- 16:00 Thu-A-V-1-5 610 Stochastic Process Regression for Cross-Cultural Speech Emotion Recognition, Mani Kumar T. (University of Nottingham, UK), Enrique Sanchez (University of Nottingham, UK), Georgios Tzimiropoulos (Queen Mary University of London, UK), Timo Giesbrecht (Unilever, UK) and Michel Valstar (University of Nottingham, UK)
- 16:00 Thu-A-V-1-6 666 Acted vs. Improvised: Domain Adaptation for Elicitation Approaches in Audio-Visual Emotion Recognition, Haoqi Li (Amazon, USA), Yelin Kim (Amazon, USA), Cheng-Hao Kuo (Amazon, USA) and Shrikanth S. Narayanan (University of Southern California, USA)
- 16:00 Thu-A-V-1-7 703 Emotion Recognition from Speech Using wav2vec 2.0 Embeddings, Leonardo Pepino (UBA-CONICET ICC, Argentina), Pablo Riera (UBA-CONICET ICC, Argentina) and Luciana Ferrer (UBA-CONICET ICC, Argentina)
- 16:00 Thu-A-V-1-8 1154 Graph Isomorphism Network for Speech Emotion Recognition, Jiawang Liu (SCUT, China) and Haoxiang Wang (SCUT, China)
- 16:00 Thu-A-V-1-9 2168 Applying TDNN Architectures for Analyzing Duration Dependencies on Speech Emotion Recognition, Pooja Kumawat (IIT Kharagpur, India) and Aurobinda Routray (IIT Kharagpur, India)
- 16:00 Thu-A-V-1-10 2217 Acoustic Features and Neural Representations for Categorical Emotion Recognition from Speech, Aaron Keesing (University of Auckland, New Zealand), Yun Sing Koh (University of Auckland, New Zealand) and Michael Witbrock (University of Auckland, New Zealand)
- 16:00 Thu-A-V-1-11 1723 Leveraging Pre-Trained Language Model for Speech Sentiment Analysis, Suwon Shon (ASAPP, USA), Pablo Brusco (ASAPP, USA), Jing Pan (ASAPP, USA), Kyu J. Han (ASAPP, USA) and Shinji Watanabe (Carnegie Mellon University, USA)
Thu-A-V-2 Thursday, September 2, 16:00-18:00 Virtual: Multi- and cross-lingual ASR, other topics in ASR
- 16:00 Thu-A-V-2-1 57 Cross-Domain Speech Recognition with Unsupervised Character-Level Distribution Matching, Wenxin Hou (Tokyo Tech, Japan), Jindong Wang (Microsoft, China), Xu Tan (Microsoft, China), Tao Qin (Microsoft, China) and Takahiro Shinozaki (Tokyo Tech, Japan)
- 16:00 Thu-A-V-2-2 102 Large-Scale Pre-Training of End-to-End Multi-Talker ASR for Meeting Transcription with Single Distant Microphone, Naoyuki Kanda (Microsoft, USA), Guoli Ye (Microsoft, USA), Yu Wu (Microsoft, China), Yashesh Gaur (Microsoft, USA), Xiaofei Wang (Microsoft, USA), Zhong Meng (Microsoft, USA), Zhuo Chen (Microsoft, USA) and Takuya Yoshioka (Microsoft, USA)
- 16:00 Thu-A-V-2-3 161 On Minimum Word Error Rate Training of the Hybrid Autoregressive Transducer, Liang Lu (Microsoft, USA), Zhong Meng (Microsoft, USA), Naoyuki Kanda (Microsoft, USA), Jinyu Li (Microsoft, USA) and Yifan Gong (Microsoft, USA)
- 16:00 Thu-A-V-2-4 322 Reducing Streaming ASR Model Delay with Self Alignment, Jaeyoung Kim (Google, USA), Han Lu (Google, USA), Anshuman Tripathi (Google, USA), Qian Zhang (Google, USA) and Hasim Sak (Google, USA)
- 16:00 Thu-A-V-2-5 644 Reduce and Reconstruct: ASR for Low-Resource Phonetic Languages, Anuj Diwan (IIT Bombay, India) and Preethi Jyothi (IIT Bombay, India)
- 16:00 Thu-A-V-2-6 796 Knowledge Distillation Based Training of Universal ASR Source Models for Cross-Lingual Transfer, Takashi Fukuda (IBM, Japan) and Samuel Thomas (IBM, USA)
- 16:00 Thu-A-V-2-7 836 Listen with Intent: Improving Speech Recognition with Audio-to-Intent Front-End, Swayambhu Nath Ray (Amazon, India), Minhua Wu (Amazon, USA), Anirudh Raju (Amazon, USA), Pegah Ghahremani (Amazon, USA), Raghavendra Bilgi (Amazon, India), Milind Rao (Amazon, USA), Harish Arsikere (Amazon, India), Ariya Rastrow (Amazon, USA), Andreas Stolcke (Amazon, USA) and Jasha Droppo (Amazon, USA)
- 16:00 Thu-A-V-2-8 1668 Exploring Targeted Universal Adversarial Perturbations to End-to-End ASR Models, Zhiyun Lu (Google, USA), Wei Han (Google, USA), Yu Zhang (Google, USA) and Liangliang Cao (Google, USA)
- 16:00 Thu-A-V-2-9 1915 Earnings-21: A Practical Benchmark for ASR in the Wild, Miguel Del Rio (Rev.com, USA), Natalie Delworth (Rev.com, USA), Ryan Westerman (Rev.com, USA), Michelle Huang (Rev.com, USA), Nishchal Bhandari (Rev.com, USA), Joseph Palakapilly (Rev.com, USA), Quinten McNamara (Rev.com, USA), Joshua Dong (Rev.com, USA), Piotr Żelasko (Johns Hopkins University, USA) and Miguel Jetté (Rev.com, USA)
- 16:00 Thu-A-V-2-10 1949 Improving Multilingual Transformer Transducer Models by Reducing Language Confusions, Eric Sun (Microsoft, USA), Jinyu Li (Microsoft, USA), Zhong Meng (Microsoft, USA), Yu Wu (Microsoft, China), Jian Xue (Microsoft, USA), Shujie Liu (Microsoft, China) and Yifan Gong (Microsoft, USA)
- 16:00 Thu-A-V-2-11 2231 Arabic Code-Switching Speech Recognition Using Monolingual Data, Ahmed Ali (HBKU, Qatar), Shammur Absar Chowdhury (HBKU, Qatar), Amir Hussein (HBKU, Qatar) and Yasser Hifny (Helwan University, Egypt)
Thu-A-V-3 Thursday, September 2, 16:00-18:00 Virtual: Source Separation II
- 16:00 Thu-A-V-3-1 662 Online Blind Audio Source Separation Using Recursive Expectation-Maximization, Aviad Eisenberg (Bar-Ilan University, Israel), Boaz Schwartz (Bar-Ilan University, Israel) and Sharon Gannot (Bar-Ilan University, Israel)
- 16:00 Thu-A-V-3-2 1161 Empirical Analysis of Generalized Iterative Speech Separation Networks, Yi Luo (Columbia University, USA), Cong Han (Columbia University, USA) and Nima Mesgarani (Columbia University, USA)
- 16:00 Thu-A-V-3-3 1177 Graph-PIT: Generalized Permutation Invariant Training for Continuous Separation of Arbitrary Numbers of Speakers, Thilo von Neumann (Universität Paderborn, Germany), Keisuke Kinoshita (NTT, Japan), Christoph Boeddeker (Universität Paderborn, Germany), Marc Delcroix (NTT, Japan) and Reinhold Haeb-Umbach (Universität Paderborn, Germany)
- 16:00 Thu-A-V-3-4 1243 Teacher-Student MixIT for Unsupervised and Semi-Supervised Speech Separation, Jisi Zhang (University of Sheffield, UK), Cătălin Zorilă (Toshiba, UK), Rama Doddipatla (Toshiba, UK) and Jon Barker (University of Sheffield, UK)
- 16:00 Thu-A-V-3-5 1369 Few-Shot Learning of New Sound Classes for Target Sound Extraction, Marc Delcroix (NTT, Japan), Jorge Bennasar Vázquez (NTT, Japan), Tsubasa Ochiai (NTT, Japan), Keisuke Kinoshita (NTT, Japan) and Shoko Araki (NTT, Japan)
- 16:00 Thu-A-V-3-6 1372 Binaural Speech Separation of Moving Speakers With Preserved Spatial Cues, Cong Han (Columbia University, USA), Yi Luo (Columbia University, USA) and Nima Mesgarani (Columbia University, USA)
- 16:00 Thu-A-V-3-7 1378 AvaTr: One-Shot Speaker Extraction with Transformers, Shell Xu Hu (Upload AI, USA), Md. Rifat Arefin (Upload AI, USA), Viet-Nhat Nguyen (Upload AI, USA), Alish Dipani (Upload AI, USA), Xaq Pitkow (Upload AI, USA) and Andreas Savas Tolias (Upload AI, USA)
- 16:00 Thu-A-V-3-8 1531 Vocal Harmony Separation Using Time-Domain Neural Networks, Saurjya Sarkar (Queen Mary University of London, UK), Emmanouil Benetos (Queen Mary University of London, UK) and Mark Sandler (Queen Mary University of London, UK)
- 16:00 Thu-A-V-3-9 1924 Speaker Verification-Based Evaluation of Single-Channel Speech Separation, Matthew Maciejewski (Johns Hopkins University, USA), Shinji Watanabe (Johns Hopkins University, USA) and Sanjeev Khudanpur (Johns Hopkins University, USA)
- 16:00 Thu-A-V-3-10 2246 Improved Speech Separation with Time-and-Frequency Cross-Domain Feature Selection, Tian Lan (UESTC, China), Yuxin Qian (UESTC, China), Yilan Lyu (UESTC, China), Refuoe Mokhosi (UESTC, China), Wenxin Tai (UESTC, China) and Qiao Liu (UESTC, China)
- 16:00 Thu-A-V-3-11 2250 Robust Speaker Extraction Network Based on Iterative Refined Adaptation, Chengyun Deng (DiDi Chuxing, China), Shiqian Ma (DiDi Chuxing, China), Yongtao Sha (DiDi Chuxing, China), Yi Zhang (DiDi Chuxing, China), Hui Zhang (Baidu, China), Hui Song (DiDi Chuxing, China) and Fei Wang (DiDi Chuxing, China)
- 16:00 Thu-A-V-3-12 2260 Neural Speaker Extraction with Speaker-Speech Cross-Attention Network, Wupeng Wang (NUS, Singapore), Chenglin Xu (NUS, Singapore), Meng Ge (NUS, Singapore) and Haizhou Li (NUS, Singapore)
- 16:00 Thu-A-V-3-13 1560 Deep Audio-Visual Speech Separation Based on Facial Motion, Rémi Rigal (Orange Labs, France), Jacques Chodorowski (Orange Labs, France) and Benoît Zerr (Lab-STICC (UMR 6285), France)
Thu-A-V-4 Thursday, September 2, 16:00-18:00 Virtual: Speaker Diarization II
- 16:00 Thu-A-V-4-1 728 LEAP Submission for the Third DIHARD Diarization Challenge, Prachi Singh (Indian Institute of Science, India), Rajat Varma (Indian Institute of Science, India), Venkat Krishnamohan (Indian Institute of Science, India), Srikanth Raj Chetupalli (Indian Institute of Science, India) and Sriram Ganapathy (Indian Institute of Science, India)
- 16:00 Thu-A-V-4-2 747 Investigation of Spatial-Acoustic Features for Overlapping Speech Detection in Multiparty Meetings, Shiliang Zhang (Alibaba, China), Siqi Zheng (Alibaba, China), Weilong Huang (Alibaba, China), Ming Lei (Alibaba, China), Hongbin Suo (Alibaba, China), Jinwei Feng (Alibaba, USA) and Zhijie Yan (Alibaba, China)
- 16:00 Thu-A-V-4-3 750 Target-Speaker Voice Activity Detection with Improved i-Vector Estimation for Unknown Number of Speaker, Maokui He (USTC, China), Desh Raj (Johns Hopkins University, USA), Zili Huang (Johns Hopkins University, USA), Jun Du (USTC, China), Zhuo Chen (Microsoft, USA) and Shinji Watanabe (Johns Hopkins University, USA)
- 16:00 Thu-A-V-4-4 941 ECAPA-TDNN Embeddings for Speaker Diarization, Nauman Dawalatabad (IIT Madras, India), Mirco Ravanelli (Mila, Canada), François Grondin (Université de Sherbrooke, Canada), Jenthe Thienpondt (Ghent University, Belgium), Brecht Desplanques (Ghent University, Belgium) and Hwidong Na (Samsung, Korea)
- 16:00 Thu-A-V-4-5 1004 Advances in Integration of End-to-End Neural and Clustering-Based Diarization for Real Conversational Speech, Keisuke Kinoshita (NTT, Japan), Marc Delcroix (NTT, Japan) and Naohiro Tawara (NTT, Japan)
- 16:00 Thu-A-V-4-6 1208 The Third DIHARD Diarization Challenge, Neville Ryant (University of Pennsylvania, USA), Prachi Singh (Indian Institute of Science, India), Venkat Krishnamohan (Indian Institute of Science, India), Rajat Varma (Indian Institute of Science, India), Kenneth Church (Baidu, USA), Christopher Cieri (University of Pennsylvania, USA), Jun Du (USTC, China), Sriram Ganapathy (Indian Institute of Science, India) and Mark Liberman (University of Pennsylvania, USA)
- 16:00 Thu-A-V-4-7 1377 Robust End-to-End Speaker Diarization with Conformer and Additive Margin Penalty, Tsun-Yat Leung (Fano Labs, China) and Lahiru Samarakoon (Fano Labs, China)
- 16:00 Thu-A-V-4-8 1588 Anonymous Speaker Clusters: Making Distinctions Between Anonymised Speech Recordings with Clustering Interface, Benjamin O’Brien (LPL (UMR 7309), France), Natalia Tomashenko (LIA (EA 4128), France), Anaïs Chanclu (LIA (EA 4128), France) and Jean-François Bonastre (LIA (EA 4128), France)
- 16:00 Thu-A-V-4-9 1807 Speaker Diarization Using Two-Pass Leave-One-Out Gaussian PLDA Clustering of DNN Embeddings, Kiran Karra (Johns Hopkins University, USA) and Alan McCree (Johns Hopkins University, USA)
Thu-A-V-5 Thursday, September 2, 16:00-18:00 Virtual: Speech Synthesis: Toward End-to-End Synthesis I
- 16:00 Thu-A-V-5-1 2039 Federated Learning with Dynamic Transformer for Text to Speech, Zhenhou Hong (Ping An Technology, China), Jianzong Wang (Ping An Technology, China), Xiaoyang Qu (Ping An Technology, China), Jie Liu (Ping An Technology, China), Chendong Zhao (Ping An Technology, China) and Jing Xiao (Ping An Technology, China)
- 16:00 Thu-A-V-5-2 188 LiteTTS: A Lightweight Mel-Spectrogram-Free Text-to-Wave Synthesizer Based on Generative Adversarial Networks, Huu-Kim Nguyen (Yonsei University, Korea), Kihyuk Jeong (Yonsei University, Korea), Seyun Um (Yonsei University, Korea), Min-Jae Hwang (Search Solutions, Korea), Eunwoo Song (Naver, Korea) and Hong-Goo Kang (Yonsei University, Korea)
- 16:00 Thu-A-V-5-3 189 Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration, Chuanxin Tang (Microsoft, China), Chong Luo (Microsoft, China), Zhiyuan Zhao (Microsoft, China), Dacheng Yin (USTC, China), Yucheng Zhao (USTC, China) and Wenjun Zeng (Microsoft, China)
- 16:00 Thu-A-V-5-4 469 Diff-TTS: A Denoising Diffusion Model for Text-to-Speech, Myeonghun Jeong (Seoul National University, Korea), Hyeongju Kim (Neosapience, Korea), Sung Jun Cheon (Seoul National University, Korea), Byoung Jin Choi (Seoul National University, Korea) and Nam Soo Kim (Seoul National University, Korea)
- 16:00 Thu-A-V-5-5 471 Hierarchical Context-Aware Transformers for Non-Autoregressive Text to Speech, Jae-Sung Bae (NCSOFT, Korea), Taejun Bak (NCSOFT, Korea), Young-Sun Joo (NCSOFT, Korea) and Hoon-Young Cho (NCSOFT, Korea)
- 16:00 Thu-A-V-5-6 475 Speech Resynthesis from Discrete Disentangled Self-Supervised Representations, Adam Polyak (Facebook, Israel), Yossi Adi (Facebook, Israel), Jade Copet (Facebook, France), Eugene Kharitonov (Facebook, France), Kushal Lakhotia (Facebook, USA), Wei-Ning Hsu (Facebook, USA), Abdelrahman Mohamed (Facebook, USA) and Emmanuel Dupoux (Facebook, France)
- 16:00 Thu-A-V-5-7 528 A Learned Conditional Prior for the VAE Acoustic Space of a TTS System, Penny Karanasou (Amazon, UK), Sri Karlapati (Amazon, UK), Alexis Moinet (Amazon, UK), Arnaud Joly (Amazon, UK), Ammar Abbas (Amazon, UK), Simon Slangen (Amazon, UK), Jaime Lorenzo-Trueba (Amazon, UK) and Thomas Drugman (Amazon, UK)
- 16:00 Thu-A-V-5-8 660 A Universal Multi-Speaker Multi-Style Text-to-Speech via Disentangled Representation Learning Based on Rényi Divergence Minimization, Dipjyoti Paul (University of Crete, Greece), Sankar Mukherjee (IIT, Italy), Yannis Pantazis (FORTH, Greece) and Yannis Stylianou (University of Crete, Greece)
- 16:00 Thu-A-V-5-9 806 Relational Data Selection for Data Augmentation of Speaker-Dependent Multi-Band MelGAN Vocoder, Yi-Chiao Wu (Nagoya University, Japan), Cheng-Hung Hu (Academia Sinica, Taiwan), Hung-Shin Lee (Academia Sinica, Taiwan), Yu-Huai Peng (Academia Sinica, Taiwan), Wen-Chin Huang (Nagoya University, Japan), Yu Tsao (Academia Sinica, Taiwan), Hsin-Min Wang (Academia Sinica, Taiwan) and Tomoki Toda (Nagoya University, Japan)
- 16:00 Thu-A-V-5-10 831 Reinforce-Aligner: Reinforcement Alignment Search for Robust End-to-End Text-to-Speech, Hyunseung Chung (Korea University, Korea), Sang-Hoon Lee (Korea University, Korea) and Seong-Whan Lee (Korea University, Korea)
- 16:00 Thu-A-V-5-11 851 Triple M: A Practical Text-to-Speech Synthesis System with Multi-Guidance Attention and Multi-Band Multi-Time LPCNet, Shilun Lin (Tencent, China), Fenglong Xie (Tencent, China), Li Meng (Tencent, China), Xinhui Li (Tencent, China) and Li Lu (Tencent, China)
- 16:00 Thu-A-V-5-12 1774 SC-GlowTTS: An Efficient Zero-Shot Multi-Speaker Text-To-Speech Model, Edresson Casanova (Universidade de São Paulo, Brazil), Christopher Shulby (DefinedCrowd, USA), Eren Gölge (Coqui, Germany), Nicolas Michael Müller (Fraunhofer AISEC, Germany), Frederico Santos de Oliveira (Universidade Federal de Goiás, Brazil), Arnaldo Candido Jr. (Universidade Tecnológica Federal do Paraná, Brazil), Anderson da Silva Soares (Universidade Federal de Goiás, Brazil), Sandra Maria Aluisio (Universidade de São Paulo, Brazil) and Moacir Antonelli Ponti (Universidade de São Paulo, Brazil)
Thu-A-V-6 Thursday, September 2, 16:00-18:00 Virtual: Tools, corpora and resources
- 16:00 Thu-A-V-6-1 245 Spoken ObjectNet: A Bias-Controlled Spoken Caption Dataset, Ian Palmer (MIT, USA), Andrew Rouditchenko (MIT, USA), Andrei Barbu (MIT, USA), Boris Katz (MIT, USA) and James Glass (MIT, USA)
- 16:00 Thu-A-V-6-2 11 The Multilingual TEDx Corpus for Speech Recognition and Translation, Elizabeth Salesky (Johns Hopkins University, USA), Matthew Wiesner (Johns Hopkins University, USA), Jacob Bremerman (University of Maryland, USA), Roldano Cattoni (FBK, Italy), Matteo Negri (FBK, Italy), Marco Turchi (FBK, Italy), Douglas W. Oard (University of Maryland, USA) and Matt Post (Johns Hopkins University, USA)
- 16:00 Thu-A-V-6-3 1435 Tusom2021: A Phonetically Transcribed Speech Dataset from an Endangered Language for Universal Phone Recognition Experiments, David R. Mortensen (Carnegie Mellon University, USA), Jordan Picone (University of Pittsburgh, USA), Xinjian Li (Carnegie Mellon University, USA) and Kathleen Siminyu (Georgia Tech, USA)
- 16:00 Thu-A-V-6-4 1397 AISHELL-4: An Open Source Dataset for Speech Enhancement, Separation, Recognition and Speaker Diarization in Conference Scenario, Yihui Fu (Northwestern Polytechnical University, China), Luyao Cheng (Northwestern Polytechnical University, China), Shubo Lv (Northwestern Polytechnical University, China), Yukai Jv (Northwestern Polytechnical University, China), Yuxiang Kong (Northwestern Polytechnical University, China), Zhuo Chen (Microsoft, USA), Yanxin Hu (Northwestern Polytechnical University, China), Lei Xie (Northwestern Polytechnical University, China), Jian Wu (Microsoft, China), Hui Bu (Beijing Shell Shell Technology, China), Xin Xu (Beijing Shell Shell Technology, China), Jun Du (USTC, China) and Jingdong Chen (Northwestern Polytechnical University, China)
- 16:00 Thu-A-V-6-5 1965 GigaSpeech: An Evolving, Multi-Domain ASR Corpus with 10,000 Hours of Transcribed Audio, Guoguo Chen (SpeechColab, China), Shuzhou Chai (SpeechColab, China), Guan-Bo Wang (SpeechColab, China), Jiayu Du (SpeechColab, China), Wei-Qiang Zhang (SpeechColab, China), Chao Weng (Tencent, China), Dan Su (Tencent, China), Daniel Povey (Xiaomi, China), Jan Trmal (Johns Hopkins University, USA), Junbo Zhang (Xiaomi, China), Mingjie Jin (Tencent, China), Sanjeev Khudanpur (Johns Hopkins University, USA), Shinji Watanabe (Johns Hopkins University, USA), Shuaijiang Zhao (KE, China), Wei Zou (KE, China), Xiangang Li (KE, China), Xuchen Yao (Seasalt AI, USA), Yongqing Wang (Xiaomi, China), Zhao You (Tencent, China) and Zhiyong Yan (Xiaomi, China)
- 16:00 Thu-A-V-6-6 2041 Look Who’s Talking: Active Speaker Detection in the Wild, You Jin Kim (Naver, Korea), Hee-Soo Heo (Naver, Korea), Soyeon Choe (Naver, Korea), Soo-Whan Chung (Naver, Korea), Yoohwan Kwon (Naver, Korea), Bong-Jin Lee (Naver, Korea), Youngki Kwon (Naver, Korea) and Joon Son Chung (Naver, Korea)
- 16:00 Thu-A-V-6-7 2000 AusKidTalk: An Auditory-Visual Corpus of 3- to 12-Year-Old Australian Children’s Speech, Beena Ahmed (UNSW Sydney, Australia), Kirrie J. Ballard (University of Sydney, Australia), Denis Burnham (Western Sydney University, Australia), Tharmakulasingam Sirojan (UNSW Sydney, Australia), Hadi Mehmood (UNSW Sydney, Australia), Dominique Estival (Western Sydney University, Australia), Elise Baker (Western Sydney University, Australia), Felicity Cox (Macquarie University, Australia), Joanne Arciuli (Flinders University, Australia), Titia Benders (Macquarie University, Australia), Katherine Demuth (Macquarie University, Australia), Barbara Kelly (University of Melbourne, Australia), Chloé Diskin-Holdaway (University of Mel bourne, Australia), Mostafa Shahin (UNSW Sydney, Australia), Vidhyasaharan Sethu (UNSW Sydney, Australia), Julien Epps (UNSW Sydney, Australia), Chwee Beng Lee (Western Sydney University, Australia) and Eliathamby Ambikairajah (UNSW Sydney, Australia)
- 16:00 Thu-A-V-6-8 45 Human-in-the-Loop Efficiency Analysis for Binary Classification in Edyson, Per Fallgren (KTH, Sweden) and Jens Edlund (KTH, Sweden)
- 16:00 Thu-A-V-6-9 1636 Annotation Confidence vs. Training Sample Size: Trade-Off Solution for Partially-Continuous Categorical Emotion Recognition, Elena Ryumina (RAS, Russia), Oxana Verkholyak (RAS, Russia) and Alexey Karpov (RAS, Russia)
- 16:00 Thu-A-V-6-10 1905 Europarl-ASR: A Large Corpus of Parliamentary Debates for Streaming ASR Benchmarking and Speech Data Filtering/Verbatimization, Gonçal V. Garcés Díaz-Munío (Universitat Politècnica de València, Spain), Joan-Albert Silvestre-Cerdà (Universitat Politècnica de València, Spain), Javier Jorge (Universitat Politècnica de València, Spain), Adrià Giménez Pastor (Universitat Politècnica de València, Spain), Javier Iranzo-Sánchez (Universitat Politècnica de València, Spain), Pau Baquero-Arnal (Universitat Politècnica de València, Spain), Nahuel Roselló (Universitat Politècnica de València, Spain), Alejandro Pérez-González-de-Martos (Universitat Politècnica de València, Spain), Jorge Civera (Universitat Politècnica de València, Spain), Albert Sanchis (Universitat Politècnica de València, Spain) and Alfons Juan (Universitat Politècnica de València, Spain)
- 16:00 Thu-A-V-6-11 1094 Towards Automatic Speech to Sign Language Generation, Parul Kapoor (IIT Kanpur, India), Rudrabha Mukhopadhyay (IIIT Hyderabad, India), Sindhu B. Hegde (IIIT Hyderabad, India), Vinay Namboodiri (IIT Kanpur, India) and C.V. Jawahar (IIIT Hyderabad, India)
- 16:00 Thu-A-V-6-12 1040 kosp2e: Korean Speech to English Translation Corpus, Won Ik Cho (Seoul National University, Korea), Seok Min Kim (Seoul National University, Korea), Hyunchang Cho (Naver, Korea) and Nam Soo Kim (Seoul National University, Korea)
- 16:00 Thu-A-V-6-13 1259 speechocean762: An Open-Source Non-Native English Speech Corpus for Pronunciation Assessment, Junbo Zhang (Xiaomi, China), Zhiwen Zhang (SpeechOcean, China), Yongqing Wang (Xiaomi, China), Zhiyong Yan (Xiaomi, China), Qiong Song (SpeechOcean, China), Yukai Huang (SpeechOcean, China), Ke Li (SpeechOcean, China), Daniel Povey (Xiaomi, China) and Yujun Wang (Xiaomi, China)
Thu-A-SS-1 Thursday, September 2, 16:00-18:00 Special-Virtual: Non-Autoregressive Sequential Modeling for Speech Processing
- 16:00 Introduction
- 16:06 Short presentations
- 16:45 Thu-A-SS-1-1 1955 An Improved Single Step Non-Autoregressive Transformer for Automatic Speech Recognition, Ruchao Fan (University of California at Los Angeles, USA), Wei Chu (PAII, USA), Peng Chang (PAII, USA), Jing Xiao (PAII, USA) and Abeer Alwan (University of California at Los Angeles, USA)
- 16:45 Thu-A-SS-1-2 2155 Multi-Speaker ASR Combining Non-Autoregressive Conformer CTC and Conditional Speaker Chain, Pengcheng Guo (Northwestern Polytechnical University, China), Xuankai Chang (Carnegie Mellon University, USA), Shinji Watanabe (Carnegie Mellon University, USA) and Lei Xie (Northwestern Polytechnical University, China)
- 16:45 Thu-A-SS-1-3 337 Pushing the Limits of Non-Autoregressive Speech Recognition, Edwin G. Ng (Google, USA), Chung-Cheng Chiu (Google, USA), Yu Zhang (Google, USA) and William Chan (Google, Canada)
- 16:45 Thu-A-SS-1-4 349 Non-Autoregressive Predictive Coding for Learning Speech Representations from Local Dependencies, Alexander H. Liu (MIT, USA), Yu-An Chung (MIT, USA) and James Glass (MIT, USA)
- 16:45 Thu-A-SS-1-5 911 Relaxing the Conditional Independence Assumption of CTC-Based ASR by Conditioning on Intermediate Predictions, Jumon Nozaki (LINE, Japan) and Tatsuya Komatsu (LINE, Japan)
- 16:45 Thu-A-SS-1-6 1131 Toward Streaming ASR with Non-Autoregressive Insertion-Based Model, Yuya Fujita (Yahoo, Japan), Tianzi Wang (Johns Hopkins University, USA), Shinji Watanabe (Carnegie Mellon University, USA) and Motoi Omachi (Yahoo, Japan)
- 16:45 Thu-A-SS-1-7 1171 Layer Pruning on Demand with Intermediate CTC, Jaesong Lee (Naver, Korea), Jingu Kang (Naver, Korea) and Shinji Watanabe (Carnegie Mellon University, USA)
- 16:45 Thu-A-SS-1-8 1449 Real-Time End-to-End Monaural Multi-Speaker Speech Recognition, Song Li (Xiamen University, China), Beibei Ouyang (Xiamen University, China), Fuchuan Tong (Xiamen University, China), Dexin Liao (Xiamen University, China), Lin Li (Xiamen University, China) and Qingyang Hong (Xiamen University, China)
- 16:45 Thu-A-SS-1-9 1556 Streaming End-to-End ASR Based on Blockwise Non-Autoregressive Models, Tianzi Wang (Johns Hopkins University, USA), Yuya Fujita (Yahoo, Japan), Xuankai Chang (Johns Hopkins University, USA) and Shinji Watanabe (Johns Hopkins University, USA)
- 16:45 Thu-A-SS-1-10 1770 TalkNet: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis, Stanislav Beliaev (NVIDIA, USA) and Boris Ginsburg (NVIDIA, USA)
- 16:45 Thu-A-SS-1-11 1897 WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis, Nanxin Chen (Johns Hopkins University, USA), Yu Zhang (Google, USA), Heiga Zen (Google, Japan), Ron J. Weiss (Google, USA), Mohammad Norouzi (Google, Canada), Najim Dehak (Johns Hopkins University, USA) and William Chan (Google, Canada)
- 16:45 Thu-A-SS-1-12 1906 Align-Denoise: Single-Pass Non-Autoregressive Speech Recognition, Nanxin Chen (Johns Hopkins University, USA), Piotr Żelasko (Johns Hopkins University, USA), Laureano Moro-Velázquez (Johns Hopkins University, USA), Jesús Villalba (Johns Hopkins University, USA) and Najim Dehak (Johns Hopkins University, USA)
- 16:45 Thu-A-SS-1-13 2121 VAENAR-TTS: Variational Auto-Encoder Based Non-AutoRegressive Text-to-Speech Synthesis, Hui Lu (CUHK, China), Zhiyong Wu (CUHK, China), Xixin Wu (University of Cambridge, UK), Xu Li (CUHK, China), Shiyin Kang (Huya, China), Xunying Liu (CUHK, China) and Helen Meng (CUHK, China)
Thu-A-SS-2 Thursday, September 2, 16:00-18:00 Special-Virtual: The ADReSSo Challenge: Detecting cognitive decline using speech only
- 16:00 Thu-A-SS-2-1 1220 Detecting Cognitive Decline Using Speech Only: The ADReSSo Challenge, Saturnino Luz (University of Edinburgh, UK), Fasih Haider (University of Edinburgh, UK), Sofia de la Fuente (University of Edinburgh, UK), Davida Fromm (Carnegie Mellon University, USA) and Brian MacWhinney (Carnegie Mellon University, USA)
- 16:00 Thu-A-SS-2-2 1589 Influence of the Interviewer on the Automatic Assessment of Alzheimer’s Disease in the Context of the ADReSSo Challenge, P.A. Pérez-Toro (FAU Erlangen-Nürnberg, Germany), S.P. Bayerl (TH Nürnberg, Germany), T. Arias-Vergara (FAU Erlangen-Nürnberg, Germany), J.C. Vásquez-Correa (FAU Erlangen-Nürnberg, Germany), P. Klumpp (FAU Erlangen-Nürnberg, Germany), M. Schuster (LMU München, Germany), Elmar Nöth (FAU Erlangen-Nürnberg, Germany), J.R. Orozco-Arroyave (FAU Erlangen-Nürnberg, Germany) and K. Riedhammer (TH Nürnberg, Germany)
- 16:00 Thu-A-SS-2-3 332 WavBERT: Exploiting Semantic and Non-Semantic Speech Using Wav2vec and BERT for Dementia Detection, Youxiang Zhu (UMass Boston, USA), Abdelrahman Obyat (UMass Boston, USA), Xiaohui Liang (UMass Boston, USA), John A. Batsis (University of North Carolina, USA) and Robert M. Roth (Geisel School of Medicine at Dartmouth, USA)
- 16:00 Thu-A-SS-2-4 753 Alzheimer Disease Recognition Using Speech-Based Embeddings From Pre-Trained Models, Lara Gauder (UBA-CONICET ICC, Argentina), Leonardo Pepino (UBA-CONICET ICC, Argentina), Luciana Ferrer (UBA-CONICET ICC, Argentina) and Pablo Riera (UBA-CONICET ICC, Argentina)
- 16:00 Thu-A-SS-2-5 759 Comparing Acoustic-Based Approaches for Alzheimer’s Disease Detection, Aparna Balagopalan (Winterlight Labs, Canada) and Jekaterina Novikova (Winterlight Labs, Canada)
- 16:00 Thu-A-SS-2-6 1415 Alzheimer’s Disease Detection from Spontaneous Speech Through Combining Linguistic Complexity and (Dis)Fluency Features with Pretrained Language Models, Yu Qiao (RWTH Aachen University, Germany), Xuefeng Yin (RWTH Aachen University, Germany), Daniel Wiechmann (Universiteit van Amsterdam, The Netherlands) and Elma Kerz (RWTH Aachen University, Germany)
- 16:00 Thu-A-SS-2-7 1519 Using the Outputs of Different Automatic Speech Recognition Paradigms for Acoustic- and BERT-Based Alzheimer’s Dementia Detection Through Spontaneous Speech, Yilin Pan (University of Sheffield, UK), Bahman Mirheidari (University of Sheffield, UK), Jennifer M. Harris (University of Manchester, UK), Jennifer C. Thompson (University of Manchester, UK), Matthew Jones (University of Manchester, UK), Julie S. Snowden (University of Manchester, UK), Daniel Blackburn (University of Sheffield, UK) and Heidi Christensen (University of Sheffield, UK)
- 16:00 Thu-A-SS-2-8 1572 Tackling the ADRESSO Challenge 2021: The MUET-RMIT System for Alzheimer’s Dementia Recognition from Spontaneous Speech, Zafi Sherhan Syed (MUET, Pakistan), Muhammad Shehram Shah Syed (RMIT University, Australia), Margaret Lech (RMIT University, Australia) and Elena Pirogova (RMIT University, Australia)
- 16:00 Thu-A-SS-2-9 1633 Alzheimer’s Dementia Recognition Using Acoustic, Lexical, Disfluency and Speech Pause Features Robust to Noisy Inputs, Morteza Rohanian (Queen Mary University of London, UK), Julian Hough (Queen Mary University of London, UK) and Matthew Purver (Queen Mary University of London, UK)
- 16:00 Thu-A-SS-2-10 1850 Automatic Detection and Assessment of Alzheimer Disease Using Speech and Language Technologies in Low-Resource Scenarios, Raghavendra Pappagari (Johns Hopkins University, USA), Jaejin Cho (Johns Hopkins University, USA), Sonal Joshi (Johns Hopkins University, USA), Laureano Moro-Velázquez (Johns Hopkins University, USA), Piotr Żelasko (Johns Hopkins University, USA), Jesús Villalba (Johns Hopkins University, USA) and Najim Dehak (Johns Hopkins University, USA)
- 16:00 Thu-A-SS-2-11 2002 Automatic Detection of Alzheimer’s Disease Using Spontaneous Speech Only, Jun Chen (University of Michigan, USA), Jieping Ye (University of Michigan, USA), Fengyi Tang (Michigan State University, USA) and Jiayu Zhou (Michigan State University, USA)
- 16:00 Thu-A-SS-2-12 2024 Modular Multi-Modal Attention Network for Alzheimer’s Disease Detection Using Patient Audio and Language Data, Ning Wang (Stevens Institute of Technology, USA), Yupeng Cao (Stevens Institute of Technology, USA), Shuai Hao (Stevens Institute of Technology, USA), Zongru Shao (CASUS, Germany) and K.P. Subbalakshmi (Stevens Institute of Technology, USA)
Fri-M-O-1 Friday, September 3, 11:00-13:00 In-person Oral: Robust and Far-field ASR
- 11:00 Fri-M-O-1-1 1190 Self-Attention Channel Combinator Frontend for End-to-End Multichannel Far-Field Speech Recognition, Rong Gong (Nuance Communications, Austria), Carl Quillen (Nuance Communications, USA), Dushyant Sharma (Nuance Communications, USA), Andrew Goderre (Nuance Communications, USA), José Laínez (Nuance Communications, Spain) and Ljubomir Milanović (Nuance Communications, Austria)
- 11:20 Fri-M-O-1-2 1237 ETLT 2021: Shared Task on Automatic Speech Recognition for Non-Native Children’s Speech, R. Gretter (FBK, Italy), Marco Matassoni (FBK, Italy), D. Falavigna (FBK, Italy), A. Misra (Educational Testing Service, USA), C.W. Leong (Educational Testing Service, USA), K. Knill (University of Cambridge, UK) and L. Wang (University of Cambridge, UK)
- 11:40 Fri-M-O-1-3 1241 Age-Invariant Training for End-to-End Child Speech Recognition Using Adversarial Multi-Task Learning, Lars Rumberg (Leibniz Universität Hannover, Germany), Hanna Ehlert (Leibniz Universität Hannover, Germany), Ulrike Lüdtke (Leibniz Universität Hannover, Germany) and Jörn Ostermann (Leibniz Universität Hannover, Germany)
- 12:00 Fri-M-O-1-4 1315 Learning to Rank Microphones for Distant Speech Recognition, Samuele Cornell (Università Politecnica delle Marche, Italy), Alessio Brutti (FBK, Italy), Marco Matassoni (FBK, Italy) and Stefano Squartini (Università Politecnica delle Marche, Italy)
- 12:20 Fri-M-O-1-5 2202 Simulating Reading Mistakes for Child Speech Transformer-Based Phone Recognition, Lucile Gelin (IRIT (UMR 5505), France), Thomas Pellegrini (IRIT (UMR 5505), France), Julien Pinquier (IRIT (UMR 5505), France) and Morgane Daniel (Lalilo, France)
Fri-M-O-2 Friday, September 3, 11:00-13:00 In-person Oral: Speech Synthesis: Prosody Modeling II
- 11:00 Fri-M-O-2-1 275 Alternate Endings: Improving Prosody for Incremental Neural TTS with Predicted Future Text Input, Brooke Stephenson (GIPSA-lab (UMR 5216), France), Thomas Hueber (GIPSA-lab (UMR 5216), France), Laurent Girin (GIPSA-lab (UMR 5216), France) and Laurent Besacier (LIG (UMR 5217), France)
- 11:20 Fri-M-O-2-2 1538 Exploring Emotional Prototypes in a High Dimensional TTS Latent Space, Pol van Rijn (MPI for Empirical Aesthetics, Germany), Silvan Mertes (Universität Augsburg, Germany), Dominik Schiller (Universität Augsburg, Germany), Peter M.C. Harrison (MPI for Empirical Aesthetics, Germany), Pauline Larrouy-Maestri (MPI for Empirical Aesthetics, Germany), Elisabeth André (Universität Augsburg, Germany) and Nori Jacoby (MPI for Empirical Aesthetics, Germany)
- 11:40 Fri-M-O-2-3 1583 Ctrl-P: Temporal Control of Prosodic Variation for Speech Synthesis, Devang S. Ram Mohan (Papercup Technologies, UK), Vivian Hu (Papercup Technologies, UK), Tian Huey Teh (Papercup Technologies, UK), Alexandra Torresquintero (Papercup Technologies, UK), Christopher G.R. Wallis (Papercup Technologies, UK), Marlene Staib (Papercup Technologies, UK), Lorenzo Foglianti (Papercup Technologies, UK), Jiameng Gao (Papercup Technologies, UK) and Simon King (Papercup Technologies, UK)
- 12:00 Fri-M-O-2-4 1610 ADEPT: A Dataset for Evaluating Prosody Transfer, Alexandra Torresquintero (Papercup Technologies, UK), Tian Huey Teh (Papercup Technologies, UK), Christopher G.R. Wallis (Papercup Technologies, UK), Marlene Staib (Papercup Technologies, UK), Devang S. Ram Mohan (Papercup Technologies, UK), Vivian Hu (Papercup Technologies, UK), Lorenzo Foglianti (Papercup Technologies, UK), Jiameng Gao (Papercup Technologies, UK) and Simon King (Papercup Technologies, UK)
- 12:20 Fri-M-O-2-5 125 Prosodic Boundary Prediction Model for Vietnamese Text-To-Speech, Nguyen Thi Thu Trang (Hanoi University of Science & Technology, Vietnam), Nguyen Hoang Ky (Hanoi University of Science & Technology, Vietnam), Albert Rilliard (LISN (UMR 9015), France) and Christophe d’Alessandro (∂’Alembert (UMR 7190), France)
Fri-M-O-3 Friday, September 3, 11:00-13:00 In-person Oral: Source Separation III
- 11:00 Fri-M-O-3-1 493 Many-Speakers Single Channel Speech Separation with Optimal Permutation Training, Shaked Dovrat (Tel Aviv University, Israel), Eliya Nachmani (Tel Aviv University, Israel) and Lior Wolf (Tel Aviv University, Israel)
- 11:20 Fri-M-O-3-2 1230 Combating Reverberation in NTF-Based Speech Separation Using a Sub-Source Weighted Multichannel Wiener Filter and Linear Prediction, Mieszko Fraś (AGH UST, Poland), Marcin Witkowski (AGH UST, Poland) and Konrad Kowalczyk (AGH UST, Poland)
- 11:40 Fri-M-O-3-3 1418 A Hands-On Comparison of DNNs for Dialog Separation Using Transfer Learning from Music Source Separation, Martin Strauss (AudioLabs, Germany), Jouni Paulus (AudioLabs, Germany), Matteo Torcoli (Fraunhofer IIS, Germany) and Bernd Edler (AudioLabs, Germany)
- 12:00 Fri-M-O-3-4 1552 GlobalPhone Mix-To-Separate Out of 2: A Multilingual 2000 Speakers Mixtures Database for Speech Separation, Marvin Borsdorf (Universität Bremen, Germany), Chenglin Xu (NUS, Singapore), Haizhou Li (NUS, Singapore) and Tanja Schultz (Universität Bremen, Germany)
Fri-M-V-1 Friday, September 3, 11:00-13:00 Virtual: Non-native speech
- 11:00 Fri-M-V-1-1 21 Cross-Linguistic Perception of the Japanese Singleton/Geminate Contrast: Korean, Mandarin and Mongolian Compared, Kimiko Tsukada (Macquarie University, Australia), Yurong (Inner Mongolia University, China), Joo-Yeon Kim (Konkuk University, Korea), Jeong-Im Han (Konkuk University, Korea) and John Hajek (University of Melbourne, Australia)
- 11:00 Fri-M-V-1-2 86 Detection of Lexical Stress Errors in Non-Native (L2) English with Data Augmentation and Attention, Daniel Korzekwa (Amazon, Poland), Roberto Barra-Chicote (Amazon, UK), Szymon Zaporowski (Gdansk University of Technology, Poland), Grzegorz Beringer (Amazon, Poland), Jaime Lorenzo-Trueba (Amazon, UK), Alicja Serafinowicz (Amazon, Poland), Jasha Droppo (Amazon, USA), Thomas Drugman (Amazon, UK) and Bozena Kostek (Gdansk University of Technology, Poland)
- 11:00 Fri-M-V-1-3 315 Testing Acoustic Voice Quality Classification Across Languages and Speech Styles, Bettina Braun (Universität Konstanz, Germany), Nicole Dehé (Universität Konstanz, Germany), Marieke Einfeldt (Universität Konstanz, Germany), Daniela Wochner (Universität Konstanz, Germany) and Katharina Zahner-Ritter (Universität Trier, Germany)
- 11:00 Fri-M-V-1-4 316 Acquisition of Prosodic Focus Marking by Three- to Six-Year-Old Children Learning Mandarin Chinese, Qianyutong Zhang (NJUST, China), Kexin Lyu (NJUST, China), Zening Chen (NJUST, China) and Ping Tang (NJUST, China)
- 11:00 Fri-M-V-1-5 372 Adaptive Listening Difficulty Detection for L2 Learners Through Moderating ASR Resources, Maryam Sadat Mirzaei (RIKEN, Japan) and Kourosh Meshgi (RIKEN, Japan)
- 11:00 Fri-M-V-1-6 581 F₀ Patterns of L2 English Speech by Mandarin Chinese Learners, Hongwei Ding (SJTU, China), Binghuai Lin (Tencent, China) and Liyuan Wang (Tencent, China)
- 11:00 Fri-M-V-1-7 843 A Neural Network-Based Noise Compensation Method for Pronunciation Assessment, Binghuai Lin (Tencent, China) and Liyuan Wang (Tencent, China)
- 11:00 Fri-M-V-1-8 1003 Phonetic Distance and Surprisal in Multilingual Priming: Evidence from Slavic, Jacek Kudera (Universität des Saarlandes, Germany), Philip Georgis (Universität des Saarlandes, Germany), Bernd Möbius (Universität des Saarlandes, Germany), Tania Avgustinova (Universität des Saarlandes, Germany) and Dietrich Klakow (Universität des Saarlandes, Germany)
- 11:00 Fri-M-V-1-9 1082 A Preliminary Study on Discourse Prosody Encoding in L1 and L2 English Spontaneous Narratives, Yuqing Zhang (BLCU, China), Zhu Li (BLCU, China), Binghuai Lin (Tencent, China) and Jinsong Zhang (BLCU, China)
- 11:00 Fri-M-V-1-10 1467 Transformer Based End-to-End Mispronunciation Detection and Diagnosis, Minglin Wu (CUHK, China), Kun Li (SpeechX, China), Wai-Kim Leung (CUHK, China) and Helen Meng (CUHK, China)
- 11:00 Fri-M-V-1-11 1545 L1 Identification from L2 Speech Using Neural Spectrogram Analysis, Calbert Graham (University of Cambridge, UK)
Fri-M-V-2 Friday, September 3, 11:00-13:00 Virtual: Phonetics II
- 11:00 Fri-M-V-2-1 1823 Leveraging Real-Time MRI for Illuminating Linguistic Velum Action, Miran Oh (University of Southern California, USA), Dani Byrd (University of Southern California, USA) and Shrikanth S. Narayanan (University of Southern California, USA)
- 11:00 Fri-M-V-2-2 187 Segmental Alignment of English Syllables with Singleton and Cluster Onsets, Zirui Liu (University College London, UK) and Yi Xu (University College London, UK)
- 11:00 Fri-M-V-2-3 685 Exploration of Welsh English Pre-Aspiration: How Wide-Spread is it?, Míša Hejná (Aarhus University, Denmark)
- 11:00 Fri-M-V-2-4 1056 Revisiting Recall Effects of Filler Particles in German and English, Beeke Muhlack (Universität des Saarlandes, Germany), Mikey Elmers (Universität des Saarlandes, Germany), Heiner Drenhaus (Universität des Saarlandes, Germany), Jürgen Trouvain (Universität des Saarlandes, Germany), Marjolein van Os (Universität des Saarlandes, Germany), Raphael Werner (Universität des Saarlandes, Germany), Margarita Ryzhova (Universität des Saarlandes, Germany) and Bernd Möbius (Universität des Saarlandes, Germany)
- 11:00 Fri-M-V-2-5 1122 How Reliable Are Phonetic Data Collected Remotely? Comparison of Recording Devices and Environments on Acoustic Measurements, Chunyu Ge (CUHK, China), Yixuan Xiong (CUHK, China) and Peggy Mok (CUHK, China)
- 11:00 Fri-M-V-2-6 1326 A Cross-Dialectal Comparison of Apical Vowels in Beijing Mandarin, Northeastern Mandarin and Southwestern Mandarin: An EMA and Ultrasound Study, Jing Huang (National Tsing Hua University, Taiwan), Feng-fan Hsieh (National Tsing Hua University, Taiwan) and Yueh-chin Chang (National Tsing Hua University, Taiwan)
- 11:00 Fri-M-V-2-7 1379 Dissecting the Aero-Acoustic Parameters of Open Articulatory Transitions, Mark Gibson (Universidad de Navarra, Spain), Oihane Muxika (Universidad de Navarra, Spain) and Marianne Pouplier (LMU München, Germany)
- 11:00 Fri-M-V-2-8 1400 Quantifying Vocal Tract Shape Variation and its Acoustic Impact: A Geometric Morphometric Approach, Amelia J. Gully (University of York, UK)
- 11:00 Fri-M-V-2-9 1481 Speech Perception and Loanword Adaptations: The Case of Copy-Vowel Epenthesis, Adriana Guevara-Rukoz (LSCP (UMR 8554), France), Shi Yu (LPP (UMR 7018), France) and Sharon Peperkamp (LSCP (UMR 8554), France)
- 11:00 Fri-M-V-2-10 1640 Speakers Coarticulate Less When Facing Real and Imagined Communicative Difficulties: An Analysis of Read and Spontaneous Speech from the LUCID Corpus, Zhe-chen Guo (University of Texas at Austin, USA) and Rajka Smiljanic (University of Texas at Austin, USA)
- 11:00 Fri-M-V-2-11 1649 Developmental Changes of Vowel Acoustics in Adolescents, Einar Meister (Tallinn University of Technology, Estonia) and Lya Meister (Tallinn University of Technology, Estonia)
- 11:00 Fri-M-V-2-12 1724 Context and Co-Text Influence on the Accuracy Production of Italian L2 Non-Native Sounds, Sonia d’Apolito (Università del Salento, Italy) and Barbara Gili Fivela (Università del Salento, Italy)
- 11:00 Fri-M-V-2-13 1846 A New Vowel Normalization for Sociophonetics, Wilbert Heeringa (Fryske Akademy, The Netherlands) and Hans Van de Velde (Fryske Akademy, The Netherlands)
- 11:00 Fri-M-V-2-14 2167 The Pacific Expansion: Optimizing Phonetic Transcription of Archival Corpora, Rosey Billington (ANU, Australia), Hywel Stoakes (University of Melbourne, Australia) and Nick Thieberger (University of Melbourne, Australia)
Fri-M-V-3 Friday, September 3, 11:00-13:00 Virtual: Search/decoding techniques and confidence measures for ASR
- 11:00 Fri-M-V-3-1 1367 FSR: Accelerating the Inference Process of Transducer-Based Models by Applying Fast-Skip Regularization, Zhengkun Tian (CAS, China), Jiangyan Yi (CAS, China), Ye Bai (CAS, China), Jianhua Tao (CAS, China), Shuai Zhang (CAS, China) and Zhengqi Wen (CAS, China)
- 11:00 Fri-M-V-3-2 1716 LT-LM: A Novel Non-Autoregressive Language Model for Single-Shot Lattice Rescoring, Anton Mitrofanov (ITMO University, Russia), Mariya Korenevskaya (STC-innovations, Russia), Ivan Podluzhny (ITMO University, Russia), Yuri Khokhlov (STC-innovations, Russia), Aleksandr Laptev (ITMO University, Russia), Andrei Andrusenko (ITMO University, Russia), Aleksei Ilin (STC-innovations, Russia), Maxim Korenevsky (STC-innovations, Russia), Ivan Medennikov (ITMO University, Russia) and Aleksei Romanenko (ITMO University, Russia)
- 11:00 Fri-M-V-3-3 658 A Hybrid Seq-2-Seq ASR Design for On-Device and Server Applications, Cyril Allauzen (Google, USA), Ehsan Variani (Google, USA), Michael Riley (Google, USA), David Rybach (Google, USA) and Hao Zhang (Google, USA)
- 11:00 Fri-M-V-3-4 1107 VAD-Free Streaming Hybrid CTC/Attention ASR for Unsegmented Recording, Hirofumi Inaguma (Kyoto University, Japan) and Tatsuya Kawahara (Kyoto University, Japan)
- 11:00 Fri-M-V-3-5 1983 WeNet: Production Oriented Streaming and Non-Streaming End-to-End Speech Recognition Toolkit, Zhuoyuan Yao (Northwestern Polytechnical University, China), Di Wu (Mobvoi, China), Xiong Wang (Northwestern Polytechnical University, China), Binbin Zhang (Mobvoi, China), Fan Yu (Northwestern Polytechnical University, China), Chao Yang (Mobvoi, China), Zhendong Peng (Mobvoi, China), Xiaoyu Chen (Mobvoi, China), Lei Xie (Northwestern Polytechnical University, China) and Xin Lei (Mobvoi, China)
- 11:00 Fri-M-V-3-6 1992 Cross-Modal Transformer-Based Neural Correction Models for Automatic Speech Recognition, Tomohiro Tanaka (NTT, Japan), Ryo Masumura (NTT, Japan), Mana Ihori (NTT, Japan), Akihiko Takashima (NTT, Japan), Takafumi Moriya (NTT, Japan), Takanori Ashihara (NTT, Japan), Shota Orihashi (NTT, Japan) and Naoki Makishima (NTT, Japan)
- 11:00 Fri-M-V-3-7 176 Deep Neural Network Calibration for E2E Speech Recognition System, Mun-Hak Lee (Hanyang University, Korea) and Joon-Hyuk Chang (Hanyang University, Korea)
- 11:00 Fri-M-V-3-8 690 Residual Energy-Based Models for End-to-End Speech Recognition, Qiujia Li (University of Cambridge, UK), Yu Zhang (Google, USA), Bo Li (Google, USA), Liangliang Cao (Google, USA) and Philip C. Woodland (University of Cambridge, UK)
- 11:00 Fri-M-V-3-9 1207 Multi-Task Learning for End-to-End ASR Word and Utterance Confidence with Deletion Prediction, David Qiu (Google, USA), Yanzhang He (Google, USA), Qiujia Li (University of Cambridge, UK), Yu Zhang (Google, USA), Liangliang Cao (Google, USA) and Ian McGraw (Google, USA)
- 11:00 Fri-M-V-3-10 1516 Insights on Neural Representations for End-to-End Speech Recognition, Anna Ollerenshaw (University of Sheffield, UK), Md. Asif Jalal (University of Sheffield, UK) and Thomas Hain (University of Sheffield, UK)
- 11:00 Fri-M-V-3-11 1666 Sequence-Level Confidence Classifier for ASR Utterance Accuracy and Application to Acoustic Models, Amber Afshan (University of California at Los Angeles, USA), Kshitiz Kumar (Microsoft, USA) and Jian Wu (Microsoft, USA)
Fri-M-V-4 Friday, September 3, 11:00-13:00 Virtual: Speech Synthesis: Linguistic processing, paradigms and other topics
- 11:00 Fri-M-V-4-1 1936 Unsupervised Learning of Disentangled Speech Content and Style Representation, Andros Tjandra (NAIST, Japan), Ruoming Pang (Google, USA), Yu Zhang (Google, USA) and Shigeki Karita (Google, Japan)
- 11:00 Fri-M-V-4-2 885 Label Embedding for Chinese Grapheme-to-Phoneme Conversion, Eunbi Choi (KAIST, Korea), Hwa-Yeon Kim (Naver, Korea), Jong-Hwan Kim (Naver, Korea) and Jae-Min Kim (Naver, Korea)
- 11:00 Fri-M-V-4-3 1087 PDF: Polyphone Disambiguation in Chinese by Using FLAT, Haiteng Zhang (Databaker Technology, China)
- 11:00 Fri-M-V-4-4 1232 Improving Polyphone Disambiguation for Mandarin Chinese by Combining Mix-Pooling Strategy and Window-Based Attention, Junjie Li (Ping An Technology, China), Zhiyu Zhang (National Tsing Hua University, Taiwan), Minchuan Chen (Ping An Technology, China), Jun Ma (Ping An Technology, China), Shaojun Wang (Ping An Technology, China) and Jing Xiao (Ping An Technology, China)
- 11:00 Fri-M-V-4-5 502 Polyphone Disambiguation in Mandarin Chinese with Semi-Supervised Learning, Yi Shi (Xmov, China), Congyi Wang (Xmov, China), Yu Chen (Xmov, China) and Bin Wang (Xmov, China)
- 11:00 Fri-M-V-4-6 609 A Neural-Network-Based Approach to Identifying Speakers in Novels, Yue Chen (USTC, China), Zhen-Hua Ling (USTC, China) and Qing-Feng Liu (USTC, China)
- 11:00 Fri-M-V-4-7 1092 UnitNet-Based Hybrid Speech Synthesis, Xiao Zhou (USTC, China), Zhen-Hua Ling (USTC, China) and Li-Rong Dai (USTC, China)
- 11:00 Fri-M-V-4-8 946 Dynamically Adaptive Machine Speech Chain Inference for TTS in Noisy Environment: Listen and Speak Louder, Sashi Novitasari (NAIST, Japan), Sakriani Sakti (NAIST, Japan) and Satoshi Nakamura (NAIST, Japan)
- 11:00 Fri-M-V-4-9 1192 LinearSpeech: Parallel Text-to-Speech with Linear Complexity, Haozhe Zhang (CAS, China), Zhihua Huang (UCAS, China), Zengqiang Shang (CAS, China), Pengyuan Zhang (CAS, China) and Yonghong Yan (CAS, China)
Fri-M-V-5 Friday, September 3, 11:00-13:00 Virtual: Speech type classification and diagnosis
- 11:00 Fri-M-V-5-1 83 An Agent for Competing with Humans in a Deceptive Game Based on Vocal Cues, Noa Mansbach (Ariel University, Israel), Evgeny Hershkovitch Neiterman (Ariel University, Israel) and Amos Azaria (Ariel University, Israel)
- 11:00 Fri-M-V-5-2 378 A Multi-Branch Deep Learning Network for Automated Detection of COVID-19, Ahmed Fakhry (University of Alexandria, Egypt), Xinyi Jiang (Independent Researcher, USA), Jaclyn Xiao (Duke University, USA), Gunvant Chaudhari (University of California at San Francisco, USA) and Asriel Han (Stanford University, USA)
- 11:00 Fri-M-V-5-3 438 RW-Resnet: A Novel Speech Anti-Spoofing Model Using Raw Waveform, Youxuan Ma (Shanghai University, China), Zongze Ren (Shanghai University, China) and Shugong Xu (Shanghai University, China)
- 11:00 Fri-M-V-5-4 524 Fake Audio Detection in Resource-Constrained Settings Using Microfeatures, Hira Dhamyal (LUMS, Pakistan), Ayesha Ali (LUMS, Pakistan), Ihsan Ayyub Qazi (LUMS, Pakistan) and Agha Ali Raza (LUMS, Pakistan)
- 11:00 Fri-M-V-5-5 630 Coughing-Based Recognition of Covid-19 with Spatial Attentive ConvLSTM Recurrent Neural Networks, Tianhao Yan (Harbin Engineering University, China), Hao Meng (Harbin Engineering University, China), Emilia Parada-Cabaleiro (Johannes Kepler Universität Linz, Austria), Shuo Liu (Universität Augsburg, Germany), Meishu Song (Universität Augsburg, Germany) and Björn W. Schuller (Universität Augsburg, Germany)
- 11:00 Fri-M-V-5-6 636 Knowledge Distillation for Singing Voice Detection, Soumava Paul (IIT Kharagpur, India), Gurunath Reddy M. (IIT Kharagpur, India), K. Sreenivasa Rao (IIT Kharagpur, India) and Partha Pratim Das (IIT Kharagpur, India)
- 11:00 Fri-M-V-5-7 861 Age Estimation with Speech-Age Model for Heterogeneous Speech Datasets, Ryu Takeda (Osaka University, Japan) and Kazunori Komatani (Osaka University, Japan)
- 11:00 Fri-M-V-5-8 1142 Open-Set Audio Classification with Limited Training Resources Based on Augmentation Enhanced Variational Auto-Encoder GAN with Detection-Classification Joint Training, Kah Kuan Teh (A*STAR, Singapore) and Huy Dat Tran (A*STAR, Singapore)
- 11:00 Fri-M-V-5-9 1245 Deep Spectral-Cepstral Fusion for Shouted and Normal Speech Classification, Takahiro Fukumori (Ritsumeikan University, Japan)
- 11:00 Fri-M-V-5-10 1592 Automatic Detection of Shouted Speech Segments in Indian News Debates, Shikha Baghel (IIT Guwahati, India), Mrinmoy Bhattacharjee (IIT Guwahati, India), S.R. Mahadeva Prasanna (IIT Dharwad, India) and Prithwijit Guha (IIT Guwahati, India)
- 11:00 Fri-M-V-5-11 1705 Generalized Spoofing Detection Inspired from Audio Generation Artifacts, Yang Gao (Carnegie Mellon University, USA), Tyler Vuong (Carnegie Mellon University, USA), Mahsa Elyasi (AI Foundation, USA), Gaurav Bharaj (AI Foundation, USA) and Rita Singh (Carnegie Mellon University, USA)
- 11:00 Fri-M-V-5-12 2138 Overlapped Speech Detection Based on Spectral and Spatial Feature Fusion, Weiguang Chen (Hunan University, China), Van Tung Pham (NTU, Singapore), Eng Siong Chng (NTU, Singapore) and Xionghu Zhong (Hunan University, China)
Fri-M-V-6 Friday, September 3, 11:00-13:00 Virtual: Spoken Term Detection & Voice Search
- 11:00 Fri-M-V-6-1 678 Do Acoustic Word Embeddings Capture Phonological Similarity? An Empirical Study, Badr M. Abdullah (Universität des Saarlandes, Germany), Marius Mosbach (Universität des Saarlandes, Germany), Iuliia Zaitova (Universität des Saarlandes, Germany), Bernd Möbius (Universität des Saarlandes, Germany) and Dietrich Klakow (Universität des Saarlandes, Germany)
- 11:00 Fri-M-V-6-2 97 Paraphrase Label Alignment for Voice Application Retrieval in Spoken Language Understanding, Zheng Gao (Amazon, USA), Radhika Arava (Amazon, USA), Qian Hu (Amazon, USA), Xibin Gao (Amazon, USA), Thahir Mohamed (Amazon, USA), Wei Xiao (Amazon, USA) and Mohamed AbdelHady (Amazon, USA)
- 11:00 Fri-M-V-6-3 204 Personalized Keyphrase Detection Using Speaker and Environment Information, Rajeev Rikhye (Google, USA), Quan Wang (Google, USA), Qiao Liang (Google, USA), Yanzhang He (Google, USA), Ding Zhao (Google, USA), Yiteng Huang (Google, USA), Arun Narayanan (Google, USA) and Ian McGraw (Google, USA)
- 11:00 Fri-M-V-6-4 1428 Streaming Transformer for Hardware Efficient Voice Trigger Detection and False Trigger Mitigation, Vineet Garg (Apple, USA), Wonil Chang (Apple, USA), Siddharth Sigtia (Apple, UK), Saurabh Adya (Apple, USA), Pramod Simha (Apple, USA), Pranay Dighe (Apple, USA) and Chandra Dhir (Apple, USA)
- 11:00 Fri-M-V-6-5 1966 Few-Shot Keyword Spotting in Any Language, Mark Mazumder (Harvard University, USA), Colby Banbury (Harvard University, USA), Josh Meyer (Coqui, Germany), Pete Warden (Google, USA) and Vijay Janapa Reddi (Harvard University, USA)
- 11:00 Fri-M-V-6-6 136 Text Anchor Based Metric Learning for Small-Footprint Keyword Spotting, Li Wang (Peking University, China), Rongzhi Gu (Peking University, China), Nuo Chen (Peking University, China) and Yuexian Zou (Peking University, China)
- 11:00 Fri-M-V-6-7 147 A Meta-Learning Approach for User-Defined Spoken Term Classification with Varying Classes and Examples, Yangbin Chen (CUHK, China), Tom Ko (SUSTech, China) and Jianping Wang (CityU, China)
- 11:00 Fri-M-V-6-8 400 Auxiliary Sequence Labeling Tasks for Disfluency Detection, Dongyub Lee (Kakao, Korea), Byeongil Ko (Kakao, Korea), Myeong Cheol Shin (Kakao, Korea), Taesun Whang (Wisenut, Korea), Daniel Lee (Kakao, Korea), Eunhwa Kim (Kakao, Korea), Eunggyun Kim (Kakao, Korea) and Jaechoon Jo (Hanshin University, Korea)
- 11:00 Fri-M-V-6-9 458 Energy-Friendly Keyword Spotting System Using Add-Based Convolution, Hang Zhou (Huawei Technologies, China), Wenchao Hu (Huawei Technologies, China), Yu Ting Yeung (Huawei Technologies, China) and Xiao Chen (Huawei Technologies, China)
- 11:00 Fri-M-V-6-10 602 The 2020 Personalized Voice Trigger Challenge: Open Datasets, Evaluation Metrics, Baseline System and Results, Yan Jia (Duke Kunshan University, China), Xingming Wang (Duke Kunshan University, China), Xiaoyi Qin (Duke Kunshan University, China), Yinping Zhang (Lenovo, China), Xuyang Wang (Lenovo, China), Junjie Wang (Lenovo, China), Dong Zhang (Sun Yat-sen University, China) and Ming Li (Duke Kunshan University, China)
- 11:00 Fri-M-V-6-11 817 Auto-KWS 2021 Challenge: Task, Datasets, and Baselines, Jingsong Wang (4Paradigm, China), Yuxuan He (4Paradigm, China), Chunyu Zhao (4Paradigm, China), Qijie Shao (Northwestern Polytechnical University, China), Wei-Wei Tu (4Paradigm, China), Tom Ko (SUSTech, China), Hung-yi Lee (National Taiwan University, Taiwan) and Lei Xie (Northwestern Polytechnical University, China)
- 11:00 Fri-M-V-6-12 1286 Keyword Transformer: A Self-Attention Model for Keyword Spotting, Axel Berg (Arm, UK), Mark O’Connor (Arm, UK) and Miguel Tairum Cruz (Arm, UK)
- 11:00 Fri-M-V-6-13 1395 Teaching Keyword Spotters to Spot New Keywords with Limited Examples, Abhijeet Awasthi (Google, Switzerland), Kevin Kilgour (Google, Switzerland) and Hassan Rom (Google, Switzerland)
Fri-M-V-7 Friday, September 3, 11:00-13:00 Virtual: Voice Anti-Spoofing and Countermeasure
- 11:00 Fri-M-V-7-1 702 A Comparative Study on Recent Neural Spoofing Countermeasures for Synthetic Speech Detection, Xin Wang (NII, Japan) and Junichi Yamagishi (NII, Japan)
- 11:00 Fri-M-V-7-2 738 An Initial Investigation for Detecting Partially Spoofed Audio, Lin Zhang (NII, Japan), Xin Wang (NII, Japan), Erica Cooper (NII, Japan), Junichi Yamagishi (NII, Japan), Jose Patino (EURECOM, France) and Nicholas Evans (EURECOM, France)
- 11:00 Fri-M-V-7-3 847 Siamese Network with wav2vec Feature for Spoofing Speech Detection, Yang Xie (Zhejiang University, China), Zhenchuan Zhang (Zhejiang University, China) and Yingchun Yang (Zhejiang University, China)
- 11:00 Fri-M-V-7-4 960 Cross-Database Replay Detection in Terminal-Dependent Speaker Verification, Xingliang Cheng (Tsinghua University, China), Mingxing Xu (Tsinghua University, China) and Thomas Fang Zheng (Tsinghua University, China)
- 11:00 Fri-M-V-7-5 1281 The Effect of Silence and Dual-Band Fusion in Anti-Spoofing System, Yuxiang Zhang (CAS, China), Wenchao Wang (CAS, China) and Pengyuan Zhang (CAS, China)
- 11:00 Fri-M-V-7-6 1343 Pairing Weak with Strong: Twin Models for Defending Against Adversarial Attack on Speaker Verification, Zhiyuan Peng (CUHK, China), Xu Li (CUHK, China) and Tan Lee (CUHK, China)
- 11:00 Fri-M-V-7-7 1404 Attention-Based Convolutional Neural Network for ASV Spoofing Detection, Hefei Ling (HUST, China), Leichao Huang (HUST, China), Junrui Huang (HUST, China), Baiyan Zhang (HUST, China) and Ping Li (HUST, China)
- 11:00 Fri-M-V-7-8 1452 Voting for the Right Answer: Adversarial Defense for Speaker Verification, Haibin Wu (Tsinghua University, China), Yang Zhang (Tsinghua University, China), Zhiyong Wu (Tsinghua University, China), Dong Wang (Tsinghua University, China) and Hung-yi Lee (National Taiwan University, Taiwan)
- 11:00 Fri-M-V-7-9 1522 Visualizing Classifier Adjacency Relations: A Case Study in Speaker Verification and Voice Anti-Spoofing, Tomi Kinnunen (University of Eastern Finland, Finland), Andreas Nautsch (EURECOM, France), Md. Sahidullah (Inria, France), Nicholas Evans (EURECOM, France), Xin Wang (NII, Japan), Massimiliano Todisco (EURECOM, France), Héctor Delgado (Nuance Communications, Spain), Junichi Yamagishi (NII, Japan) and Kong Aik Lee (A*STAR, Singapore)
- 11:00 Fri-M-V-7-10 1759 Representation Learning to Classify and Detect Adversarial Attacks Against Speaker and Speech Recognition Systems, Jesús Villalba (Johns Hopkins University, USA), Sonal Joshi (Johns Hopkins University, USA), Piotr Żelasko (Johns Hopkins University, USA) and Najim Dehak (Johns Hopkins University, USA)
- 11:00 Fri-M-V-7-11 1820 An Empirical Study on Channel Effects for Synthetic Voice Spoofing Countermeasure Systems, You Zhang (University of Rochester, USA), Ge Zhu (University of Rochester, USA), Fei Jiang (University of Rochester, USA) and Zhiyao Duan (University of Rochester, USA)
- 11:00 Fri-M-V-7-12 2125 Channel-Wise Gated Res2Net: Towards Robust Detection of Synthetic Speech Attacks, Xu Li (CUHK, China), Xixin Wu (University of Cambridge, UK), Hui Lu (CUHK, China), Xunying Liu (CUHK, China) and Helen Meng (CUHK, China)
- 11:00 Fri-M-V-7-13 1187 Partially-Connected Differentiable Architecture Search for Deepfake and Spoofing Detection, Wanying Ge (EURECOM, France), Michele Panariello (EURECOM, France), Jose Patino (EURECOM, France), Massimiliano Todisco (EURECOM, France) and Nicholas Evans (EURECOM, France)
Fri-M-SS-1 Friday, September 3, 11:00-13:00 Special-Virtual: OpenASR20 and Low Resource ASR Development
- 11:00 Fri-M-SS-1-1 1930 OpenASR20: An Open Challenge for Automatic Speech Recognition of Conversational Telephone Speech in Low-Resource Languages, Kay Peterson (NIST, USA), Audrey Tong (NIST, USA) and Yan Yu (Dakota Consulting, USA)
- 11:25 Fri-M-SS-1-2 1778 Multitask Adaptation with Lattice-Free MMI for Multi-Genre Speech Recognition of Low Resource Languages, Srikanth Madikeri (Idiap Research Institute, Switzerland), Petr Motlicek (Idiap Research Institute, Switzerland) and Hervé Bourlard (Idiap Research Institute, Switzerland)
- 11:25 Fri-M-SS-1-3 67 An Improved Wav2Vec 2.0 Pre-Training Approach Using Enhanced Local Dependency Modeling for Speech Recognition, Qiu-shi Zhu (USTC, China), Jie Zhang (USTC, China), Ming-hui Wu (iFLYTEK, China), Xin Fang (USTC, China) and Li-Rong Dai (USTC, China)
- 11:25 Fri-M-SS-1-4 358 Systems for Low-Resource Speech Recognition Tasks in Open Automatic Speech Recognition and Formosa Speech Recognition Challenges, Hung-Pang Lin (National Sun Yat-sen University, Taiwan), Yu-Jia Zhang (National Sun Yat-sen University, Taiwan) and Chia-Ping Chen (National Sun Yat-sen University, Taiwan)
- 11:25 Fri-M-SS-1-5 1063 The TNT Team System Descriptions of Cantonese and Mongolian for IARPA OpenASR20, Jing Zhao (Tsinghua University, China), Zhiqiang Lv (Tencent, China), Ambyera Han (Tencent, China), Guan-Bo Wang (Tsinghua University, China), Guixin Shi (Tsinghua University, China), Jian Kang (Tencent, China), Jinghao Yan (Tencent, China), Pengfei Hu (Tencent, China), Shen Huang (Tencent, China) and Wei-Qiang Zhang (Tsinghua University, China)
- 11:25 Fri-M-SS-1-6 1086 Combining Hybrid and End-to-End Approaches for the OpenASR20 Challenge, Tanel Alumäe (Tallinn University of Technology, Estonia) and Jiaming Kong (Tallinn University of Technology, Estonia)
- 11:25 Fri-M-SS-1-7 1970 One Size Does Not Fit All in Resource-Constrained ASR, Ethan Morris (Rochester Institute of Technology, USA), Robbie Jimerson (Rochester Institute of Technology, USA) and Emily Prud’hommeaux (Boston College, USA)
Fri-A-O-1 Friday, September 3, 16:00-18:00 In-person Oral: Voice activity detection
- 16:00 Fri-A-O-1-1 309 Unsupervised Representation Learning for Speech Activity Detection in the Fearless Steps Challenge 2021, Pablo Gimeno (Universidad de Zaragoza, Spain), Alfonso Ortega (Universidad de Zaragoza, Spain), Antonio Miguel (Universidad de Zaragoza, Spain) and Eduardo Lleida (Universidad de Zaragoza, Spain)
- 16:20 Fri-A-O-1-2 651 The Application of Learnable STRF Kernels to the 2021 Fearless Steps Phase-03 SAD Challenge, Tyler Vuong (Carnegie Mellon University, USA), Yangyang Xia (Carnegie Mellon University, USA) and Richard M. Stern (Carnegie Mellon University, USA)
- 16:40 Fri-A-O-1-3 1058 Speech Activity Detection Based on Multilingual Speech Recognition System, Seyyed Saeed Sarfjoo (Idiap Research Institute, Switzerland), Srikanth Madikeri (Idiap Research Institute, Switzerland) and Petr Motlicek (Idiap Research Institute, Switzerland)
- 17:00 Fri-A-O-1-4 1234 Voice Activity Detection with Teacher-Student Domain Emulation, Jarrod Luckenbaugh (University of Texas at Dallas, USA), Samuel Abplanalp (Boston University, USA), Rachel Gonzalez (San Francisco State University, USA), Daniel Fulford (Boston University, USA), David Gard (San Francisco State University, USA) and Carlos Busso (University of Texas at Dallas, USA)
- 17:20 Fri-A-O-1-5 1456 EML Online Speech Activity Detection for the Fearless Steps Challenge Phase-III, Omid Ghahabi (EML Speech Technology, Germany) and Volker Fischer (EML Speech Technology, Germany)
Fri-A-O-2 Friday, September 3, 16:00-18:00 In-person Oral: Keyword search and spoken language processing
- 16:00 Fri-A-O-2-1 1316 Device Playback Augmentation with Echo Cancellation for Keyword Spotting, Kuba Łopatka (Intel, Poland), Katarzyna Kaszuba-Miotke (Intel, Poland), Piotr Klinke (Intel, Poland) and Paweł Trella (Intel, Poland)
- 16:20 Fri-A-O-2-2 1399 End-to-End Open Vocabulary Keyword Search, Bolaji Yusuf (Boğaziçi Üniversitesi, Turkey), Alican Gok (Boğaziçi Üniversitesi, Turkey), Batuhan Gundogdu (Boğaziçi Üniversitesi, Turkey) and Murat Saraclar (Boğaziçi Üniversitesi, Turkey)
- 16:40 Fri-A-O-2-3 1464 Semantic Sentence Similarity: Size does not Always Matter, Danny Merkx (Radboud Universiteit, The Netherlands), Stefan L. Frank (Radboud Universiteit, The Netherlands) and Mirjam Ernestus (Radboud Universiteit, The Netherlands)
- 17:00 Fri-A-O-2-4 1704 Spoken Term Detection and Relevance Score Estimation Using Dot-Product of Pronunciation Embeddings, Jan Švec (University of West Bohemia, Czech Republic), Luboš Šmídl (University of West Bohemia, Czech Republic), Josef V. Psutka (University of West Bohemia, Czech Republic) and Aleš Pražák (University of West Bohemia, Czech Republic)
- 17:20 Fri-A-O-2-5 1762 Toward Genre Adapted Closed Captioning, François Buet (LISN (UMR 9015), France) and François Yvon (LISN (UMR 9015), France)
Fri-A-V-1 Friday, September 3, 16:00-18:00 Virtual: Applications in transcription, education and learning
- 16:00 Fri-A-V-1-1 38 Weakly-Supervised Word-Level Pronunciation Error Detection in Non-Native English Speech, Daniel Korzekwa (Amazon, Poland), Jaime Lorenzo-Trueba (Amazon, UK), Thomas Drugman (Amazon, UK), Shira Calamaro (Amazon, UK) and Bozena Kostek (Gdansk University of Technology, Poland)
- 16:00 Fri-A-V-1-2 101 End-to-End Speaker-Attributed ASR with Transformer, Naoyuki Kanda (Microsoft, USA), Guoli Ye (Microsoft, USA), Yashesh Gaur (Microsoft, USA), Xiaofei Wang (Microsoft, USA), Zhong Meng (Microsoft, USA), Zhuo Chen (Microsoft, USA) and Takuya Yoshioka (Microsoft, USA)
- 16:00 Fri-A-V-1-3 691 Understanding Medical Conversations: Rich Transcription, Confidence Scores & Information Extraction, Hagen Soltau (Google, USA), Mingqiu Wang (Google, USA), Izhak Shafran (Google, USA) and Laurent El Shafey (Google, USA)
- 16:00 Fri-A-V-1-4 745 Phone-Level Pronunciation Scoring for Spanish Speakers Learning English Using a GOP-DNN System, Jazmín Vidal (UBA, Argentina), Cyntia Bonomi (UBA, Argentina), Marcelo Sancinetti (UBA, Argentina) and Luciana Ferrer (UBA-CONICET ICC, Argentina)
- 16:00 Fri-A-V-1-5 777 Explore wav2vec 2.0 for Mispronunciation Detection, Xiaoshuo Xu (Tencent, China), Yueteng Kang (Tencent, China), Songjun Cao (Tencent, China), Binghuai Lin (Tencent, China) and Long Ma (Tencent, China)
- 16:00 Fri-A-V-1-6 853 Lexical Density Analysis of Word Productions in Japanese English Using Acoustic Word Embeddings, Shintaro Ando (University of Tokyo, Japan), Nobuaki Minematsu (University of Tokyo, Japan) and Daisuke Saito (University of Tokyo, Japan)
- 16:00 Fri-A-V-1-7 931 Deep Feature Transfer Learning for Automatic Pronunciation Assessment, Binghuai Lin (Tencent, China) and Liyuan Wang (Tencent, China)
- 16:00 Fri-A-V-1-8 1258 Multilingual Speech Evaluation: Case Studies on English, Malay and Tamil, Huayun Zhang (A*STAR, Singapore), Ke Shi (A*STAR, Singapore) and Nancy F. Chen (A*STAR, Singapore)
- 16:00 Fri-A-V-1-9 1344 A Study on Fine-Tuning wav2vec2.0 Model for the Task of Mispronunciation Detection and Diagnosis, Linkai Peng (BLCU, China), Kaiqi Fu (BLCU, China), Binghuai Lin (Tencent, China), Dengfeng Ke (BLCU, China) and Jinsong Zhan (BLCU, China)
- 16:00 Fri-A-V-1-10 1402 The Impact of ASR on the Automatic Analysis of Linguistic Complexity and Sophistication in Spontaneous L2 Speech, Yu Qiao (RWTH Aachen University, Germany), Wei Zhou (RWTH Aachen University, Germany), Elma Kerz (RWTH Aachen University, Germany) and Ralf Schlüter (RWTH Aachen University, Germany)
- 16:00 Fri-A-V-1-11 1981 End-to-End Rich Transcription-Style Automatic Speech Recognition with Semi-Supervised Learning, Tomohiro Tanaka (NTT, Japan), Ryo Masumura (NTT, Japan), Mana Ihori (NTT, Japan), Akihiko Takashima (NTT, Japan), Shota Orihashi (NTT, Japan) and Naoki Makishima (NTT, Japan)
- 16:00 Fri-A-V-1-12 2140 “You don’t understand me!”: Comparing ASR Results for L1 and L2 Speakers of Swedish, Ronald Cumbal (KTH, Sweden), Birger Moell (KTH, Sweden), José Lopes (Heriot-Watt University, UK) and Olov Engwall (KTH, Sweden)
- 16:00 Fri-A-V-1-13 1571 NeMo Inverse Text Normalization: From Development to Production, Yang Zhang (NVIDIA, USA), Evelina Bakhturina (NVIDIA, USA), Kyle Gorman (CUNY Graduate Center, USA) and Boris Ginsburg (NVIDIA, USA)
- 16:00 Fri-A-V-1-14 1132 Improvement of Automatic English Pronunciation Assessment with Small Number of Utterances Using Sentence Speakability, Satsuki Naijo (Tohoku University, Japan), Akinori Ito (Tohoku University, Japan) and Takashi Nose (Tohoku University, Japan)
Fri-A-V-2 Friday, September 3, 16:00-18:00 Virtual: Emotion and Sentiment Analysis III
- 16:00 Fri-A-V-2-1 1761 Affect Recognition Through Scalogram and Multi-Resolution Cochleagram Features, Fasih Haider (University of Edinburgh, UK) and Saturnino Luz (University of Edinburgh, UK)
- 16:00 Fri-A-V-2-2 718 A Speech Emotion Recognition Framework for Better Discrimination of Confusions, Jiawang Liu (SCUT, China) and Haoxiang Wang (SCUT, China)
- 16:00 Fri-A-V-2-3 785 Speech Emotion Recognition via Multi-Level Cross-Modal Distillation, Ruichen Li (Renmin University of China, China), Jinming Zhao (Renmin University of China, China) and Qin Jin (Renmin University of China, China)
- 16:00 Fri-A-V-2-4 809 Audio-Visual Speech Emotion Recognition by Disentangling Emotion and Identity Attributes, Koichiro Ito (Hitachi, Japan), Takuya Fujioka (Hitachi, Japan), Qinghua Sun (Hitachi, Japan) and Kenji Nagamatsu (Hitachi, Japan)
- 16:00 Fri-A-V-2-5 1000 Parametric Distributions to Model Numerical Emotion Labels, Deboshree Bose (UNSW Sydney, Australia), Vidhyasaharan Sethu (UNSW Sydney, Australia) and Eliathamby Ambikairajah (UNSW Sydney, Australia)
- 16:00 Fri-A-V-2-6 1133 Metric Learning Based Feature Representation with Gated Fusion Model for Speech Emotion Recognition, Yuan Gao (Tianjin University, China), Jiaxing Liu (Tianjin University, China), Longbiao Wang (Tianjin University, China) and Jianwu Dang (Tianjin University, China)
- 16:00 Fri-A-V-2-7 1852 Speech Emotion Recognition with Multi-Task Learning, Xingyu Cai (Baidu, USA), Jiahong Yuan (Baidu, USA), Renjie Zheng (Baidu, USA), Liang Huang (Baidu, USA) and Kenneth Church (Baidu, USA)
- 16:00 Fri-A-V-2-8 1960 Generalized Dilated CNN Models for Depression Detection Using Inverted Vocal Tract Variables, Nadee Seneviratne (University of Maryland at College Park, USA) and Carol Espy-Wilson (University of Maryland at College Park, USA)
- 16:00 Fri-A-V-2-9 2004 Learning Mutual Correlation in Multimodal Transformer for Speech Emotion Recognition, Yuhua Wang (Harbin Engineering University, China), Guang Shen (Harbin Engineering University, China), Yuezhu Xu (Harbin Engineering University, China), Jiahang Li (Harbin Engineering University, China) and Zhengdao Zhao (Harbin Engineering University, China)
- 16:00 Fri-A-V-2-10 2067 Time-Frequency Representation Learning with Graph Convolutional Network for Dialogue-Level Speech Emotion Recognition, Jiaxing Liu (Tianjin University, China), Yaodong Song (Tianjin University, China), Longbiao Wang (Tianjin University, China), Jianwu Dang (Tianjin University, China) and Ruiguo Yu (Tianjin University, China)
Fri-A-V-3 Friday, September 3, 16:00-18:00 Virtual: Resource-constrained ASR
- 16:00 Fri-A-V-3-1 141 Compressing 1D Time-Channel Separable Convolutions Using Sparse Random Ternary Matrices, Gonçalo Mordido (HPI, Germany), Matthijs Van keirsbilck (NVIDIA, Germany) and Alexander Keller (NVIDIA, Germany)
- 16:00 Fri-A-V-3-2 7 Weakly Supervised Construction of ASR Systems from Massive Video Data, Mengli Cheng (Alibaba, China), Chengyu Wang (Alibaba, China), Jun Huang (Alibaba, China) and Xiaobo Wang (Alibaba, China)
- 16:00 Fri-A-V-3-3 383 Broadcasted Residual Learning for Efficient Keyword Spotting, Byeonggeun Kim (Qualcomm, Korea), Simyung Chang (Qualcomm, Korea), Jinkyu Lee (Qualcomm, Korea) and Dooyong Sung (Qualcomm, Korea)
- 16:00 Fri-A-V-3-4 797 CoDERT: Distilling Encoder Representations with Co-Learning for Transducer-Based Speech Recognition, Rupak Vignesh Swaminathan (Amazon, USA), Brian King (Amazon, USA), Grant P. Strimel (Amazon, USA), Jasha Droppo (Amazon, USA) and Athanasios Mouchtaris (Amazon, USA)
- 16:00 Fri-A-V-3-5 819 Extremely Low Footprint End-to-End ASR System for Smart Device, Zhifu Gao (Alibaba, China), Yiwu Yao (Alibaba, China), Shiliang Zhang (Alibaba, China), Jun Yang (Alibaba, China), Ming Lei (Alibaba, China) and Ian McLoughlin (SIT, Singapore)
- 16:00 Fri-A-V-3-6 1887 Dissecting User-Perceived Latency of On-Device E2E Speech Recognition, Yuan Shangguan (Facebook, USA), Rohit Prabhavalkar (Facebook, USA), Hang Su (Facebook, USA), Jay Mahadeokar (Facebook, USA), Yangyang Shi (Facebook, USA), Jiatong Zhou (Facebook, USA), Chunyang Wu (Facebook, USA), Duc Le (Facebook, USA), Ozlem Kalinli (Facebook, USA), Christian Fuegen (Facebook, USA) and Michael L. Seltzer (Facebook, USA)
- 16:00 Fri-A-V-3-7 712 Amortized Neural Networks for Low-Latency Speech Recognition, Jonathan Macoskey (Amazon, USA), Grant P. Strimel (Amazon, USA), Jinru Su (Amazon, USA) and Ariya Rastrow (Amazon, USA)
- 16:00 Fri-A-V-3-8 212 Tied & Reduced RNN-T Decoder, Rami Botros (Google, USA), Tara N. Sainath (Google, USA), Robert David (Google, USA), Emmanuel Guzman (Google, USA), Wei Li (Google, USA) and Yanzhang He (Google, USA)
- 16:00 Fri-A-V-3-9 248 PQK: Model Compression via Pruning, Quantization, and Knowledge Distillation, Jangho Kim (Qualcomm, Korea), Simyung Chang (Qualcomm, Korea) and Nojun Kwak (Seoul National University, Korea)
- 16:00 Fri-A-V-3-10 354 Collaborative Training of Acoustic Encoders for Speech Recognition, Varun Nagaraja (Facebook, USA), Yangyang Shi (Facebook, USA), Ganesh Venkatesh (Facebook, USA), Ozlem Kalinli (Facebook, USA), Michael L. Seltzer (Facebook, USA) and Vikas Chandra (Facebook, USA)
- 16:00 Fri-A-V-3-11 415 Efficient Conformer with Prob-Sparse Attention Mechanism for End-to-End Speech Recognition, Xiong Wang (Northwestern Polytechnical University, China), Sining Sun (Tencent, China), Lei Xie (Northwestern Polytechnical University, China) and Long Ma (Tencent, China)
- 16:00 Fri-A-V-3-12 456 The Energy and Carbon Footprint of Training End-to-End Speech Recognizers, Titouan Parcollet (LIA (EA 4128), France) and Mirco Ravanelli (Mila, Canada)
Fri-A-V-4 Friday, September 3, 16:00-18:00 Virtual: Speaker Recognition: Applications
- 16:00 Fri-A-V-4-1 1209 Graph-Based Label Propagation for Semi-Supervised Speaker Identification, Long Chen (Amazon, USA), Venkatesh Ravichandran (Amazon, USA) and Andreas Stolcke (Amazon, USA)
- 16:00 Fri-A-V-4-2 3 Fusion of Embeddings Networks for Robust Combination of Text Dependent and Independent Speaker Recognition, Ruirui Li (Amazon, USA), Chelsea J.-T. Ju (Amazon, USA), Zeya Chen (Amazon, USA), Hongda Mao (Amazon, USA), Oguz Elibol (Amazon, USA) and Andreas Stolcke (Amazon, USA)
- 16:00 Fri-A-V-4-3 114 A Generative Model for Duration-Dependent Score Calibration, Sandro Cumani (Politecnico di Torino, Italy) and Salvatore Sarni (Politecnico di Torino, Italy)
- 16:00 Fri-A-V-4-4 641 Dr-Vectors: Decision Residual Networks and an Improved Loss for Speaker Recognition, Jason Pelecanos (Google, USA), Quan Wang (Google, USA) and Ignacio Lopez Moreno (Google, USA)
- 16:00 Fri-A-V-4-5 681 Multi-Channel Speaker Verification for Single and Multi-Talker Speech, Saurabh Kataria (Johns Hopkins University, USA), Shi-Xiong Zhang (Tencent, USA) and Dong Yu (Tencent, USA)
- 16:00 Fri-A-V-4-6 822 Chronological Self-Training for Real-Time Speaker Diarization, Dirk Padfield (Google, USA) and Daniel J. Liebling (Google, USA)
- 16:00 Fri-A-V-4-7 1043 Adaptive Margin Circle Loss for Speaker Verification, Runqiu Xiao (CAS, China), Xiaoxiao Miao (CAS, China), Wenchao Wang (CAS, China), Pengyuan Zhang (CAS, China), Bin Cai (Guangdong PSD, China) and Liuping Luo (Guangdong PSD, China)
- 16:00 Fri-A-V-4-8 1211 Presentation Matters: Evaluating Speaker Identification Tasks, Benjamin O’Brien (LPL (UMR 7309), France), Christine Meunier (LPL (UMR 7309), France) and Alain Ghio (LPL (UMR 7309), France)
- 16:00 Fri-A-V-4-9 2021 Automatic Error Correction for Speaker Embedding Learning with Noisy Labels, Fuchuan Tong (Xiamen University, China), Yan Liu (Xiamen University, China), Song Li (Xiamen University, China), Jie Wang (Xiamen University, China), Lin Li (Xiamen University, China) and Qingyang Hong (Xiamen University, China)
- 16:00 Fri-A-V-4-10 2161 An Integrated Framework for Two-Pass Personalized Voice Trigger, Dexin Liao (Xiamen University, China), Jing Li (Xiamen University, China), Yiming Zhi (Xiamen University, China), Song Li (Xiamen University, China), Qingyang Hong (Xiamen University, China) and Lin Li (Xiamen University, China)
- 16:00 Fri-A-V-4-11 2190 Masked Proxy Loss for Text-Independent Speaker Verification, Jiachen Lian (Carnegie Mellon University, USA), Aiswarya Vinod Kumar (Carnegie Mellon University, USA), Hira Dhamyal (Carnegie Mellon University, USA), Bhiksha Raj (Carnegie Mellon University, USA) and Rita Singh (Carnegie Mellon University, USA)
Fri-A-V-5 Friday, September 3, 16:00-18:00 Virtual: Speech Synthesis: Speaking Style and Emotion
- 16:00 Fri-A-V-5-1 838 STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech, Keon Lee (KAIST, Korea), Kyumin Park (KAIST, Korea) and Daeyoung Kim (KAIST, Korea)
- 16:00 Fri-A-V-5-2 1236 Reinforcement Learning for Emotional Text-to-Speech Synthesis with Improved Emotion Discriminability, Rui Liu (SUTD, Singapore), Berrak Sisman (SUTD, Singapore) and Haizhou Li (NUS, Singapore)
- 16:00 Fri-A-V-5-3 307 Emotional Prosody Control for Speech Generation, Sarath Sivaprasad (IIIT Hyderabad, India), Saiteja Kosgi (IIIT Hyderabad, India) and Vineet Gandhi (IIIT Hyderabad, India)
- 16:00 Fri-A-V-5-4 412 Controllable Context-Aware Conversational Speech Synthesis, Jian Cong (Northwestern Polytechnical University, China), Shan Yang (Tencent, China), Na Hu (Tencent, China), Guangzhi Li (Tencent, China), Lei Xie (Northwestern Polytechnical University, China) and Dan Su (Tencent, China)
- 16:00 Fri-A-V-5-5 465 Expressive Text-to-Speech Using Style Tag, Minchan Kim (Seoul National University, Korea), Sung Jun Cheon (Seoul National University, Korea), Byoung Jin Choi (Seoul National University, Korea), Jong Jin Kim (SK Telecom, Korea) and Nam Soo Kim (Seoul National University, Korea)
- 16:00 Fri-A-V-5-6 584 Adaptive Text to Speech for Spontaneous Style, Yuzi Yan (Tsinghua University, China), Xu Tan (Microsoft, China), Bohan Li (Microsoft, China), Guangyan Zhang (CUHK, China), Tao Qin (Microsoft, China), Sheng Zhao (Microsoft, China), Yuan Shen (Tsinghua University, China), Wei-Qiang Zhang (Tsinghua University, China) and Tie-Yan Liu (Microsoft, China)
- 16:00 Fri-A-V-5-7 947 Towards Multi-Scale Style Control for Expressive Speech Synthesis, Xiang Li (Tsinghua University, China), Changhe Song (Tsinghua University, China), Jingbei Li (Tsinghua University, China), Zhiyong Wu (Tsinghua University, China), Jia Jia (Tsinghua University, China) and Helen Meng (Tsinghua University, China)
- 16:00 Fri-A-V-5-8 979 Cross-Speaker Style Transfer with Prosody Bottleneck in Neural Speech Synthesis, Shifeng Pan (Microsoft, China) and Lei He (Microsoft, China)
- 16:00 Fri-A-V-5-9 1129 Fine-Grained Style Modeling, Transfer and Prediction in Text-to-Speech Synthesis via Phone-Level Content-Style Disentanglement, Daxin Tan (CUHK, China) and Tan Lee (CUHK, China)
- 16:00 Fri-A-V-5-10 1407 Improving Performance of Seen and Unseen Speech Style Transfer in End-to-End Neural TTS, Xiaochun An (Northwestern Polytechnical University, China), Frank K. Soong (Microsoft, China) and Lei Xie (Northwestern Polytechnical University, China)
- 16:00 Fri-A-V-5-11 1446 Synthesis of Expressive Speaking Styles with Limited Training Data in a Multi-Speaker, Prosody-Controllable Sequence-to-Sequence Architecture, Slava Shechtman (IBM, Israel), Raul Fernandez (IBM, USA), Alexander Sorin (IBM, Israel) and David Haws (IBM, USA)
Fri-A-V-6 Friday, September 3, 16:00-18:00 Virtual: Spoken Language Understanding II
- 16:00 Fri-A-V-6-1 618 Intent Detection and Slot Filling for Vietnamese, Mai Hoang Dao (VinAI Research, Vietnam), Thinh Hung Truong (VinAI Research, Vietnam) and Dat Quoc Nguyen (VinAI Research, Vietnam)
- 16:00 Fri-A-V-6-2 55 Augmenting Slot Values and Contexts for Spoken Language Understanding with Pretrained Models, Haitao Lin (CAS, China), Lu Xiang (CAS, China), Yu Zhou (CAS, China), Jiajun Zhang (CAS, China) and Chengqing Zong (CAS, China)
- 16:00 Fri-A-V-6-3 335 The Impact of Intent Distribution Mismatch on Semi-Supervised Spoken Language Understanding, Judith Gaspers (Amazon, Germany), Quynh Do (Amazon, Germany), Daniil Sorokin (Amazon, Germany) and Patrick Lehnen (Amazon, Germany)
- 16:00 Fri-A-V-6-4 402 Knowledge Distillation from BERT Transformer to Speech Transformer for Intent Classification, Yidi Jiang (NUS, Singapore), Bidisha Sharma (NUS, Singapore), Maulik Madhavi (NUS, Singapore) and Haizhou Li (NUS, Singapore)
- 16:00 Fri-A-V-6-5 501 Three-Module Modeling For End-to-End Spoken Language Understanding Using Pre-Trained DNN-HMM-Based Acoustic-Phonetic Model, Nick J.C. Wang (Ping An Technology, China), Lu Wang (Ping An Technology, China), Yandan Sun (Ping An Technology, China), Haimei Kang (Ping An Technology, China) and Dejun Zhang (Ping An Technology, China)
- 16:00 Fri-A-V-6-6 788 Speak or Chat with Me: End-to-End Spoken Language Understanding System with Flexible Inputs, Sujeong Cha (NYU, USA), Wangrui Hou (NYU, USA), Hyun Jung (NYU, USA), My Phung (NYU, USA), Michael Picheny (NYU, USA), Hong-Kwang J. Kuo (IBM, USA), Samuel Thomas (IBM, USA) and Edmilson Morais (IBM, Brazil)
- 16:00 Fri-A-V-6-7 818 End-to-End Cross-Lingual Spoken Language Understanding Model with Multilingual Pretraining, Xianwei Zhang (Tsinghua University, China) and Liang He (Tsinghua University, China)
- 16:00 Fri-A-V-6-8 1816 Factorization-Aware Training of Transformers for Natural Language Understanding on the Edge, Hamidreza Saghir (Amazon, Canada), Samridhi Choudhary (Amazon, Canada), Sepehr Eghbali (Amazon, Canada) and Clement Chung (Amazon, Canada)
- 16:00 Fri-A-V-6-9 1826 End-to-End Spoken Language Understanding for Generalized Voice Assistants, Michael Saxon (Amazon, USA), Samridhi Choudhary (Amazon, USA), Joseph P. McKenna (Amazon, USA) and Athanasios Mouchtaris (Amazon, USA)
- 16:00 Fri-A-V-6-10 2044 Bi-Directional Joint Neural Networks for Intent Classification and Slot Filling, Soyeon Caren Han (University of Sydney, Australia), Siqu Long (University of Sydney, Australia), Huichun Li (University of Sydney, Australia), Henry Weld (University of Sydney, Australia) and Josiah Poon (University of Sydney, Australia)
Fri-A-SS-1 Friday, September 3, 16:00-18:00 Special-Virtual: INTERSPEECH 2021 Acoustic Echo Cancellation Challenge
- 16:00 Fri-A-SS-1-1 1870 INTERSPEECH 2021 Acoustic Echo Cancellation Challenge, Ross Cutler (Microsoft, USA), Ando Saabas (Microsoft, USA), Tanel Parnamaa (Microsoft, USA), Markus Loide (Microsoft, USA), Sten Sootla (Microsoft, USA), Marju Purin (Microsoft, USA), Hannes Gamper (Microsoft, USA), Sebastian Braun (Microsoft, USA), Karsten Sorensen (Microsoft, USA), Robert Aichner (Microsoft, USA) and Sriram Srinivasan (Microsoft, USA)
- 16:20 Fri-A-SS-1-2 85 Acoustic Echo Cancellation with Cross-Domain Learning, Lukas Pfeifenberger (Evolve, Austria), Matthias Zoehrer (Evolve, Austria) and Franz Pernkopf (Technische Universität Graz, Austria)
- 16:40 Fri-A-SS-1-3 1359 F-T-LSTM Based Complex Network for Joint Acoustic Echo Cancellation and Speech Enhancement, Shimin Zhang (Northwestern Polytechnical University, China), Yuxiang Kong (Northwestern Polytechnical University, China), Shubo Lv (Northwestern Polytechnical University, China), Yanxin Hu (Northwestern Polytechnical University, China) and Lei Xie (Northwestern Polytechnical University, China)
- 17:00 Fri-A-SS-1-4 1590 Y²-Net FCRN for Acoustic Echo and Noise Suppression, Ernst Seidel (Technische Universität Braunschweig, Germany), Jan Franzen (Technische Universität Braunschweig, Germany), Maximilian Strake (Technische Universität Braunschweig, Germany) and Tim Fingscheidt (Technische Universität Braunschweig, Germany)
- 17:20 Fri-A-SS-1-5 2022 Acoustic Echo Cancellation Using Deep Complex Neural Network with Nonlinear Magnitude Compression and Phase Information, Renhua Peng (CAS, China), Linjuan Cheng (CAS, China), Chengshi Zheng (CAS, China) and Xiaodong Li (CAS, China)
- 17:40 Fri-A-SS-1-6 722 Nonlinear Acoustic Echo Cancellation with Deep Learning, Amir Ivry (Technion, Israel), Israel Cohen (Technion, Israel) and Baruch Berdugo (Technion, Israel)
Fri-A-SS-2 Friday, September 3, 16:00-18:00 Special-Virtual: Speech Recognition of Atypical Speech
- 16:00 Introduction
- 16:05 Short presentations of papers
- 16:25 Fri-A-SS-2-1 1384 Automatic Speech Recognition of Disordered Speech: Personalized Models Outperforming Human Listeners on Short Phrases, Jordan R. Green (MGH Institute of Health Professions, USA), Robert L. MacDonald (Google, USA), Pan-Pan Jiang (Google, USA), Julie Cattiau (Google, USA), Rus Heywood (Google, USA), Richard Cave (MND Association, UK), Katie Seaver (MGH Institute of Health Professions, USA), Marilyn A. Ladewig (Cerebral Palsy Associations of New York State, USA), Jimmy Tobin (Google, USA), Michael P. Brenner (Google, USA), Philip C. Nelson (Google, USA) and Katrin Tomanek (Google, USA)
- 16:25 Fri-A-SS-2-2 1801 Investigating the Utility of Multimodal Conversational Technology and Audiovisual Analytic Measures for the Assessment and Monitoring of Amyotrophic Lateral Sclerosis at Scale, Michael Neumann (Modality.AI, USA), Oliver Roesler (Modality.AI, USA), Jackson Liscombe (Modality.AI, USA), Hardik Kothare (Modality.AI, USA), David Suendermann-Oeft (Modality.AI, USA), David Pautler (Modality.AI, USA), Indu Navar (Peter Cohen Foundation, USA), Aria Anvar (Peter Cohen Foundation, USA), Jochen Kumm (Pr3vent, USA), Raquel Norel (IBM, USA), Ernest Fraenkel (MIT, USA), Alexander V. Sherman (MGH Institute of Health Professions, USA), James D. Berry (MGH Institute of Health Professions, USA), Gary L. Pattee (University of Nebraska, USA), Jun Wang (University of Texas at Austin, USA), Jordan R. Green (MGH Institute of Health Professions, USA) and Vikram Ramanarayanan (Modality.AI, USA)
- 16:25 Fri-A-SS-2-3 2212 Handling Acoustic Variation in Dysarthric Speech Recognition Systems Through Model Combination, Enno Hermann (Idiap Research Institute, Switzerland) and Mathew Magimai-Doss (Idiap Research Institute, Switzerland)
- 16:25 Fri-A-SS-2-4 60 Spectro-Temporal Deep Features for Disordered Speech Assessment and Recognition, Mengzhe Geng (CUHK, China), Shansong Liu (CUHK, China), Jianwei Yu (CUHK, China), Xurong Xie (CAS, China), Shoukang Hu (CUHK, China), Zi Ye (CUHK, China), Zengrui Jin (CUHK, China), Xunying Liu (CUHK, China) and Helen Meng (CUHK, China)
- 16:25 Fri-A-SS-2-5 99 Speaking with a KN95 Face Mask: ASR Performance and Speaker Compensation, Sarah E. Gutz (Harvard University, USA), Hannah P. Rowe (MGH Institute of Health Professions, USA) and Jordan R. Green (Harvard University, USA)
- 16:25 Fri-A-SS-2-6 168 Adversarial Data Augmentation for Disordered Speech Recognition, Zengrui Jin (CUHK, China), Mengzhe Geng (CUHK, China), Xurong Xie (CAS, China), Jianwei Yu (CUHK, China), Shansong Liu (CUHK, China), Xunying Liu (CUHK, China) and Helen Meng (CUHK, China)
- 16:25 Fri-A-SS-2-7 173 Variational Auto-Encoder Based Variability Encoding for Dysarthric Speech Recognition, Xurong Xie (CAS, China), Rukiye Ruzi (CAS, China), Xunying Liu (CUHK, China) and Lan Wang (CAS, China)
- 16:25 Fri-A-SS-2-8 285 Learning Explicit Prosody Models and Deep Speaker Embeddings for Atypical Voice Conversion, Disong Wang (CUHK, China), Songxiang Liu (CUHK, China), Lifa Sun (SpeechX, China), Xixin Wu (University of Cambridge, UK), Xunying Liu (CUHK, China) and Helen Meng (CUHK, China)
- 16:25 Fri-A-SS-2-9 289 Bayesian Parametric and Architectural Domain Adaptation of LF-MMI Trained TDNNs for Elderly and Dysarthric Speech Recognition, Jiajun Deng (CUHK, China), Fabian Ritter Gutierrez (CUHK, China), Shoukang Hu (CUHK, China), Mengzhe Geng (CUHK, China), Xurong Xie (CAS, China), Zi Ye (CUHK, China), Shansong Liu (CUHK, China), Jianwei Yu (CUHK, China), Xunying Liu (CUHK, China) and Helen Meng (CUHK, China)
- 16:25 Fri-A-SS-2-10 330 A Voice-Activated Switch for Persons with Motor and Speech Impairments: Isolated-Vowel Spotting Using Neural Networks, Shanqing Cai (Google, USA), Lisie Lillianfeld (Google, USA), Katie Seaver (Google, USA), Jordan R. Green (Google, USA), Michael P. Brenner (Google, USA), Philip C. Nelson (Google, USA) and D. Sculley (Google, USA)
- 16:25 Fri-A-SS-2-11 676 Conformer Parrotron: A Faster and Stronger End-to-End Speech Conversion and Recognition Model for Atypical Speech, Zhehuai Chen (Google, USA), Bhuvana Ramabhadran (Google, USA), Fadi Biadsy (Google, USA), Xia Zhang (Google, USA), Youzheng Chen (Google, USA), Liyang Jiang (Google, USA), Fang Chu (Google, USA), Rohan Doshi (Google, USA) and Pedro J. Moreno (Google, USA)
- 16:25 Fri-A-SS-2-12 697 Disordered Speech Data Collection: Lessons Learned at 1 Million Utterances from Project Euphonia, Robert L. MacDonald (Google, USA), Pan-Pan Jiang (Google, USA), Julie Cattiau (Google, USA), Rus Heywood (Google, USA), Richard Cave (MND Association, UK), Katie Seaver (MGH Institute of Health Professions, USA), Marilyn A. Ladewig (Cerebral Palsy Associations of New York State, USA), Jimmy Tobin (Google, USA), Michael P. Brenner (Google, USA), Philip C. Nelson (Google, USA), Jordan R. Green (MGH Institute of Health Professions, USA) and Katrin Tomanek (Google, USA)
- 16:25 Fri-A-SS-2-13 1353 Automatic Severity Classification of Korean Dysarthric Speech Using Phoneme-Level Pronunciation Features, Eun Jung Yeo (Seoul National University, Korea), Sunhee Kim (Seoul National University, Korea) and Minhwa Chung (Seoul National University, Korea)
- 16:25 Fri-A-SS-2-14 1913 Comparing Supervised Models and Learned Speech Representations for Classifying Intelligibility of Disordered Speech on Selected Phrases, Subhashini Venugopalan (Google, USA), Joel Shor (Google, Japan), Manoj Plakal (Google, USA), Jimmy Tobin (Google, USA), Katrin Tomanek (Google, USA), Jordan R. Green (MGH Institute of Health Professions, USA) and Michael P. Brenner (Google, USA)
- 16:25 Fri-A-SS-2-15 2006 Analysis and Tuning of a Voice Assistant System for Dysfluent Speech, Vikramjit Mitra (Apple, USA), Zifang Huang (Apple, USA), Colin Lea (Apple, USA), Lauren Tooley (Apple, USA), Sarah Wu (Apple, USA), Darren Botten (Apple, USA), Ashwini Palekar (Apple, USA), Shrinath Thelapurath (Apple, USA), Panayiotis Georgiou (Apple, USA), Sachin Kajarekar (Apple, USA) and Jefferey Bigham (Apple, USA)
- 17:35 Group discussion
Fri-A-S&T-1 Friday, September 3, 16:00-18:00 Show and Tell: Show and Tell 4
- 16:00 Fri-A-S&T-1-1 ST21 Interactive and Real-Time Acoustic Measurement Tools for Speech Data Acquisition and Presentation: Application of an Extended Member of Time Stretched Pulses, Hideki Kawahara (Wakayama University, Japan), Kohei Yatabe (Waseda University, Japan), Ken-Ichi Sakakibara (HSUH, Japan), Mitsunori Mizumachi (Kyutech, Japan), Masanori Morise (Meiji University, Japan), Hideki Banno (Meijo University, Japan) and Toshio Irino (Wakayama University, Japan)
- 16:00 Fri-A-S&T-1-2 ST23 Save Your Voice: Voice Banking and TTS for Anyone, Daniel Tihelka (University of West Bohemia, Czech Republic), Markéta Řezáčková (University of West Bohemia, Czech Republic), Martin Grůber (University of West Bohemia, Czech Republic), Zdeněk Hanzlíček (University of West Bohemia, Czech Republic), Jakub Vít (University of West Bohemia, Czech Republic) and Jindřich Matoušek (University of West Bohemia, Czech Republic)
- 16:00 Fri-A-S&T-1-3 ST24 NeMo (Inverse) Text Normalization: From Development to Production, Yang Zhang (NVIDIA, USA), Evelina Bakhturina (NVIDIA, USA) and Boris Ginsburg (NVIDIA, USA)
- 16:00 Fri-A-S&T-1-4 ST25 Lalilo: A Reading Assistant for Children Featuring Speech Recognition-Based Reading Mistake Detection, Corentin Hembise (Lalilo, France), Lucile Gelin (Lalilo, France) and Morgane Daniel (Lalilo, France)
- 16:00 Fri-A-S&T-1-5 ST26 Automatic Radiology Report Editing Through Voice, Manh Hung Nguyen (VinBrain, Vietnam), Vu Hoang (VinBrain, Vietnam), Tu Anh Nguyen (VinBrain, Vietnam) and Trung H. Bui (Independent Researcher, USA)
- 16:00 Fri-A-S&T-1-6 ST28 WittyKiddy: Multilingual Spoken Language Learning for Kids, Ke Shi (A*STAR, Singapore), Kye Min Tan (A*STAR, Singapore), Huayun Zhang (A*STAR, Singapore), Siti Umairah Md. Salleh (A*STAR, Singapore), Shikang Ni (A*STAR, Singapore) and Nancy F. Chen (A*STAR, Singapore)
- 16:00 Fri-A-S&T-1-7 ST32 Duplex Conversation in Outbound Agent System, Chunxiang Jin (Ant, China), Minghui Yang (Ant, China) and Zujie Wen (Ant, China)
- 16:00 Fri-A-S&T-1-8 ST33 Web Interface for Estimating Articulatory Movements in Speech Production from Acoustics and Text, Sathvik Udupa (Indian Institute of Science, India), Anwesha Roy (Indian Institute of Science, India), Abhayjeet Singh (Indian Institute of Science, India), Aravind Illa (Indian Institute of Science, India) and Prasanta Kumar Ghosh (Indian Institute of Science, India)